一、准备环境
在配置hdfs之前,我们需要先安装好hadoop的配置,本文主要讲述hdfs单节点的安装配置。
hadoop的单节点安装配置请参考:https://www.cnblogs.com/lay2017/p/9912381.html
二、安装hdfs
配置文件
hadoop安装准备好之后,我们需要对其中的两个文件进行配置
1、core-site.xml
这里配置了一个hdfs的namenode节点,以及文件存储位置
<configuration> <!-- nameNode:接收请求的地址,客户端将请求该地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!-- file dir:文件的存储位置,默认指向系统的/tmp目录下,但是会导致系统重启的时候数据清空,所以指定一个位置来存储数据 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.9.0</value> </property> </configuration>
2、hdfs-site.xml
由于我们是单节点,所以复制数据块配置为1即可(replication是通过复制数据块用备份的方式来做到数据容错的)
<configuration> <!-- replication --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
ssh免密码
为了方便,我们最好设置一下ssh免密码,不然每次都要输入密码才可以进入下一步,很麻烦。
先看看你的系统支不支持ssh免密码
ssh localhost
如果不支持,按顺序执行下面三行命令即可
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
格式化
初次使用hdfs需要进行格式化
hdfs namenode -format
启动
格式化完成以后,我们就可以启动hdfs了
sbin/start-dfs.sh
启动完成,我们查看一下hdfs进程
ps -ef|grep hdfs
你会看到:nameNodedataNodesecondaryNameNode这三个进程,则表示启动成功,否则到logs下的对应日志中查看错误信息。
注意:期间如果你看到如下错误
Incompatible clusterIDs in /opt/hadoop-2.9.0/dfs/data
这个是由于你配置的hadoop.tmp.dir可能被格式化过有不兼容的东西,所以你如果要重新格式化可以选择目录下的文件全部删除掉(前提是没有重要文件)
web访问
我们可以通过http来查看hdfs,为了方便查看你可以关闭防火墙
查看防火墙状态
systemctl status firewalld
关闭防火墙
systemctl stop firewalld
然后拿到当前系统的IP地址,注意:虚拟机需要是桥接模式
ifconfig

然后宿主机可以通过http访问,IP修改为你的虚拟机IP
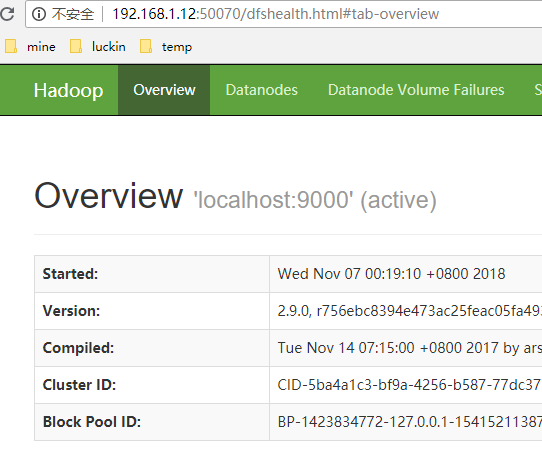
http://192.168.1.12:50070
你会看到
关闭
sbin/stop-dfs.sh