
原始文档:https://www.yuque.com/lart/papers/drggso
ICLR 2020的文章.
针对长尾分布的分类问题提出了一种简单有效的基于re-sample范式的策略.
提出的方法将模型的学习过程拆分成两部分:representation learning 和 classification.
对于前者, 则将完整的模型在原始的数据分布上进行训练, 即instance-balanced (natural) sampling, 从而学习_the best and most generalizable representations_. 训练好后, 再额外调整模型的分类器(retraining the classifier with class-balanced sampling or by a simple, yet effective, classifier weight normalization which has only a single hyperparameter controlling the "temperature" and which does not require additional training).
在这份工作中, 作者们证明了在长尾场景中, 将这种分离(separation)可以更加直接的获得好的检测性能, 而不需要设计采样策略、平衡损失或者是添加memory模块.
按照这里https://zhuanlan.zhihu.com/p/158638078总结的:
对任何不均衡分类数据集地再平衡本质都应该只是对分类器地再均衡, 而不应该用类别的分布改变特征学习时图片特征的分布, 或者说图片特征的分布和类别标注的分布, 本质上是不耦合的.
背景信息
相关工作
论文中关于相关工作的介绍非常细致和全面, 进行了较为完整的梳理.
现有的研究主要可以划分为三个方向:
- Data distribution re-balancing. Re-sample the dataset to achieve a more balanced data distribution.
- 过采样, over-sampling for the minority classes (by adding copies of data)
- 欠采样, undersampling for the majority classes (by removing data)
- 类平衡采样, class-balanced sampling based on the number of samples for each class
- Class-balanced Losses. Assign different losses to different training samples for each class.
- The loss can vary at class-level for matching a given data distribution and improving the generalization of tail classes.
- A more fine-grained control of the loss can also be achieved at sample level, e.g. with Focal loss, Meta-Weight-Net, re-weighted training, or based on Bayesian uncertainty.
- To balance the classification regions of head and tail classes using an affinity measure to enforce cluster centers of classes to be uniformly spaced and equidistant.
- Transfer learning from head to tail classes. Transferring features learned from head classes with abundant training instances to under-represented tail classes.
- Recent work includes transferring the intra-class variance and transferring semantic deep features. However it is usually a non-trivial task to design specific modules (e.g. external memory) for feature transfer.
并且也补充了和最近的一个关于少样本识别(low-shot recognition)的基准方法的比较:
- 少样本识别, 他们包含着一个表征学习阶段, 这个阶段中不能处理(without access to)少样本类. 后续会有少样本学习阶段.
- 与其不同, 长尾分布识别的设定假设可以访问头部和尾部类别, 并且类别标签的减少更加连续.
长尾识别的表征学习
在长尾识别中, 训练集在所有的类上整体遵循着一个长尾分布. 在训练过程中, 对于一些不常见的类数据量很小, 使用这样的不平衡的数据集训练得到的模型趋向于在小样本类上欠拟合. 但是实践中, 对于所有类都能良好识别的模型才是我们需要的. 因此不同针对少样本的重采样策略、损失重加权和边界正则化(margin regularization)方法被提出. 然而, 目前尚不清楚它们如何实现长尾识别的性能提升(如果有的话).
本文将会系统地通过将表征学习过程与分类器学习过程分离的方式探究他们的有效性, 来识别什么对于长尾分布确实重要.
首先明确相关的符号表示:
- (X={x_i, y_i}, i in {1, dots, n})表示训练集, 其中的(y_i)表示对于数据点(x_i)对应的标签.
- (n_j)表示对于类别(j)对应的训练样本的数量, 而(n = Sigma^{c}_{j=1} n_j)表示总的训练样本数.
- 不是一般性, 这里将所有类按照各自的样本数, 即其容量来降序排序, 即, 如果(i<j), 则有(n_i ge n_j). 另外由于长尾的设定, 所以(n_1 gg n_C), 即头部类远大于尾部类.
- (f(x; heta) = z)表示对于输入数据的表征, 这里(f(x; heta))通过参数为( heta)的CNN模型实现.
