一、安装spark
spark SQL是spark的一个功能模块,所以我们事先要安装配置spark,参考:
https://www.cnblogs.com/lay2017/p/10006935.html
二、数据准备
演示操作将从一个类似json文件里面读取数据作为数据源,并初始化为dataframe,我们准备一个user.json文件
在/usr/local/hadoop/spark目录(可以自定义目录)下新建一个user.json文件内容如下:
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
文件内容类似json,但是不是json,按照一行一行的结构
三、spark SQL示例
先启动spark-shell
spark-shell
初始化一个SQLContext,传入sparkContext
var sqlContext = new org.apache.spark.sql.SQLContext(sc)
读取user.json文件作为dataFrame
var dfs = sqlContext.read.json("/usr/local/hadoop/spark/user.json")
dataFrame操作
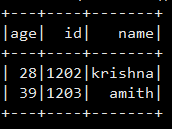
查询age > 25的name的数据
dfs.filter(dfs("age") > 25).select("name").show()
你会看到

sql操作
创建一个临时表
dfs.createOrReplaceTempView("t_user")
编写SQL
var sqlDf = spark.sql("select * from t_user where age > 25")
显示结果
sqlDf.show()
显示如下