作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/316
一、简述Hadoop平台的起源、发展历史与应用现状
Hadoop生态系统中,规模最大、知名度最高的公司则是Cloudera。Cloudera(英语:Cloudera, Inc.)是一家位于美国的软件公司,向企业客户提供基于Apache Hadoop的软件、支持、服务以及培训。Cloudera的开源Apache Hadoop发行版,亦即(Cloudera Distribution including Apache Hadoop,CDH),面向Hadoop企业级部署。Cloudera称,其一半以上的工程产出捐赠给了各个基于Apache许可与Hadoop紧密相连的开源项目(Apache Hive、Apache Avro、Apache HBase等等)。Cloudera还是Apache软件基金会的赞助商。
Hortonworks(英语:Hortonworks, Inc.)是一家位于美国加州帕拉奥图的商业计算机软件公司,专注于Apache Hadoop的开发和支持。Apache Hadoop是一种框架,能分布式处理跨计算机集群的海量数据。Hortonworks是一家由雅虎和基准资本出资2300万美金于2011年6月创建的独立公司,其员工为开源软件项目Apache Hadoop贡献代码。 2011年从雅虎剥离。Hortonworks的名称来自于《Horton Hears a Who!》一书中的角色Horton the Elephant。当前,艾瑞克Baldeschweiler和Rob比尔登分别担任首席执行官和首席运营官。Rob之前供职于SpringSource。该公司的其他投资者还有包括Index Ventures。
MapR公司是美国加州的圣何塞市的一个企业管理软件公司,主要专注于可用性和数据安全优化和开发、销售Apache Hadoop的衍生软件,对Apache Hadoop主要贡献有:HBase、Pig (编程语言)、Apache Hive以及Apache ZooKeeper。MapR的Apache Hadoop发行版的要求提供完整的数据保护、无单点故障,这大大的提高了其性能与易用性。MAPR被亚马逊云服务选择为亚马逊弹性云EC2的升级版本。
Pivotal公司是由EMC和VMware联合成立的一家新公司。Pivotal希望为新一代的应用提供一个原生的基础,建立在具有领导力的云和网络公司不断转型的IT特性之上。Pivotal的使命是推行这些创新,提供给企业IT架构师和独立软件提供商。Pivotal发布了自身的Apache Hadoop发行版——Pivotal HD。Pivotal HD对Apache Hadoop进行了全面的“改造”,同其他一些Hadoop发行版(Cloudera、Intel等)相比,其最大的优势就是能够与Greenplum数据库进行整合,而不仅仅是在Hadoop中运行SQL这么简单
IBM大家应该是耳熟能详,作为全球最大的信息技术和业务解决方案公司,拥有全球雇员 30多万人,业务遍及160多个国家和地区。IBM InfoSphere是IBM推出的大数据平台,平台提供了数据整合、数据仓库、主数据管理、大数据和信息治理等解决方案。
星环信息科技(上海)有限公司是目前国内极少数掌握企业级大数据Hadoop和Spark核心技术的高科技公司,从事大数据时代核心平台数据库软件的研发与服务。公司产品Transwarp Data Hub (TDH)的整体架构及功能特性比肩硅谷同行,产品性能在业界处于领先水平。TDH是基于Hadoop和Spark的分布式内存分析引擎和实时在线大规模计算分析平台,相比开源Hadoop版本有10x~100x倍性能提升,可处理GB到PB级别的数据。