- 最终的类别预测( ilde{y})由分类器函数(g)给出, 即( ilde{y} = ext{argmax}\, g(z)). 一般情况下(g)就是一个线性分类器, 即(g(z) = mathbf{W}^ op z + mathbf{b}). 这里的(mathbf{W} & mathbf{b})分别表示权重矩阵和偏置参数. 当然, 文章中也讨论了一些其他形式的(g).
采样策略
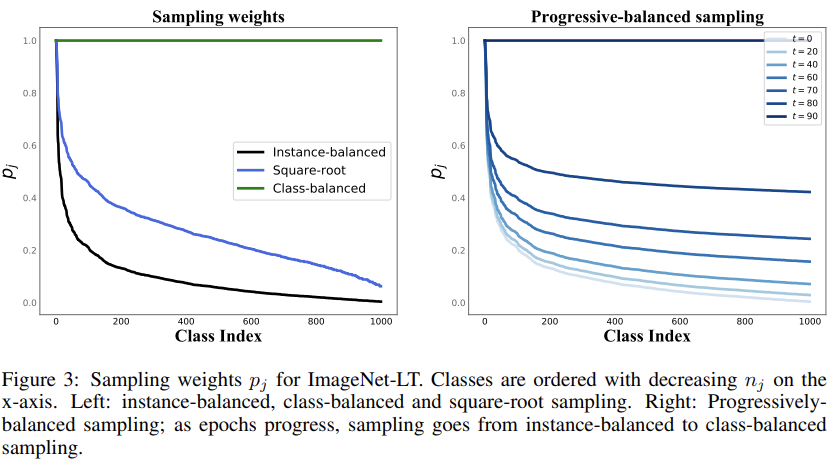
这旨在平衡表征学习与分类器学习的数据分布. 大多数采样策略都可以被统一表示成如下形式. 即采样一个数据点, 它来自于类别(j)的概率(p_j)可以被表示为:(p_j = frac{n^q_j}{Sigma^C_{i=1}n_i^q}). 注意, 这里是基于类进行的表示, 实际上对于每个单独的数据而言, 他们的采样过程可以看作是一个两阶段的过程, 即先对(C)个类进行自定义采样, 再对类内部的数据均匀采样. 这里的包含了一个参数(q in [0, 1]). 用以调制不同类的采样概率, 根据它的不同取值, 从而可以划分为多种情形:
- Instance-balanced sampling: 这是最通常的采样数据的方式, 每个训练样本都是等概率被选择. 此时(q=1). 来自特定类别的数据点被采样的概率(p^{IB})成比例与该类别的容量.
- Class-balanced sampling: 对于不平衡的数据集, Instance-balanced sampling是次优的, 因为模型会欠拟合少样本类, 导致更低的准确率, 尤其是对于平衡的测试集. 而Class-balanced sampling已经被用来缓解这一差异. 在这种情况下, 每个类别会被强制等概率的被选择. 此时有(q = 0), 即直接抹平了类内数据量的影响. 所有类都有(p^{CB} = 1/C). 对于实际中, 该策略可以可看作是两阶段采样过程, 第一步各个类被从类别集合中均匀采样, 第二部, 类内样本被均匀采样.
- Square-root sampling: 一些其他的采样策略略同样被探索, 普遍使用的变体是平方根采样, 这时(q=1/2).
- Typically, a class-balanced loss assigns sample weights inversely proportionally to the class frequency. This simple heuristic method has been widely adopted. However, recent work on training from large-scale, real-world, long-tailed datasets reveals poor performance when using this strategy. Instead, they use a "smoothed" version of weights that are empirically set to be inversely proportional to the square root of class frequency. (来自_Class-Balanced Loss Based on Effective Number of Samples_)
- Progressively-lalanced sampling: 最近一些方法尝试将前面的策略进行组合, 从而实现了混合采样策略. 实践中, 先在一些的epoch中使用实例平衡采样, 之后在剩余的epoch中切换为类平衡采样. 这些混合采样策略需要设置切换的时间点, 这引入了胃癌的超参数. 在本文中, 使用了一个"软化"版本, 即渐进式平衡采样. 通过使用一个随着训练epoch进度不断调整的插值参数来线性加权IB与CB的类别采样概率. 所以有(p^{PB}_j(t) = (1 - frac{t}{T}) p_j^{IB} + frac{t}{T} p_j^{CB}). 这里的(T)表示总的epoch数量.
