1. unix 套接字简介
在Linux系统中,有很多进程间通信方式,套接字(Socket)就是其中的一种。
但传统的套接字的用法都是基于TCP/IP协议栈的,需要指定IP地址。如果不同主机上的两个进程进行通信,当然这样做没什么问题。但是,如果只需要在一台机器上的两个不同进程间通信,还要用到IP地址就有点大材小用了。
其实很多人并不一定知道,对于套接字来说,还存在一种叫做Unix域套接字的类别,专门用来解决这个问题。其API的掉用方法基本上和普通TCP/IP的套接字一样,只是有些许差别。
因此,再正式介绍之前,先来复习一下套接字从创建,到传输数据,再到最后关闭的所有过程:
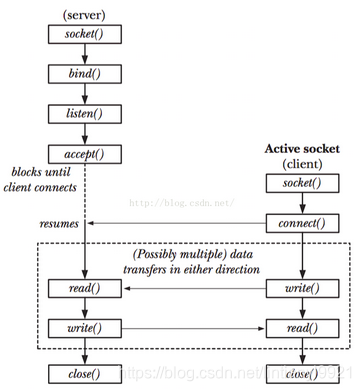
1.1面向流的套接字,对于TCP/IP套接字来说,代表TCP协议
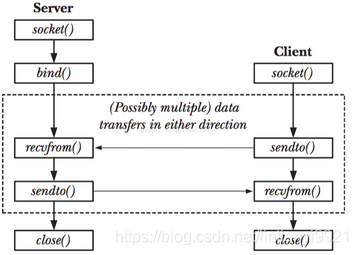
1.2 面向数据包的套接字,对于TCP/IP套接字来说,代表UDP协议。
2 .接下来,我们将特别针对普通TCP/IP套接字和Unix域套接字的不同,对这些API做一些解释。
1)socket()
最开始肯定还是要创建一个套接字:
int sockfd = socket(AF_UNIX, SOCK_STREAM, 0); // 流式Unix域套接字
int sockfd = socket(AF_UNIX,SOCK_DGRAM, 0); // 数据包式套接字
2)bind()
对于流式套接字的服务器端来说,在用socket()函数获得了新创建套接字的文件描述符之后,还要将其绑定到一个地址上去:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
struct sockaddr_un {
sa_family_t sun_family;
char sun_path[108];
}
结构体中的第一个字段必须要设置成“AF_UNIX”。而第二个字段,表示的是一个路径名。因此,要将一个Unix域套接字绑定到一个本地地址上,需要创建并初始化一个sockaddr_un结构体,并将指向这个结构体的指针作为addr参数(需要类型转换)传入bind()函数,并将addrlen参数设置成这个结构体的实际大小。
这里还要特别提一下这个路径名,其实还要分为两种,一种是普通路径名,另一种是抽象路径名。
- 普通路径名
首先来说说普通路径名,这个很好理解,就是一个基本的Linux文件路径,其必须要以NULL(’�’)结尾。在绑定一个Unix域套接字时,会在文件系统中的相应位置上创建一个文件,且这个文件的类型被标记为“Socket”,因此这个文件无法用open()函数打开。当不再需要这个Unix域套接字时,可以使用remove()函数或者unlink()函数将这个对应的文件删除。如果在文件系统中,已经有了一个文件和指定的路径名相同,则绑定会失败(返回错误EADDRINUSE)。所以,一个套接字只能绑定到一个路径上,同样的,一个路径也只能被一个套接字绑定。 - 抽象路径名
接下来看看什么叫抽象路径名,这其实是Linux特有的一个特性,它允许将一个Unix域套接字绑定到一个名字上,且不会在文件系统中创建这个名字的文件。如果要创建一个抽象名字空间的绑定,必须要将sun_path字段的第一个字节设置成NULL(’�’),而且和普通的文件系统名字空间不同的是,系统会用sun_path除第一个字节之后余下的所有字节当做抽象名字。也就是说在解析抽象路径名时需要用到sun_path字段当中所有的字节,而不是像解析普通路径名一样,解析到第一个NULL就可以停止了。因为不会再在文件系统中创建文件了,所以对于抽象路径名来说,就不需要担心与文件系统中已存在的文件产生名字冲突的问题了,也不需要在使用完套接字之后删除附带产生的这个文件了,当套接字被关闭之后会自动删除这个抽象名。
最后再提一下权限的问题,因为要在文件系统中创建相应的文件,对于普通路径名来说,掉用bind()函数的进程必须要有路径名中目录部分的可写和可访问权限。还有,在默认情况下,在调用bind()函数时,会给所有者、组和其他用户赋予所有的权限(即777),如果想改变这个行为,可以在bind()之后再修改创建的文件的权限和属性。
3)listen()
对于流式套接字的服务器端来说,listen()函数在TCP/IP套接字和Unix域套接字中调用方式是一样的,没有区别:
int listen(int sockfd, int backlog);
4)accept()
对于流式套接字的服务器端来说,在调用bind()绑定完本地路径之后,还需要接收客户端的请求,这是通过调用accept()函数来实现的:
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
与普通的TCP/IP套接字不同,Unix域套接字不存在客户端地址的问题(都在一台机器上),因此这里的addr和addrlen参数都要设置成NULL。在这里,不同进程像这个服务器端进程发送的流数据是在内核里面区分的,并绑定到了accept()创建的套接字中了。而数据包套接字就没有这种对应关系,所以还是要在代码中区分出来,后面会介绍。
5)connect()
对于流式套接字的客户端来说,在用socket()函数获得了新创建套接字的文件描述符之后,就可以调用connect()函数连接服务器端了:
int connect(int sockfd, struct sockaddr *addr,int addrlen);
这个函数在TCP/IP套接字中和在Unix域套接字中调用方式基本相同,只不过和bind()函数一样,地址addr必须是以sockaddr_un结构体来表示。
6)read()和write()
对于流式套接字的服务器端来说,read()和write函数在TCP/IP套接字和Unix域套接字中调用方式是一样的,没有区别:
ssize_t read(int sockfd, void *buf, size_t length);
ssize_t write(int sockfd, const void *buf, size_t length);
7)recvfrom()和sendto()
对于数据包事套接字来说,在服务器端recvfrom()用来接收客户端发送的请求,而在客户端这个函数用来接收服务器端发送过来的响应:
int recvfrom(int sockfd, void *buf, int length, unsigned int flags, struct sockaddr *addr, int *addrlen);
同时,在客户端sendto()用来向服务器端发送请求数据,而服务器端用这个函数来向客户端发送响应数据:
int sendto (int sockfd, const void *buf, int length, unsigned int flags, const struct sockaddr *addr, int addrlen);
前面也提到了,对于数据包套接字来说,服务器端在发送响应数据时是需要知道客户端到底是哪个的,从而后面可以将相应的响应数据发送给正确的客户端。而客户端也需要知道到底是向哪个服务器端发送数据,或者说接收到的响应数据到底来自哪个服务器端(当然,如果只保证和一个服务器端通信就没有这个问题)。
但是,按照普通的包套接字创建和连接的流程,只是在服务器端掉用bind()函数绑定了一个地址,而客户端并没有地址。这在流式套接字中没有问题,内核已经在服务器端调用accept()函数接收一个客户端连接时创建了一个新的套接字,从而将一一对应关系绑定到了这个新的套接字上了。所以,对于包套接字来说,在客户端还需要再掉用bind()函数绑定一次,人为的创建一个客户端地址,且这个客户端路径名地址显然不能和服务器端的路径名相同。
剩下的就都和普通的TCP/IP套接字相同了,只不过地址addr必须是以sockaddr_un结构体来表示罢了。