参数的更新
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻 找最优参数的问题,解决这个问题的过程称为最优化(optimization)。
SGD
![]()
这里把需要更新的权重参数记为W,把损失函数关于W的梯度记为 ![]() 。 η表示学习率,实际上会取0.01或0.001这些事先决定好的值。式子中的表示用右边的值更新左边的值。
。 η表示学习率,实际上会取0.01或0.001这些事先决定好的值。式子中的表示用右边的值更新左边的值。
SGD的缺点:SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。
Momentum
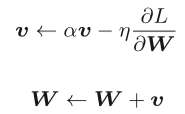
Momentum是“动量”的意思,和物理有关。这里新出现了一个变量v,对应物理上的速度。式中有 αv这一项,在物体不受任何力时,该项承担使物体逐渐减速的任务(α设定为0.9之类的值),对应物理上的地面摩擦或空气阻力。
AdaGrad
在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习 。
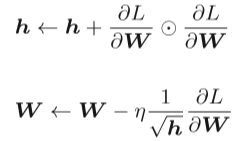
这里新出现了变量h,如式(6.5)所示,它保 存了以前的所有梯度值的平方和。在更新参数时,通过乘以 ,就可以调整学习的尺度。这意味着, 参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说, 可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新 的幅度就越小。实际上,如果无止境地学习,更新量就会变为0, 完全不再更新。
Adam
Momentum参照小球在碗中滚动的物理规则进行移动,AdaGrad为参 数的每个元素适当地调整更新步伐,Adam将两者的思想结合起来。基于Adam的更新过程就像小球在碗中滚动一样。虽然 Momentun也有类似的移动,但是相比之下,Adam的小球左右摇晃的程度有所减轻。这得益于学习的更新程度被适当地调整了。
权重的初始值
简单地说,权值衰减就是一种以减小权重参数的值为目的进行学习的方法。通过减小权重参数的值来抑制过拟合的发生。如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上,在这之前的权重初始值都是像0.01 * np.random.randn(10, 100)这样,使用由高斯分布生成的值乘以0.01 后得到的值(标准差为0.01 的高斯分布)。为了防止“权重均一化”(严格地讲,是为了瓦解权重的对称结构),必须随机生成初始值。
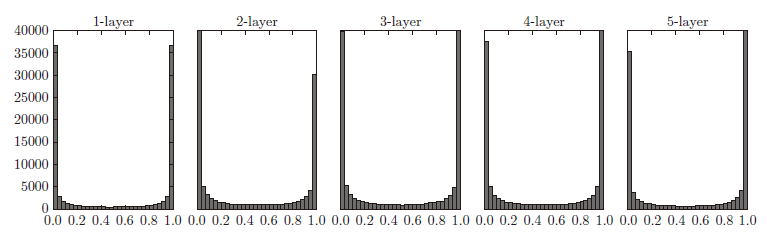
使用标准差为1 的高斯分布时,各层的激活值的分布如图所示, 各层的激活值呈偏向0 和1 的分布。使用sigmoid函数是S型函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。因此,偏向0 和1 的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。
使用标准差为0.01 的高斯分布时,各层的激活值的分布.这次呈集中在0.5 附近的分布。因为不像刚才的例子那样偏向0 和1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,但是表现力上会有很大问题。因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果100 个神经元都输出几乎相同的值,那么也可以由1 个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题。
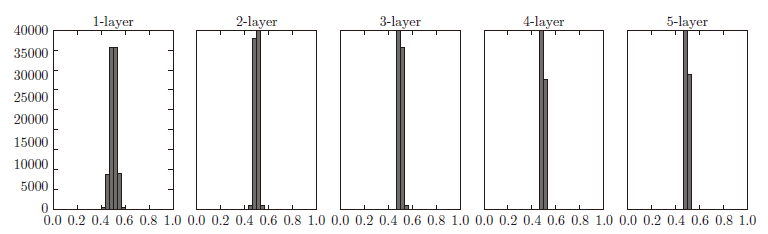
各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
Xavier初始值:与前一层有n个节点连接时,初始值使用标准差为![]() 的分布。
的分布。
ReLU的权重初始值
当前一层的节点数为n 时,He 初始值使用标准差为![]() 的高斯分布 。在神经网络的学习中,权重初始值非常重要。很多时候权重初始值的设定关系到神经网络的学习能否成功。
的高斯分布 。在神经网络的学习中,权重初始值非常重要。很多时候权重初始值的设定关系到神经网络的学习能否成功。
Batch Normalizatio
为了使各层激活值分布拥有适当的广度,“强制性”地调整激活值的分布。Batch Norm有以下优点:
• 可以使学习快速进行(可以增大学习率)。
• 不那么依赖初始值(对于初始值不用那么神经质)。
• 抑制过拟合(降低Dropout等的必要性)。
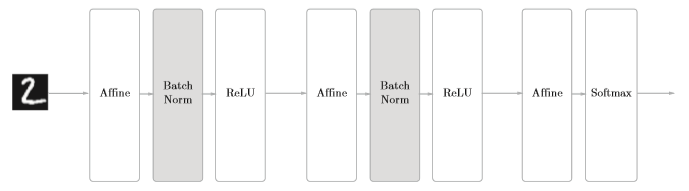
Batch Norm,顾名思义,以进行学习时的mini-batch为单位,按minibatch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的正规化。
正则化
发生过拟合的原因,主要有以下两个。
• 模型拥有大量参数、表现力强。
• 训练数据少。
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是因为权重参数取值过大才发生的。L2 范数、L1范数、L∞范数都可以用作正则化项,它们各有各的特点,不过这里我们要实现的是比较常用的L2范数。
Dropout 是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递,如图所示。
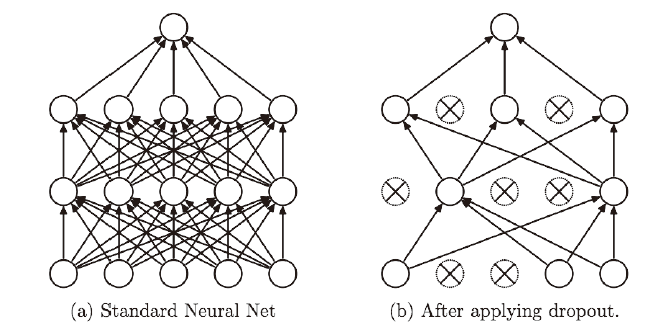
机器学习中经常使用集成学习。所谓集成学习,就是让多个模型单独进行学习,推理时再取多个模型的输出的平均值。用神经网络的语境来说,比如,准备5个结构相同(或者类似)的网络,分别进行学习,测试时,以这5 个网络的输出的平均值作为答案。
超参数的最优化
超参数的最优化的内容:
步骤1
从设定的超参数范围中随机采样。
步骤2
使用步骤1 中采样到的超参数的值进行学习,通过验证数据评估识别精度(但是要将epoch 设置得很小)。
步骤3
重复步骤1 和步骤2(100 次等),根据它们的识别精度的结果,缩小超参数的范围。
在超参数的最优化中,如果需要更精炼的方法,可以使用贝叶斯最优化(Bayesian optimization)。贝叶斯最优化运用以贝叶斯定理为中心的数学理论,能够更加严密、高效地进行最优化。