作者基于ImageNet-LT的数据绘制了采样权重的比例图:
论文_Class-Balanced Loss Based on Effective Number of Samples_中的如下内容很好的说明了重采样存在的问题:
Inthe context of deep feature representation learning using CNNs, re-sampling may either introduce large amounts of duplicated samples, which slows down the training and makes the model susceptible to overfitting when oversampling, or discard valuable examples that are important for feature learning when under-sampling.
损失重加权
这部分内容实际上和本文的讨论相关性并不大, 所以作者们并没有太详细的梳理.
此外, 我们发现一些报告高性能的最新方法很难训练和重现, 并且在许多情况下需要广泛的、特定于数据集的超参数调整.
文章的实验表明配备适当的平衡的分类器的基线方法可以比最新的损失重加权的方法如果不是更好, 也最起码是同样好.
文章比较的一些最新的相关方法:
- Focal Loss: 针对目标检测任务提出. 通过减低简单样本的损失权重, 来平衡样本级别的分类损失. 它对对应于类别(y_i)的样本(x_i)的概率预测(h_i)添加了一个重加权因子((1 - h_i)^{gamma}, gamma > 0), 来调整标准的交叉熵损失:(mathcal{L}_{ ext{focal}} := (1 - h_i)^gamma mathcal{L}_{ ext{CE}} = -(1 - h_i)^gamma ext{log}(h_i)). 整体的作用就是对于有着大的预测概率的简单样本施加更小的权重, 对于有着较小预测概率的困难样本施加更大的权重.
- Focal Loss的类平衡变体: 对于来自类别(j )的样本使用类平衡系数来加权. 这可以用来替换原始FocalLoss中的alpha参数. 所以该方法 (解析可见:https://www.cnblogs.com/wanghui-garcia/p/12193562.html) 可以看做一个基于有效样本数量的概念的基础上, 明确地在focal loss中设置alpha的方式. (Class-Balanced Loss Based on Effective Number of Samples: https://github.com/richardaecn/class-balanced-loss)
- Label-distribution-aware margin(LDAM)loss (https://arxiv.org/pdf/1906.07413.pdf): 鼓励少样本类由更大的边界, 并且他们的最终的损失形式可以表示为一个有着强制边界的交叉熵损失: (mathcal{L}_{ ext{LDAM}} := -logfrac{e^{hat{y}_j - Delta_j}}{e^{hat{y}_j - Delta_j} + Sigma_{c e j} e^{hat{y}_c}}). 这里的(hat{y})是logits, 而(Delta_j propto frac{1}{n_j^{1/4}})是class-aware margin. (关于softmax损失的margin的一些介绍:Softmax理解之margin - 王峰的文章 - 知乎https://zhuanlan.zhihu.com/p/52108088)
长尾识别的分类学习
当在平衡数据集上学习分类模型的时候, 分类器被和用于提取表征的模型通过交叉熵损失一同联合训练. 这实际上也是一个长尾识别任务的典型的基线设定. 尽管存在不同的例如重采样、重加权或者迁移表征的方法被提出, 但是普遍的范式仍然一致, 即分类器要么与表征学习一起端到端联合学习, 要么通过两阶段方法, 其中第二阶段里, 分类器和表征学习通过类平衡采样的变体进行联合微调.
本文将表征学习从分类中分离出来, 来应对长尾识别.
所以下面展示了一些文中用到的学习分类器的方法, 旨在矫正关于头部和尾部类的决策边界, 这主要通过使用不同的采样策略, 或者其他的无参方法(例如最近邻类别均值分类器)来微调分类器. 同样也考虑了一些不需要额外重新训练的方法来重新平衡分类器权重, 这展现了不错的准确率.
