1 依赖项
- java
- ssh
$ java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
$ echo $JAVA_HOME
/path/to/jdk1.8.0_181
2 安装和配置
这里使用2.9.1版本:http://www.apache.org/dyn/closer.cgi/hadoop/common/
sudo useradd -m hadoop -s /bin/bash # 创建hadoop用户
sudo passwd hadoop # 修改密码
sudo adduser hadoop sudo # 增加管理员权限
$ cat /etc/passwd |tail -n 1
hadoop:x:10003:10003::/home/hadoop:/bin/bash
$ ./bin/hadoop version
Hadoop 2.9.1
Subversion https://github.com/apache/hadoop.git -r e30710aea4e6e55e69372929106cf119af06fd0e
2.1 单机版配置
默认情况下Hadoop就是起一个java进程来运行单机版的,到这里可以使用单机版了,不需要额外的配置。
官方grep例子
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar #所有例子
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar grep input output 'dfs[a-z.]+'
$ cat output/*
2.2 伪分布式配置
伪分布式模式下每个Hadoop守护进程都是一个独立java进程。
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/path/to/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/path/to/hdfs/data</value>
</property>
</configuration>
$ cd /usr/local/hadoop
$ bin/hdfs namenode -format # namenode 格式化
sbin/start-dfs.sh # 开启守护进程
./sbin/stop-dfs.sh # 关闭
jps # 判断是否启动成功
$ hdfs dfs -ls / #列出/下所有文件
Found 2 items
drwxrwx--- - work supergroup 0 2018-10-11 22:04 /tmp
drwxr-xr-x - work supergroup 0 2018-10-11 21:55 /user
2.3 yarn
./etc/hadoop/mapred-site.xml :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
./etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
$ ./sbin/start-yarn.sh # 启动YARN
$ ./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
$ jps
77153 DataNode
84726 JobHistoryServer
77003 NameNode
84269 ResourceManager # yarn
77341 SecondaryNameNode
56588 Jps
84572 NodeManager # yarn
resource manager 和 node manager共同组成 data-computation 框架。
yarn的理念是把 resource management 和 job scheduling/monitoring 拆分成独立的守护进程。
架构如下:
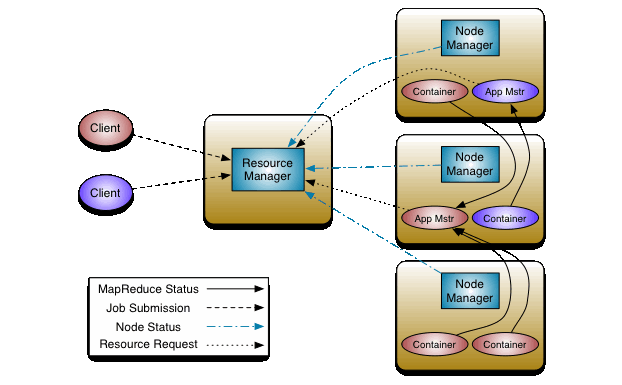
有一个全局的RM,每个应用(单个job或者job组成的DAG)有一个AM。
RM包含2部分: Scheduler 和 ApplicationsManager。
其中Scheduler只负责资源分配,把 resource Container 作为和 memory, cpu, disk, network一样的资源去管理。
AM负责接收提交的job,为了运行应用,要从 Scheduler 申请合适的 Container ,跟踪其状态,监控其进程,出问题要重启。
ref: http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html
3 web UI
yarn: http://localhost:8088/cluster
hadoop: http://localhost:50070/dfshealth.html#tab-overview