先了解知识图谱的定义:
知识图谱,即Knowledge Graph,在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识以及它们之间的相互联系。
了解一下推荐系统
我们每个人每天都会使用多个APP中的推荐功能,这些功能的背后都是个性化推荐系统(personalized recommender systems)。随着互联网技术和产业的迅速发展,接入互联网的服务器数量和网页数量也呈指数级上升。用户面临着海量的信息,传统的搜索算法只能呈现给用户相同的物品(item)排序结果。无法针对不同用户的兴趣爱好提供相应的服务。信息爆炸使得信息的利用率反而降低,这种现象被称为信息超载(information overload)。
推荐问题从本质上说就是代替用户评估其从未看过、接触过和使用过的物品,包括书籍、电影、新闻等。推荐系统作为一种信息过滤的重要手段,是当前解决信息超载问题的最有效的方法之一,是面向用户的互联网产品的核心技术。
按照预测对象的不同,推荐系统一般可以分为两类:一类是评分预测(rating prediction),例如在电影应用中,系统需要预测用户对电影的评分,并以此为根据推送其可能喜欢的电影。这种场景下的用户反馈信息表达了用户的喜好程度,因此这种信息也称为显式反馈(explicit feedback);另一类是点击率预测,例如在新闻类应用中,系统需要预测用户点击某新闻的概率来优化方案。这种场景下的用户反馈信息只能表达用户的行为特征(点击/未点击),而不能反映用户的喜爱程度,因此这种信息也叫隐式反馈(implicit feedback)。

传统的推荐系统只使用用户和物品的历史交互信息(显式或隐式反馈)作为输入,这会带来两个问题:一,在实际场景中,用户和物品的交互信息往往是非常稀疏(sparse)的。例如,一个电影类APP可能包含了上万部电影,而一个用户打过分的电影可能平均只有几十部。使用如此少量的已观测数据来预测大量的未知信息,会极大地增加算法的过拟合(overfitting)风险;二,对于新加入的用户或者物品,由于系统没有其历史交互信息,因此无法进行准确地建模和推荐,这种情况也叫做冷启动问题(cold start problem)。
解决这两个问题的一个常见的思路是在推荐算法中额外引入一些辅助信息(side information)作为输入。辅助信息可以丰富对用户和物品的描述、增强推荐算法的挖掘能力,从而有效地弥补交互信息的稀疏或缺失。常见的辅助信息包括:
- 社交网络(social networks):一个用户对某个物品感兴趣,他的朋友可能也会对该物品感兴趣;
- 用户/物品属性(attributes):拥有同种属性的用户可能会对同一类物品感兴趣;
- 图像/视频/音频/文本等多媒体信息(multimedia):例如商品图片、电影预告片、音乐、新闻标题等;
- 上下文(context):用户-物品交互的时间、地点、当前会话信息等。
如何根据具体推荐场景的特点将各种辅助信息有效地融入推荐算法一直是推荐系统研究领域的热点和难点,如何从各种辅助信息中提取有效的特征也是推荐系统工程领域的核心问题。
知识图谱
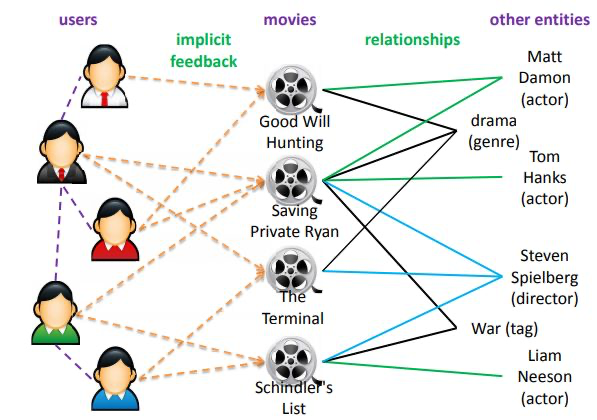
在各种辅助信息中,知识图谱作为一种新兴类型的辅助信息近几年逐渐引起了研究人员的关注。知识图谱(knowledge graph)是一种语义网络,其结点(node)代表实体(entity)或者概念(concept),边(edge)代表实体/概念之间的各种语义关系(relation)。一个知识图谱由若干三元组(h、r、t)组成,其中h和t代表一条关系的头结点和尾结点,r代表关系。
知识图谱包含了实体之间丰富的语义关联,为推荐系统提供了潜在的辅助信息来源。知识图谱在诸多场景中都有应用的潜力,例如电影、新闻、景点等。和其它种类的辅助信息相比,知识图谱的引入可以让推荐结果更加具有以下特征:
- 精确性(precision)。知识图谱为物品引入了更多的语义关系,可以深层次地发现用户兴趣;

- 多样性(diversity)。知识图谱提供了不同的关系连接种类,有利于推荐结果的发散,避免推荐结果局限于单一类型;

- 可解释性(explainability)。知识图谱可以连接用户的历史记录和推荐结果,从而提高用户对推荐结果的满意度和接受度,增强用户对推荐系统的信任。

这里值得一提的是知识图谱和物品属性的区别。物品属性可以看成是在知识图谱中和某件物品直接相连的(1-hop)的节点,即一个弱化版本的知识图谱。事实上,一个完整的知识图谱可以提供物品之间更深层次和更长范围内的关联,例如,“《霸王别姬》-张国荣-香港-梁朝伟-《无间道》”。正因为知识图谱的维度更高,语义关系更丰富,它的处理也因此比物品属性更加复杂和困难。
一般来说,现有的可以将知识图谱引入推荐系统的工作分为两类:
- 以LibFM[1]为代表的通用的基于特征的推荐方法(generic-feature-based methods)。这类方法统一地把用户和物品的属性作为推荐算法的输入。例如,LibFM将某个用户和某个物品的所有属性记为x,然后令该用户和物品之间的交互强度y(x)依赖于属性中的所有的一次项和二次项。

基于该类方法的通用性,我们可以将知识图谱弱化为物品属性,然后应用该类方法即可。当然,这种做法的缺点也显而易见:它并非专门针对知识图谱设计,因此无法高效地利用知识图谱的全部信息。例如,该类方法难以利用多跳的知识,也难以引入关系(relation)的信息。
- 以PER[2]、MetaGraph[3]为代表的基于路径的推荐方法。该类方法将知识图谱视为一个异构信息网络,然后构造物品之间的基于meta-path或meta-graph的特征。简单地说,meta-path是连接两个实体的一条的路径,比如“演员->电影->导演->演员”这条meta-path可以连接两个演员,因此可以视为一种挖掘演员之间的潜在关系的方式。这类方法的优点是充分且直观地利用了知识图谱的网络结构,缺点是需要手动设计meta-path或meta-graph,这在实践中难以达到最优;同时,该类方法无法在实体不属于同一个领域的场景(例如新闻推荐)中应用,因为我们无法为这样的场景预定义meta-path或mata-graph。
知识图谱特征学习
知识图谱特征学习(Knowledge Graph Embedding)为知识图谱中的每个实体和关系学习得到一个低围向量,同时保持图中原有的结构或语义信息。事实上,知识图谱特征学习是网络特征学习的一个子领域,因为知识图谱包含特有的语义信息,所以知识图谱特征学习比通用的网络特征学习需要更细心和针对性的模型设计。一般而言,知识图谱特征学习的模型分为两类: