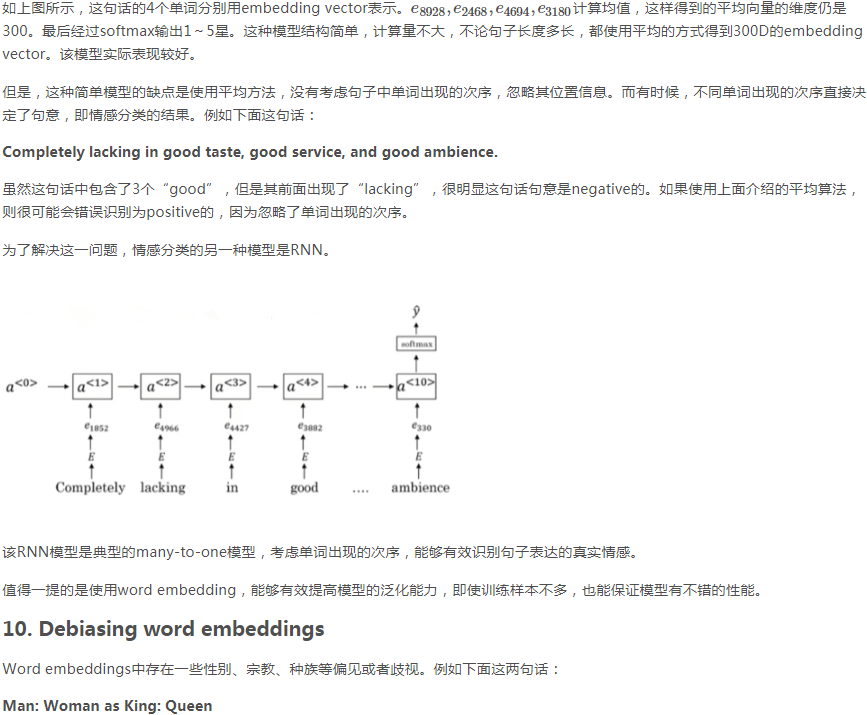

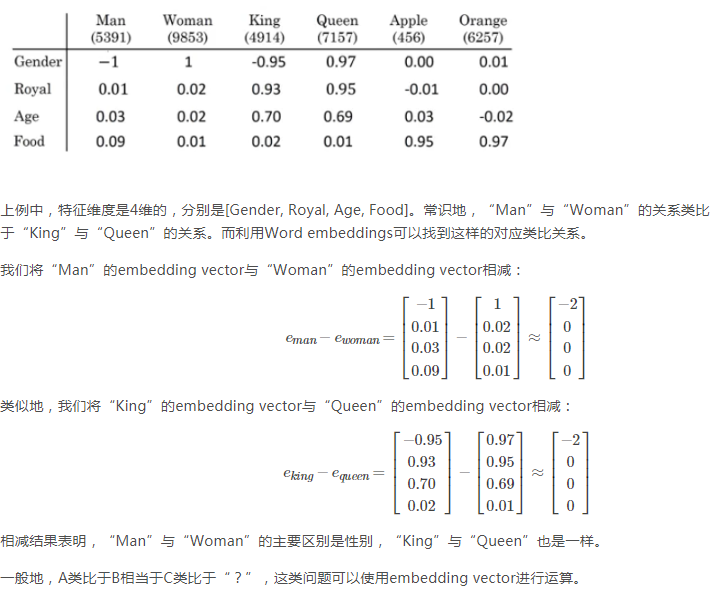

如果相似函数是cosine similarity,且A类比于B相当于C类比于“?” 该如何求“?”
首先求出sim(A,B) 然后令sim(C,?)=sim(A,B) 然后求出?,再找到与?相似性最大的向量e?。
或者求出sim(A,B)后,将其他向量逐一代入sim(C,?) 看看哪个与Sim(A,B)最接近。



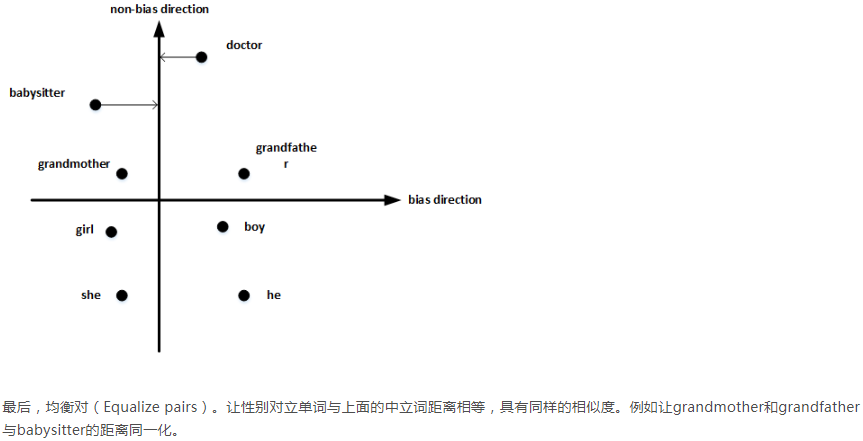
下面介绍另一种得到E的方法:

