一、hadoop简介
相信你或多或少都听过hadoop这个名字,hadoop是一个开源的、分布式软件平台。它主要解决了分布式存储(hdfs)和分布式计算(mapReduce)两个大数据的痛点问题,在hadoop平台上你可以轻易地使用和扩展数千台的计算机而不用关心底层的实现问题。而现在的hadoop更是形成了一个生态体系,如图:
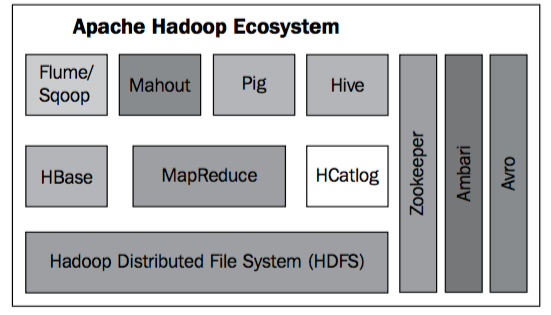
上图大体展示了hadoop的生态体系,但并不完整。总而言之,随着hadoop越来越成熟,也会有更多地成员加入hadoop生态体系中。
hadoop官方网站:http://hadoop.apache.org/
二、安装hadoop
hadoop安装分为三种形式:
1、单节点:也就是仅在一台机器上安装一个hadoop节点;
2、伪分布式:在一台机器上安装多个hadoop节点,模拟分布式环境;
3、完全分布式:在多态机器上分别安装节点;
而本文将以单节点安装作为学习演示使用
完全分布式可以参考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
准备环境
Linux系统:hadoop可以在Linux和windows平台上安装,但是windows平台没有经过生成测试,所以建议使用Linux平台,而本文采用的是centos作为测试平台。你可以在自己的电脑安装虚拟机来操作,安装vmware和centos参考文档:
https://www.cnblogs.com/lay2017/p/9786213.html
https://www.cnblogs.com/lay2017/p/9786479.html
hadoop是由Java开发的,所以你需要提供JDK环境的支持:
Linux中JDK安装参考文档:
https://www.cnblogs.com/lay2017/p/7442217.html
注意:如果你安装hadoop2.7+版本的话需要JDK1.7+的支持,如果是2.6-版本需要JDK1.6的支持。
下载安装hadoop
前往hadoop下载页面找到二进制包的下载地址
http://www.apache.org/dyn/closer.cgi/hadoop/common/
我们先在centos下创建一个hadoop目录,然后进入该目录:
mkdir /usr/local/hadoop
cd /usr/local/hadoop
使用wget命令下载hadoop到当前目录下(本文下载的是2.9.0稳定版:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz)

使用tar命令解压缩

你会得到

接下来,你需要配置JAVA_HOME,首先进入到etc/hadoop目录下
cd /usr/local/hadoop/hadoop-2.9.0/etc/hadoop
编辑hadoop-env.sh文件

配置你的JAVA_HOME

三、测试
你可以使用hadoop/bin目录下的hadoop命令简单地查看一下版本号来测试:
bin/hadoop version
除了简单地使用命令,我们还可以运行hadoop的示例程序
为了验证当前的hadoop是否可用的,下面我们使用share目录下mapReduce的示例jar来测试一下
我们先回到hadoop的根目录
cd /usr/local/hadoop/hadoop-2.9.0
在运行示例jar之前先创建一个目录用于输入文件数据
mkdir input
我们将etc/hadoop下的一些文本文件拷贝过来当作测试用一下
cp etc/hadoop/*.xml input
接下来我们就可以运行share目录下的示例程序了(运行结果是统计所有输入文件中字符h出现的次数)
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar grep input output 'h'
我们将结果输出看一下
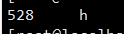
cat output/*
你会看到,统计次数为528次
为了以后方便,我们将hadoop的bin目录和sbin目录配置到系统环境变量里面去:
编辑系统环境变量配置
vi /etc/profile
增加环境变量,把hadoop_home和path给添加到系统里面去

这样我们在使用命令的时候就可以直接使用了,如
hadoop version
以上就是hadoop单节点的安装,参考官方文档实现:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html