前言:
常见的关于HahsMap与ConcurrentHashMap的问题:
数据结构、线程安全、扩容、jdk1.7 HashMap死循环、jdk1.8 HashMap红黑树、容量必须是2的冥次
HashMap
数据结构:数组,单向链表
线程安全:不安全,HashTable线程安全,但是全用了 synchronized ,性能低
一、jdk1.7中
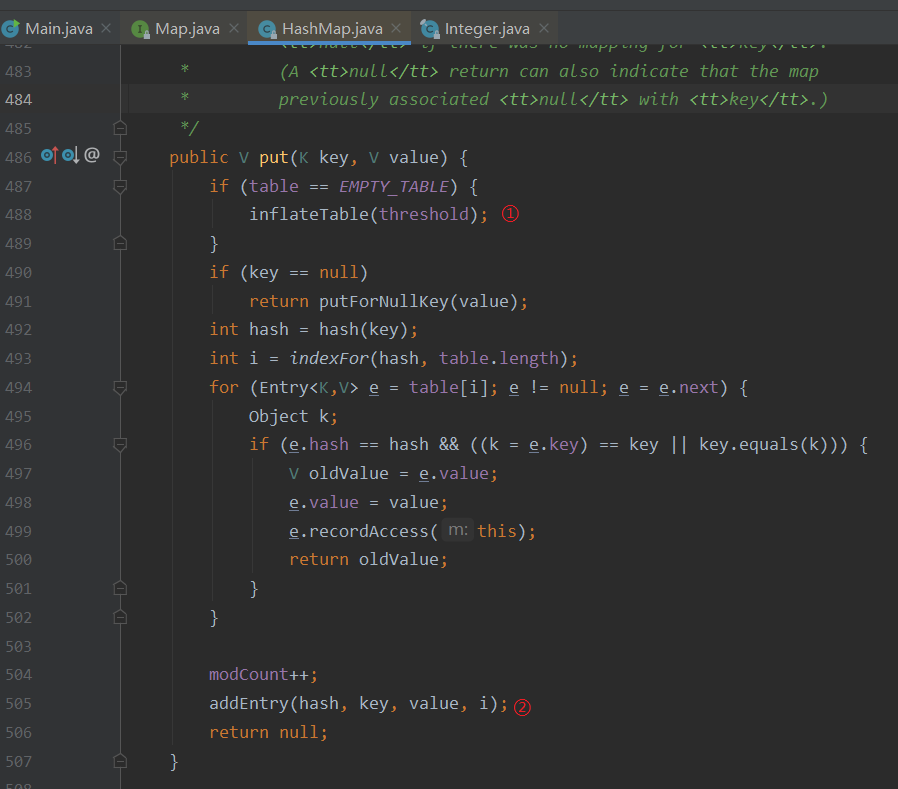
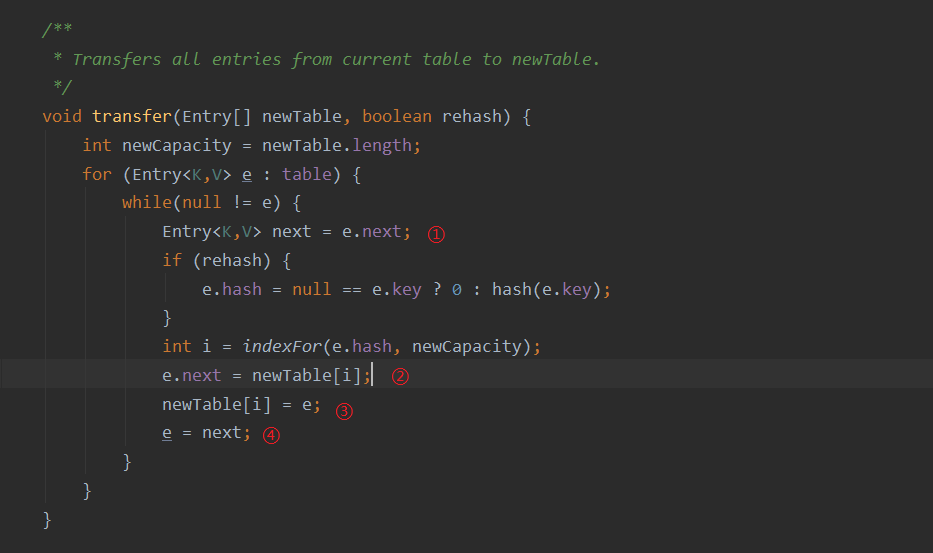
①:对HashMap初始化进行初始化;
初始化HashMap的 threshold 字段,通过因子算出,默认为0.75,算出来是16 * 0.75为12;
初始化hash种子信息;
保证了HashMap的容量是2的冥次。为什么HashMap的容量必须是2的冥次,因为可以增加有效长度,减少hash碰撞,关于hash碰撞:https://blog.csdn.net/qq_35583089/article/details/80048285
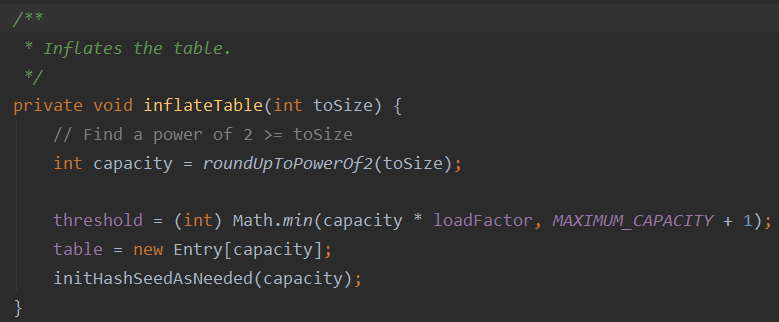
②:添加Entry对象,赋值
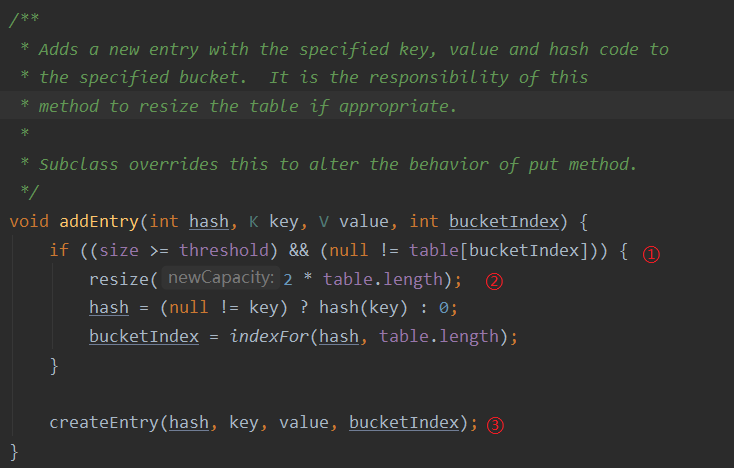
①:判断当前容量是否到达阈值,例如12
②:扩容
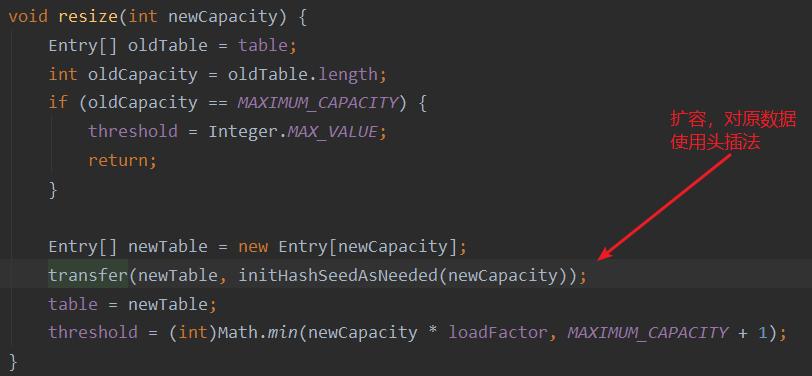
头插法:原先的头会成为新链表的尾部,原先的尾部会成为新链表的头
这里的代码就是为什么不建议并发时使用HashMap的原因,e.next形成死循环,导致CPU 100%卡死,并且线程不安全
二、jdk1.8中
jdk1.8中,当容量超过2的8次方(64)时,使用红黑树替代链表
ConcurrentHashMap
数据结构(jdk1.7):Segment数组,Segment下又有HashEntry,HashEntry为数组+链表
数据结构(jdk1.8):但是在jdk1.8中,起始的数据结构是数组+链表的。但是当单个链表长度
ConcurrentHashMap是一个线程安全的Map类,其通过多个Segment来保存数据,操作不同Segment之间是可以并发的,而操作统计个Segment进行数据的插入时,会进行 ReentrantLock 上锁操作
一、jdk1.7
先看看put方法
public V put(K key, V value) { ConcurrentHashMap.Segment<K,V> s; if (value == null) throw new NullPointerException();
//通过key的hash值算出segment的下标 int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (ConcurrentHashMap.Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment //这里会判断对应下标的segment是否存在,不存在会进行初始化
s = ensureSegment(j); return s.put(key, hash, value, false); }
下面是Segment.put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试获得锁,并开始同步 ConcurrentHashMap.HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { ConcurrentHashMap.HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; ConcurrentHashMap.HashEntry<K,V> first = entryAt(tab, index); for (ConcurrentHashMap.HashEntry<K,V> e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else {
//和HashMap一样,链表使用头插法,后插入的元素永远在数组的最前面 if (node != null) node.setNext(first); else node = new ConcurrentHashMap.HashEntry<K,V>(hash, key, value, first); int c = count + 1;
//超过Segment阈值时,对HashEntry进行扩容 if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; }
二、jdk1.8
java1.7采用volatile去获取已存在的Segment。java1.8采用的CAS算法,而没用使用Segment进行数据存储