上图的输入层是某个单词的one-hot向量。隐藏层具有300个结点,输入层与隐藏层之间的w矩阵是 300*10000的,这里的W其实就是E。输出层是softmax层,有10000个结点,输出的结果就是每个单词出现在输入单词附近的概率。需要注意的是,一个输入只会对W中其对应的向量进行训练,而不会对其它向量起作用,因为输入只有一个元素为1,其他全为0,所以梯度下降的时候,W中除输入单词对应的向量外,其他的梯度值全为0。但是经过大量的训练样本训练,就能得到准确的E。

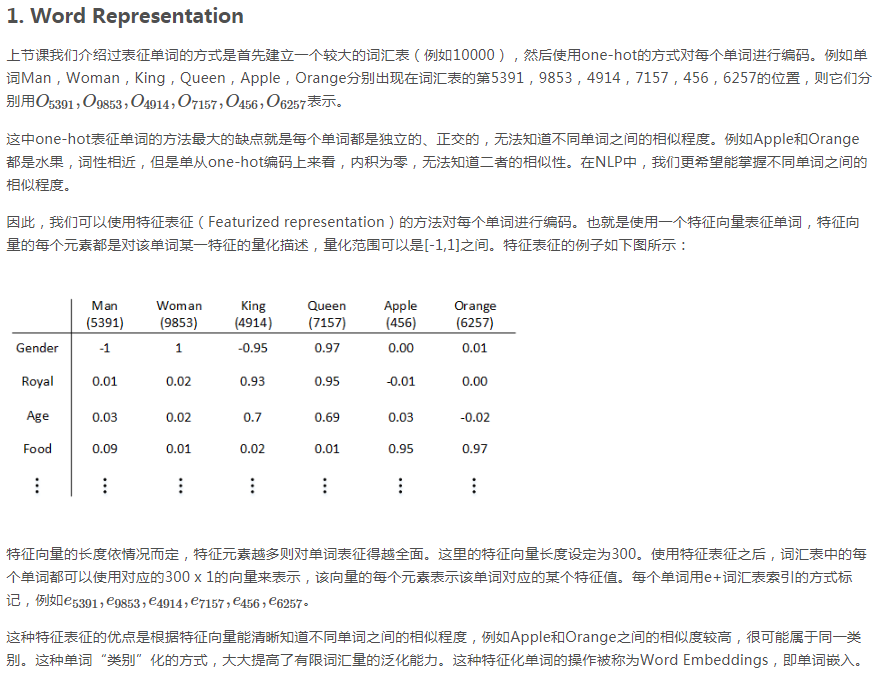
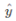 是总体的输出,是个1*10000的列向量,是每个单词出现在输入单词附近的概率。ec是输入层,是输入单词的特征向量。
是总体的输出,是个1*10000的列向量,是每个单词出现在输入单词附近的概率。ec是输入层,是输入单词的特征向量。 就是输入层与输出层之间的(Wb)矩阵。
就是输入层与输出层之间的(Wb)矩阵。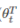 与w的区别就是多了b
与w的区别就是多了b 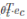 就是放入softmax层之前的结果。
就是放入softmax层之前的结果。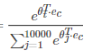 是放入softmax层之后的结果。
是放入softmax层之后的结果。
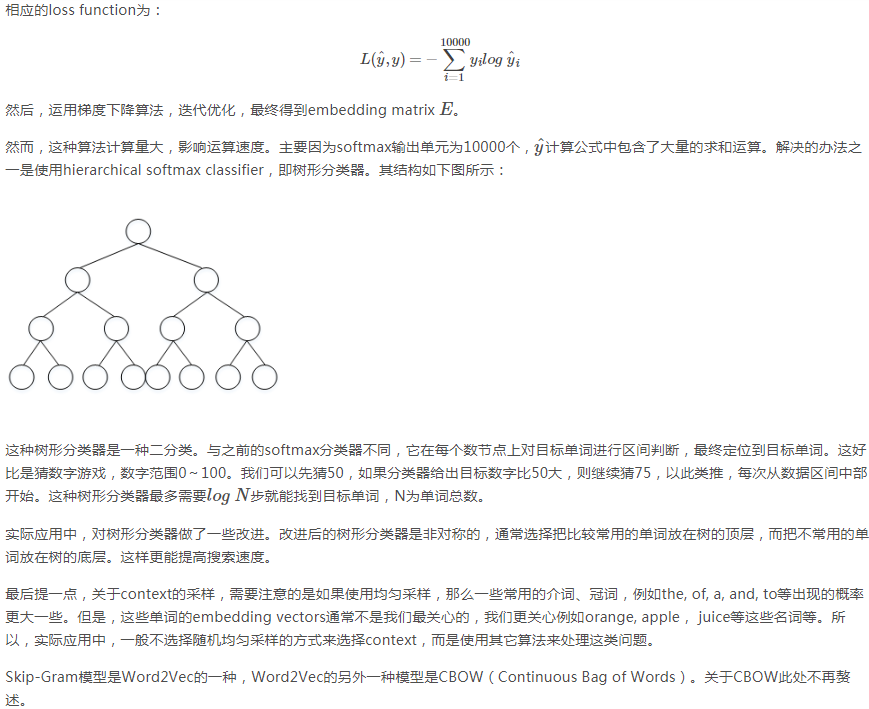
 左边的数学式子P就是指的输出。
左边的数学式子P就是指的输出。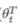 就是wb
就是wb


