上一个实验中,我们已经设计并实现了基于经典5级流水线结构的微处理器,该流水线结构是理想化的,只有流水线的基本功能,其中运行的指令是彼此独立的,互无联系的。这样的流水线是无法完成大多数程序的运行需要的,因为任何一个程序,各个指令之间一定是彼此相关的。
为了使流水线更具实用性,本章将重点讨论流水线中最常见的“相关”问题和暂停机制。首先我们给出流水线相关问题的基本概念;然后介绍流水线的数据相关及基于定向前推的消除方法,并给出支持定向前推的微处理器流水线的设计方案和Verilog实现;接着,介绍由转移类指令引起的流水线的控制相关及基于延迟转移的消除方法,并给出支持转移类指令的微处理器流水线的设计方案和Verilog实现;最后我们研究流水线的暂停机制,并给出相应的流水线设计方案和Verilog实现。
相关问题&暂停机制
相关问题的概念->基于定向前推的消除方法->转移类指令引起的流水线控制相关->基于延迟转移的消除方法->流水线的暂停机制&相应的流水线设计方案
6.1 流水线的数据相关和消除方法
在实际流水线运行的过程中,简单的流水线无法满足大多数程序运行的要求,最常见的问题是“相关(也称为冲突、冒险或依赖)”问题。
所谓“相关”是指在一段程序的邻近指令之间存在某种关系,这种关系造成流水线中的某些指令无法在指定的时钟周期被执行,从而影响指令在时间上的重叠执行,造成流水线吞吐率和加速比的下降,制约流水线性能。
流水线包括三种相关:结构相关,数据相关,控制相关。
结构相关
结构相关是指流水线中多条指令在同一时钟周期中争用同一个功能部件,从而发生冲突,造成指令无法继续执行。消除结构相关的常见方法是设置多个功能部件。目前,MiniMIPS32微处理器的流水线设计正是采用这种分离式的指令存储器和数据存储器。
数据相关
数据相关是指流水线中,如果某一条指令必须等前面指令的运行结果,才能继续执行,那么指令间就存在数据相关。此处的数据仅考虑寄存器中的数据。数据相关又可以分为三种,假设指令i先于指令j进入流水线:
- 写后读相关(RAW):指令j需要指令i的计算结果,但在流水线中,j可能在i写入结果前对保存该结果的寄存器进行读操作,从而读取错误的数据。
