简介
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。(摘自百度百科)
而在编写爬虫时,常常会发现,由于网页为动态网页,使用普通的静态网页爬取方法根本找不到动态加载的那些元素。
我们可以使用python执行JS代码或JS逆向等方法,但是过程过于复杂。
于是我们可以使用selenium,模仿人浏览网页,就能轻松绕过动态网页的坎。
Selenium使用方法
01 安装Selenium
安装Selenium的方法很简单,使用pip安装即可。
pip install selenium
Selenium需要使用webdriver对浏览器进行驱动,故此需要下载安装webdriver。
不同的浏览器使用不同的webdriver驱动,此处使用的是Chrome浏览器(谷歌浏览器)。
下载地址:https://chromedriver.storage.googleapis.com/index.html

注意:务必下载与你的浏览器相对应的webdriver版本!!!
之后需要将webdriver添加到环境变量。但是又一种更简单的方法:
将webdriver.exe文件放入python的安装路径(如下图)。

如果运行以下代码之后,电脑自动打开了谷歌浏览器,则安装成功。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://taobao.com')
time.sleep(3)
browser.close()
02 基本使用
(1) 寻找节点
寻找节点的方法有两种:find_element_by_ **** 和find_elements_by ****。
这两种寻找节点的方法区别是,find_element寻找单个元素,find_elements寻找多个元素返回列表。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://taobao.com')
input_target = browser.find_element_by_class_name('search-combobox-input')
print(input_target)
input_tag = browser.find_elements_by_class_name('search-combobox-input')
print(input_tag)
browser.close()
输出结果为:
<selenium.webdriver.remote.webelement.WebElement (session="d91af0a8b8088b8337c7e68197111ecf", element="3422ed00-ceee-44fe-90ba-23c065e8d79f")>
[<selenium.webdriver.remote.webelement.WebElement (session="d91af0a8b8088b8337c7e68197111ecf", element="3422ed00-ceee-44fe-90ba-23c065e8d79f")>]
寻找节点的方法有很多种,可以按照id、class、name等。以下仅列出部分:
| 寻找依据 | 方法 |
|---|---|
| 通过id寻找节点 | find_elements_by_id |
| 通过name寻找节点 | find_elements_by_name |
| 通过css寻找节点 | find_elements_by_css_selector |
| 通过class寻找节点 | find_elements_by_class_name |
(2) 对节点进行操作
Selenium可以对打开的网页进行操作,例如点击、输入、拖动验证码滑块等。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://taobao.com')
input_tag = browser.find_elements_by_class_name('search-combobox-input')[0] # 寻找到淘宝输入框
print(input_tag)
input_tag.send_keys('Python') # 在输入框输入Python
time.sleep(3)
input_tag.clear() # 清除输入框的文字
input_tag.send_keys('JavaScript') # 在输入框输入JavaScript
button = browser.find_elements_by_class_name('btn-search')[0] # 寻找淘宝的搜索按钮
print(button)
button.click() # 点击按钮
time.sleep(3)
browser.close() # 关闭浏览器
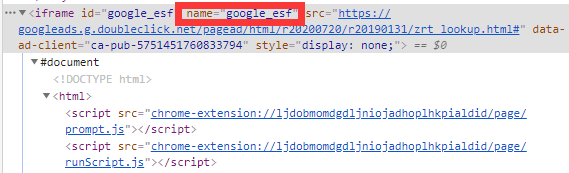
(3) 切换Frame
网页种常常出现一种节点iframe,可以看作是是网页的内嵌页面。
这种元素如果使用Selenium直接寻找iframe里面的节点,不会找到节点。
Selenium需要在寻找节点之前切换Frame。
browser.switch_to.frame('Frame2') # 切换到名为Frame2的框架中
例:
https://www.runoob.com/quiz/html-quiz.html
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.runoob.com/quiz/html-quiz.html')
browser.switch_to_frame('google_esf') # 切换到名为google_esf的frame
time.sleep(3)
browser.close()
03 代码下载
如需要代码,请移步我的GitHub。