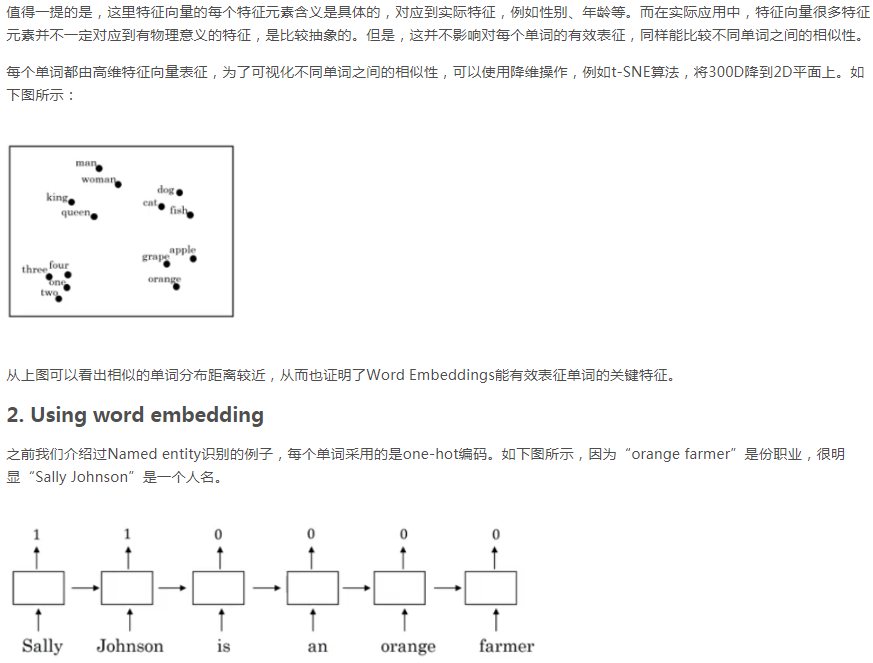
上图举例说明了负采样的过程:输入是orange对应的e向量。输出有10000个结点,但是,我们只需要关注其中的k+1个结点的结果:1个结点是正样本,k个结点是负样本。权值矩阵是300*10000的,300是e的元素数,但是我们反向传播时需要改变的也只是与k+1个输出结点相关的参数,而不用管其它的W和b,除此之外,反向传播还需要对输入向量e进行更新。损失函数也只是与k+1个输出结点相关,而与其他结点无关。
负采样是目的是得到嵌入矩阵E。但是要注意 嵌入矩阵E的作用是预测词出现的概率。 要理解这个


对损失函数 的理解:
的理解:
嵌入矩阵的实际应用是求某个位置该是哪个词。所以如果将嵌入矩阵代入一个神经网络,如果输出的结果和实际结果相差很小,那么这个嵌入矩阵就是合理的。对于损失函数,如果损失函数越小输出结果越接近真实值,那么这个神经网络就是有效的,嵌入矩阵也必然是有效的,因为迭代的结果肯定是损失函数很小,输出很接近真实情况,把迭达结束时的矩阵称为嵌入矩阵。反过来,如果令迭代结束时的矩阵正向传播,得到的结果必然也接近真实情况,所以得到的嵌入矩阵肯定是合理的。
本方法的损失函数里的 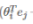 可看作单词10000个单词出现在单词 j 附近的概率结果,是个1*10000的列向量(10000是词库的单词总量,该式与之前几种方法中出现的意义相同)
可看作单词10000个单词出现在单词 j 附近的概率结果,是个1*10000的列向量(10000是词库的单词总量,该式与之前几种方法中出现的意义相同)
Xij是i出现在j附近的次数。 显然,损失函数越小,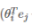 与 Xij越接近。而某个单词出现在另一个单词附近的概率,是与训练集中该单词出现在另一个单词附近的次数成正相关的,所以损失函数越小,输出结果越接近真实情况,所以该方法是合理的。
与 Xij越接近。而某个单词出现在另一个单词附近的概率,是与训练集中该单词出现在另一个单词附近的次数成正相关的,所以损失函数越小,输出结果越接近真实情况,所以该方法是合理的。