红象云腾系统技术有限公司成立于2013年,致力于将大数据(Hadoop、Spark、Storm等)分布式技术带入更多中国企业,开展有大数据相关的基础软件平台、应用、解决方案、大数据培训等业务。红象云腾的核心产品RedHadoop Enterprise CRH3,定位是一体化大数据平台,以此为基础软件平台层,他们将持续开发应用层软件。
2004年 Doug Cutting 和 Mike Caferella实现了HDFS和MapReduce的初版
2005年12月 Nutch移植到新框架,Hadoop在20个节点上稳定运行
2006年1月 Doug Cutting加入雅虎
2006年2月 Apache Hadoop项目正式启动,支持MapReduce和HDFS独立发展
2006年2月 雅虎的网格计算团队采用Hadoop
2006年4月 在188个节点上(每个节点10GB)运行排序测试集需要47.9个小时
2006年5月 雅虎建立了300个节点的Hadoop研究集群
2006年5月 在500个节点上运行排序测试集需要42个小时(硬件比4月份的更好)
2006年11月 研究集群增加到600个节点
2006年12月 排序测试集在20个节点运行了1.8个小时,100个节点运行了3.3个小时,500个节点上运行了5.2个小时,900个节点上运行7.8个小时
2007年1月 研究集群增加到900个节点
2007年4月 研究集群增加到两个集群1000个节点
2008年4月 在900个节点上运行1TB排序测试集仅需209秒,成为全球最快
2008年10月 研究集群每天加载10TB的数据
2009年3月 17个集群共24000个节点
2009年4月 在每分钟排序中胜出,59秒排序500GB(在1400个节点上)和173分钟内排序100TB数据(在3400个节点上)
2009年5月 Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
2010年5月 IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2011年5月 Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
2012年3月 企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。
2012年10月 第一个Hadoop原生MPP查询引擎Impala加入到了Hadoop生态圈。
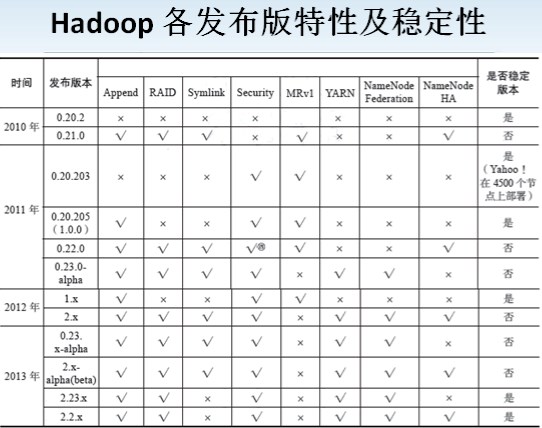
2.主要版本
Hadoop的版本很特殊,是由多条分支并行的发展着。
1.x:该版本是由0.20.x发行版系列的延续
2.x:该版本是由0.23.x发行版系列的延续
其实Hadoop也就两个版本1.x和2.x
Hadoop1.x 指的是:1.x(0.20.x)、0.21、0.22
Hadoop2.x 指的是:2.x、0.23.x
注意:高版本不一定包含低版本的特性
董的博客中也解释了各个版本的问题:
Hadoop版本选择探讨
Hadoop 2.0中的基本术语解释
Hadoop版本演变图
红色:表示企业中用的最多的实际生产版本
绿色:表示企业中用的最多的alpha版本 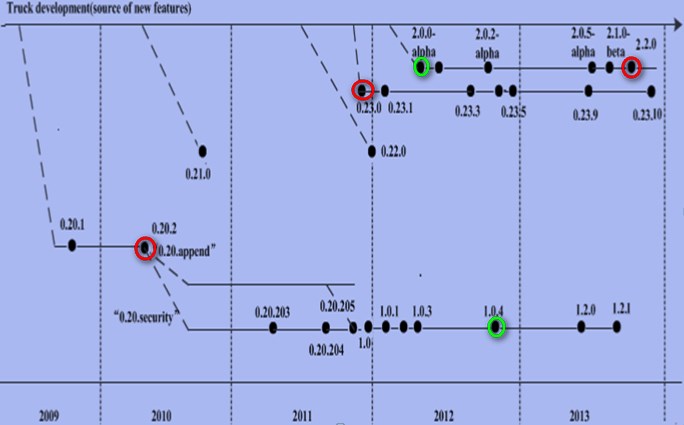
3.主要厂商
①CLOUDERA(规模最大、知名度最高,最早将Hadoop作为商用的公司);
②Hortonworks(主打产品Hortonworks Data Platform);
③IBM(BigInsights);
④Oracle(Oracle Big Data);
⑤EMC(Apache Hadoop发行版——Pivptal HD);
4.国内外Hadoop应用的典型案例。