- 读后写相关(WAR):指令j在指令i读取某个寄存器之前对该寄存器进行了写操作,导致指令i读取了新的已经进行了写操作的数据,从而发生错误。
- 写后写相关(WAW):指令i和j对相同的寄存器进行写操作,如果在流水线中,指令j先于指令i完成了对寄存器的写操作,从而导致最终存放的是指令i的结果,而不是j的结果,从而发生写入顺序的错误。
由于MiniMIPS32是顺序处理器,即指令顺序进入流水线,并顺序提交结果,并且只在写回阶段才会进行寄存器写操作,WAW这种数据相关是不存在的。又因为只能在流水线的写回节点写寄存器,故也不存在WAR相关。因此只存在RAW相关。MiniMIPS32有两种寄存器,一种是通用寄存器,另一种是HILO寄存器,两种都可能存在数据相关。
对通用寄存器的读取发生在译码阶段,根据相关指令出现的位置不同,RAW相关又可以分为3种情况:译码-执行相关,译码-访存相关和译码-写回相关。
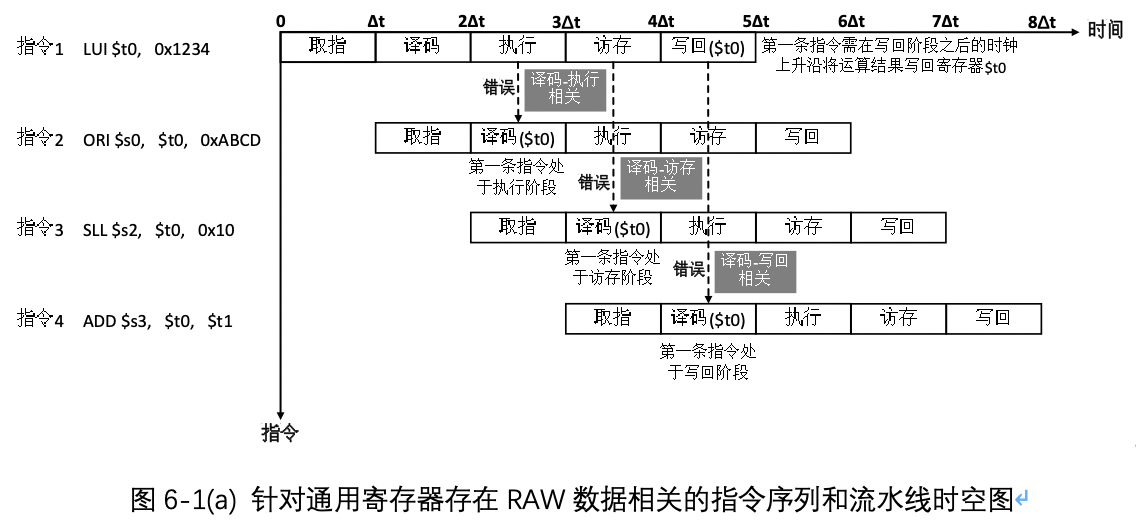
- 译码-执行相关:指相邻两条指令之间针对某一通用寄存器存在RAW数据相关,即图6-1(a)中的指令1和指令2。指令2的计算需要指令1将结果存回寄存器$t0。指令1只能在写回阶段将结果写入$t0,而指令2在译码阶段需要读取寄存器$t0中的数据,此时指令1还处于执行阶段,故指令2从$1中读取的数据必然不是指令1的计算结果,故发生错误。
- 译码-访存相关:指相隔一条指令的两条指令间针对某一通用寄存器存在RAW数据相关,即图6-1(a)中的指令1和指令3。指令3的计算需要指令1将结果写回寄存器$t0。当指令3在译码阶段读取寄存器$t0中的数据时,指令1还处在流水线的访存阶段,若使用这个数据,则指令3的运行结果必然不正确。
-
译码-写回相关:指相邻两条指令之间针对某一通用寄存器存在RAW数据相关,即图6-1(a)中的指令1和指令4。指令4的计算需要指令1将结果写回寄存器$t0。当指令4在译码阶段读取寄存器$t0时,指令1还处在流水线的写回阶段,而指令1需要在写回阶段最后的时钟上升沿才能将结果写入$t0,所以指令4此时得到的寄存器$t0的值是错误的。