- Classifier Re-training (cRT). 这是一种直接的方法, 其通过使用类别平衡采样来重新训练分类器. 即, 保持表征学习模型固定, 随机重新初始化并且优化分类器权重和偏置, 使用类别平衡采样重新训练少量的epoch.
- Nearest Class Mean classifier (NCM). 另一种常用的方法是首先在训练集上针对每个类计算平均特征表征, 在L2归一化后的均值特征上, 执行最近邻搜索, 基于预先相似度, 或者基于欧式距离. 尽管这样的设定很简单, 但是却也是一个很强的baseline模型. 在文中的实验中, 余弦相似度通过内含的归一化缓解了权重不平衡问题.
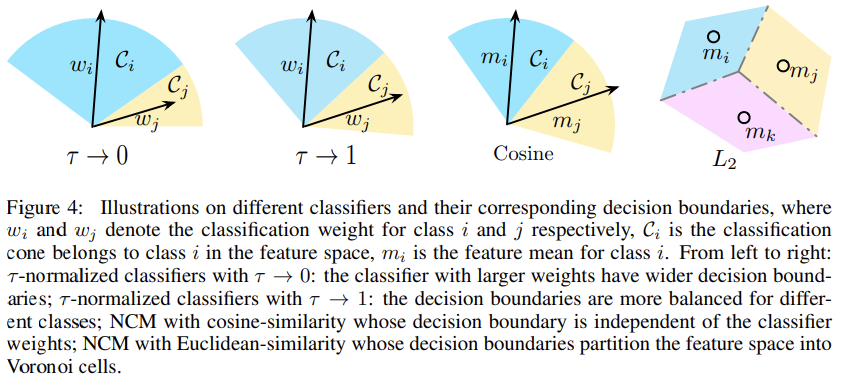
- ( au)-normalized classifier (( au)-normalized).
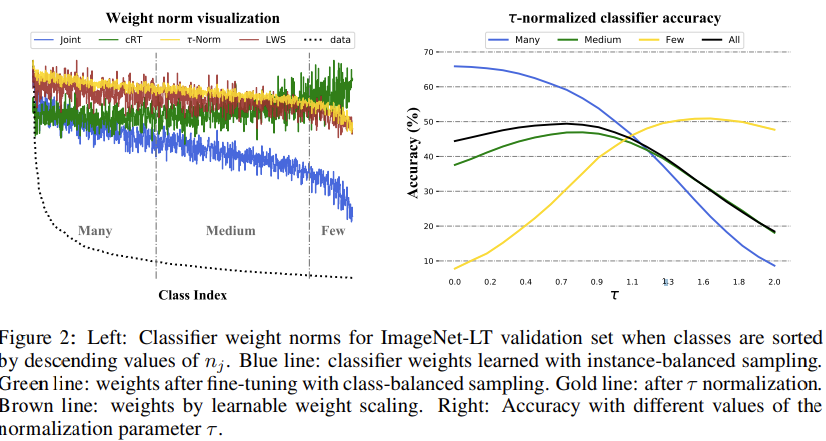
- 这里探究了一种有效的方法来重平衡分类器的决策边界, 这受启发与一种经验性的观察, 即, 在使用实例平衡采样联合训练之后, 权重范数(||w_j||)与类别容量是相关的. 然而在使用类平衡采样微调分类器之后, 分类器权重的范数趋向于更加相似(从图2左侧可以看出来, 类平衡采样微调后的模型的权重范数微调后缺失相对平缓了许多).
- 受这样的观察的启发, 作者们考虑通过( au)-normalization直接调整分类器的权重范数来修正决策边界的不平衡. 这里让(mathbf{W} = {w_j} in mathbb{R}^{d imes C}, w_j in mathbb{R}^d), 表示对应于各个类(j)的分类权重集合. 这里放缩权重来得到归一化形式:( ilde{mathbf{W}} ={ ilde{w}_j}, ilde{w}_i = frac{w_i}{||w_i||^{ au}}), 这里的( au)是一个归一化温度的超参数. 并且分母使用的是L2范数. 当( au = 1), 分式转化为L2归一化, 而当其为0时, 没有了归一化处理. 这里经验性的选择( au in (0, 1)), 以至于圈中可以被平滑的修正.