Hadoop应用案例1-全球最大超市业者 Wal-Mart
Wal-Mart分析顾客商品搜索行为,找出超越竞争对手的商机
全球最大连锁超市Wal-Mart利用Hadoop来分析顾客搜寻商品的行为,以及用户透过搜索引擎寻找到Wal-Mart网站的关键词,利用这些关键词的分析结果发掘顾客需求,以规画下一季商品的促销策略,甚至打算分析顾客在Facebook、Twitter等社交网站上对商品的讨论,期望能比竞争对手提前一步发现顾客需求。
Wal-Mart虽然十年前就投入在线电子商务,但在线销售的营收远远落后于Amazon。后来,Wal-Mart决定采用Hadoop来分析顾客搜寻商品的行为,以及用户透过搜索引擎寻找到Wal-Mart网站的关键词,利用这些关键词的分析结果发掘顾客需求,以规画下一季商品的促销策略。他们并进一步打算要分析顾客在Facebook、Twitter等社交网站上对商品的讨论,甚至Wal-Mart能比父亲更快知道女儿怀孕的消息,并且主动寄送相关商品的促销邮件,可说是比竞争对手提前一步发现顾客。
Hadoop应用案例2-全球最大拍卖网站 eBay
eBay用Hadoop拆解非结构性巨量数据,降低数据仓储负载
经营拍卖业务的eBay则是用Hadoop来分析买卖双方在网站上的行为。eBay拥有全世界最大的数据仓储系统,每天增加的数据量有50TB,光是储存就是一大挑战,更遑论要分析这些数据,而且更困难的挑战是这些数据报括了结构化的数据和非结构化的数据,如照片、影片、电子邮件、用户的网站浏览Log记录等。
eBay是全球最大的拍卖网站,8千万名用户每天产生的数据量就达到50TB,相当于五天就增加了1座美国国会图书馆的数据量。这些数据报括了结构化的数据,和非结构化的数据如照片、影片、电子邮件、用户的网站浏览Log记录等。eBay正是用Hadoop来解决同时要分析大量结构化数据和非结构化的难题。
eBay分析平台高级总监Oliver Ratzesberger也坦言,大数据分析最大的挑战就是要同时处理结构化以及非结构化的数据。
eBay在5年多前就另外建置了一个软硬件整合的平台Singularity,搭配压缩技术来解决结构化数据和半结构化数据分析问题,3年前更在这个平台整合了Hadoop来处理非结构化数据,透过Hadoop来进行数据预先处理,将大块结构的非结构化数据拆解成小型数据,再放入数据仓储系统的数据模型中分析,来加快分析速度,也减轻对数据仓储系统的分析负载。
Hadoop应用案例3-全球最大信用卡公司 Visa
Visa快速发现可疑交易,1个月分析时间缩短成13分钟
Visa公司则是拥有一个全球最大的付费网络系统VisaNet,作为信用卡付款验证之用。2009年时,每天就要处理1.3亿次授权交易和140万台ATM的联机存取。为了降低信用卡各种诈骗、盗领事件的损失,Visa公司得分析每一笔事务数据,来找出可疑的交易。虽然每笔交易的数据记录只有短短200位,但每天VisaNet要处理全球上亿笔交易,2年累积的资料多达36TB,过去光是要分析5亿个用户账号之间的关联,得等1个月才能得到结果,所以,Visa也在2009年时导入了Hadoop,建置了2套Hadoop丛集(每套不到50个节点),让分析时间从1个月缩短到13分钟,更快速地找出了可疑交易,也能更快对银行提出预警,甚至能及时阻止诈骗交易。
这套被众多企业赖以解决大数据难题的分布式计算技术,并不是一项全新的技术,早在2006年就出现了,而且Hadoop的核心技术原理,更是源自Google打造搜索引擎的关键技术,后来由Yahoo支持的开源开发团队发展成一套Hadoop分布式计算平台,也成为Yahoo内部打造搜索引擎的关键技术。
二、 完成Hadoop的安装与配置

安装数据库

创建组

成功安装ssh
配置安装java环境

检测Hadoop可用