对HILO寄存器的读取发生在执行阶段,根据相关指令出现位置的不同,分为两种:执行-访存相关和执行-写回相关。
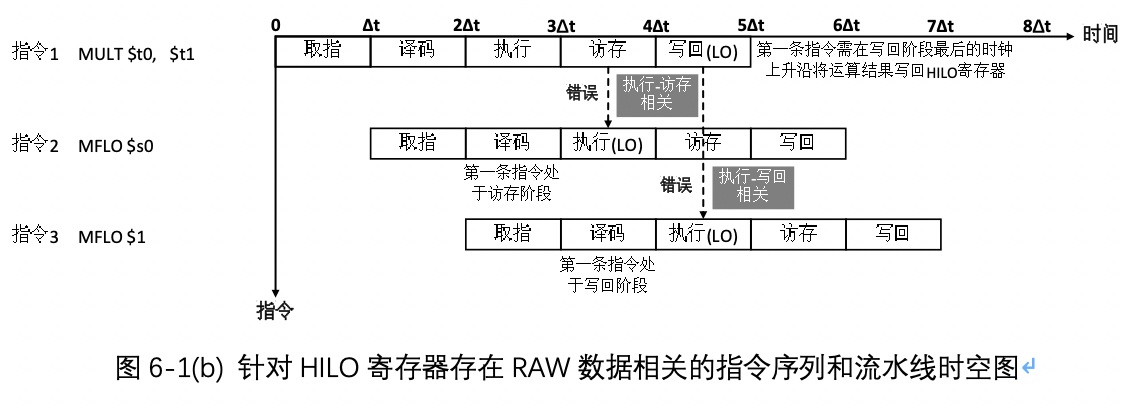
- 执行-访存相关:指相邻两条指令之间针对HILO寄存器存在RAW数据相关,即图6-1(b)中的指令1和指令2。指令1只能在写回阶段将结果写入HILO寄存器,而指令2需要在执行阶段访问LO寄存器,此时指令1还处于访存阶段,故指令2从寄存器LO中读取的数据必然不是指令1的计算结果,因此,发生错误。
- 执行-写回相关:指相隔一条指令的指令间针对HILO寄存器存在RAW相关,即图6-1(b)中的指令1和指令3。指令3的计算需要指令1将结果写回寄存器HILO。当指令3在执行阶段读取寄存器LO时,指令1还处在流水线的写回阶段,而指令1需要在写回阶段最后的时钟上升沿才能将结果写入LO,所以指令3此时得到的寄存器LO的值是错误的。
6.1.2 数据相关的消除方法
为了消除由数据相关导致的执行不正确的问题,采用以下三种方法。
1. 插入暂停周期
为了保证存在数据相关的指令在流水线中正确执行,设置一个“流水线互锁机制”的功能部件,该部件将检测并发现流水线中存在的数据相关,并推迟当前指令的执行,直到所需的数据被写回相关的寄存器才继续指令的执行。推迟指令的执行通过在流水线中插入若干暂停周期(也称为“气泡”)实现,相当于在相关指令之间增加若干个空指令(NOP)。
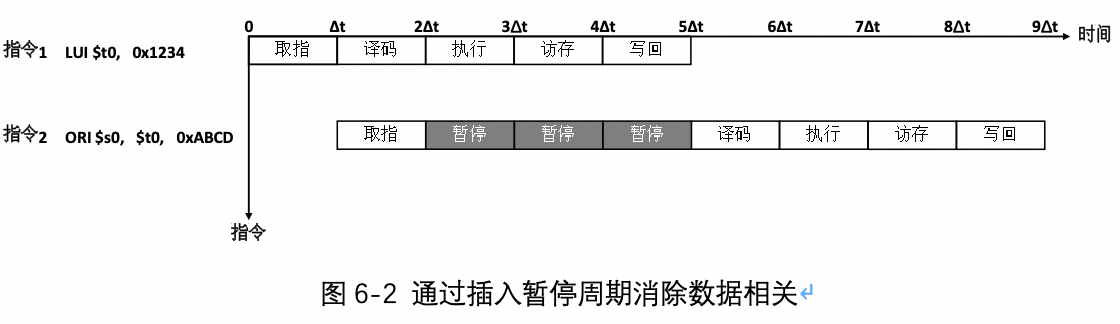
由图可见,指令2在流水线中的运行被暂停了3个时钟周期,然后再进行译码时取出的寄存器$t0的值是指令1写回的计算结果,故指令执行的正确性得到了保证。但该方法会造成流水线的停顿,降低了流水线的运行效率,最终增加了处理器的CPI,严重制约了处理器的性能。
2. 依靠编译器调度
为了减少流水线的停顿,可以依靠编译器在编译时重新组织指令的顺序来消除数据相关,这种技术称为“指令调度”,如下图所示:
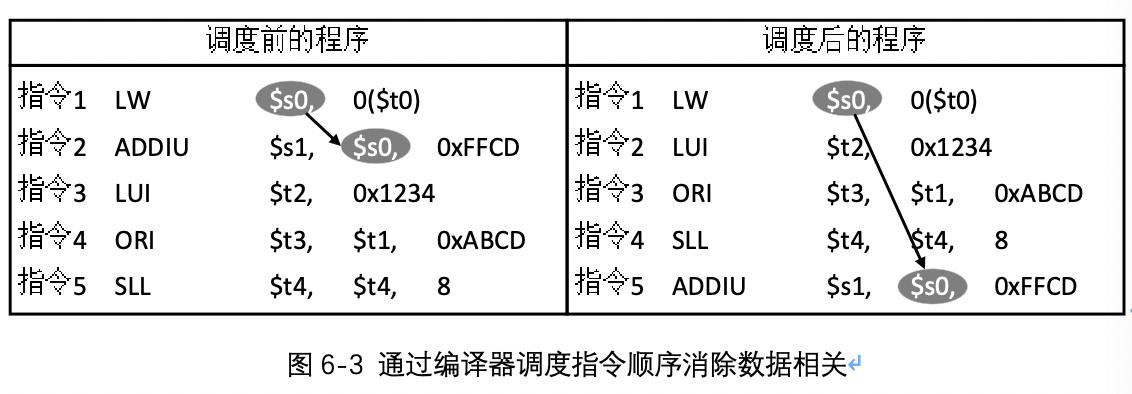
对于调度前的程序,指令1和指令2之前对于寄存器$s0存在译码-执行相关。经过编译器调度之后,将后面的三条无关指令调度到LW和ADDIU之间,这样不仅消除了原有的数据相关性,同时不会造成流水线的停顿。但该方法仍然存在两个问题:第一,需要对编译器进行特别设计,增加了其设计难度;第二,并不是每次出现数据相关时,都可以找到无关指令进行调度,此时还是需要在相关指令间插入暂停周期。
3. 数据定向前推
为了不造成流水线的停顿,同时也不对编译器进行改动,可采用称为定向前推的方法消除数据相关。这种方法在流水线中设置专用的数据通路,将相关的数据从其产生处直接送到所有需要它的功能部件,而不必等待数据写回通用寄存器。
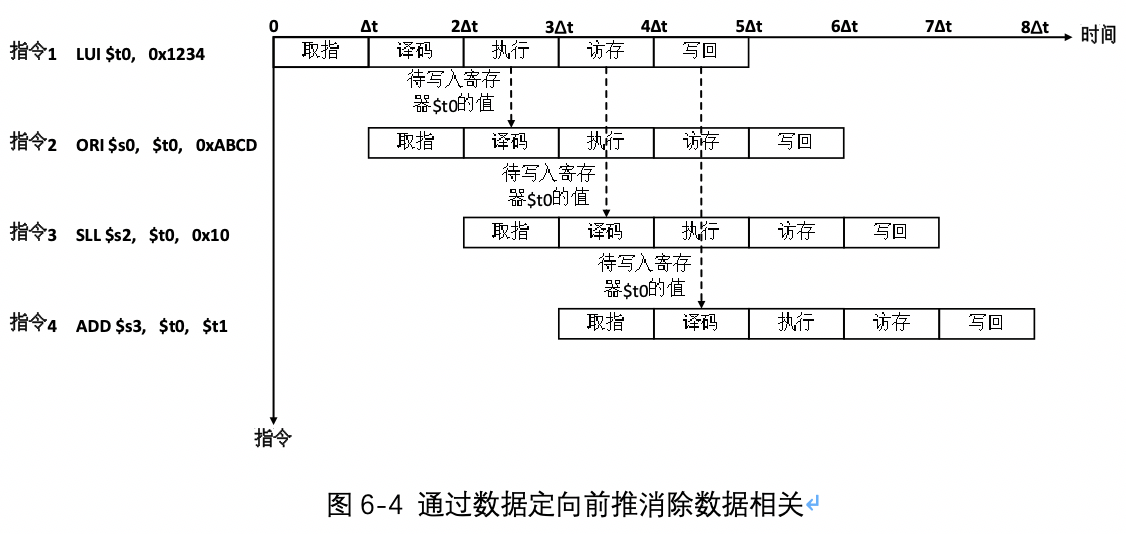
如图所示,指令1在执行阶段就已经计算出了结果,即待写入寄存器$t0的新值,此时,可以讲该值从指令1的执行阶段直接送到指令2的译码阶段,从而使指令2在译码阶段可以得到寄存器$t0的正确值,而不必等到寄存器$t0写回结束,译码-执行相关被消除。同理,在指令1的访存阶段,也可以将待写入寄存器$t0的值直接送到指令3的译码阶段,使指令3在译码阶段可以得到寄存器$t0的正确值,而不必等到寄存器写回结束,译码-访存相关被消除。同理,在指令1的写回阶段,也可将待写入寄存器$t0的值直接送到指令4的译码阶段,使指令4在译码阶段可以得到寄存器$t0的正确值,而不必等到寄存器$t0写回结束,译码-写回相关被消除。由此可见,采用定向前推方法后,流水线不再需要插入暂停周期,也可保证程序执行的正确性,上述4条指令需要8Δt运行完毕。否则,需要在指令1和指令2之间插入3个暂停周期,4条指令的运行共需要11Δt。
6.1.3 支持定向前推的处理器设计
流水线采用定向前推的方法消除数据相关,如果要使流水线支持定向前推,需要完成两个步骤的工作。第一,判断当前指令是否与之前指令存在数据相关;第二,如果存在数据相关,则需要将流水线中尚未写回寄存器的数据定向前推至所需指令处,使得该指令获得正确的数据。
通过这种设计,流水线中对于通用寄存器存在的译码-执行相关、译码-访存相关和译码-写回相关都会被消除,从而避免了在流水线中插入暂停周期带来的停顿问题,显著提高了流水线的处理性能。
6.1.4 基于Verilog HDL的实现与测试