- 在这样的归一化处理之后, 分类的logits则可以表示为, 即使用归一化后的线性分类器来处理提取得到的表征(f(x; heta)). 注意这里去掉了偏置项, 因为其对于logits和最终的预测的影响是可以忽略的.
- 这里参数tau使用验证集来网格搜索:In our submission, tau is determined by grid search on a validation dataset. The search grid is [0.0, 0.1, 0.2, ..., 1.0]. We use overall top-1 accuracy to find the best tau on validation set and use that value for test set.
- Learnable weight scaling (LWS)另一种解释( au)-normalization的方式是将其看做一种保持分类器权重方向的同时, 对权重幅度重新放缩, 这可以被重新表述为:( ilde{w}_i = f_i * w_i, f_i = frac{1}{||w_i||^ au}). 尽管对于( au)-normalization的超参数可以通过交叉验证来选择, 但是作者们进一步尝试将放缩因子(f_i)在训练集上学习, 同时使用类平衡采样. 这样的情况下, 保持表征和分类器权重都固定, 只学习放缩因子.

来自附录
注意上面提到的几种在第二阶段中调整分类器的策略中, 涉及到重新训练和采样策略的只有cRT和LWS, 且都是用的类别平衡重采样. 而NCM和( au)-normalized都是不需要考虑第二阶段的重采样策略的, 因为他们不需要重新训练.
实验细节
实验设置
数据集
- Places-LT and ImageNet-LT are artificially truncated from their balanced versions (Places-2 (Zhou et al., 2017) and ImageNet-2012 (Deng et al., 2009)) so that the labels of the training set follow a long-tailed distribution.
- Places-LT contains images from 365 categories and the number of images per class ranges from 4980 to 5.
- ImageNet-LT has 1000 classes and the number of images per class ranges from 1280 to 5 images.
- iNaturalist 2018 is a real-world, naturally long-tailed dataset, consisting of samples from 8, 142 species.
评估方式
- After training on the long-tailed datasets, we evaluate the models on the corresponding balanced test/validation datasets and report the commonly used top-1 accuracy over all classes, denoted as All.
- To better examine performance variations across classes with different number of examples seen during training, we follow Liu et al. (2019) and further report accuracy on three splits of the set of classes: Many-shot (more than 100 images), Medium-shot (20∼100 images) and Few-shot (less than 20 images). Accuracy is reported as a percentage.
实现细节
- We use the PyTorch (Paszke et al., 2017) framework for all experiments.
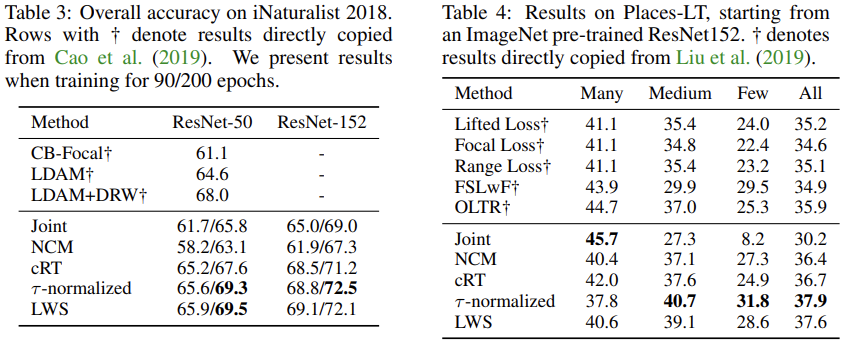
- For Places-LT, we choose ResNet-152 as the backbone network and **pretrain it on the full ImageNet-2012 dataset **, following Liu et al. (2019).
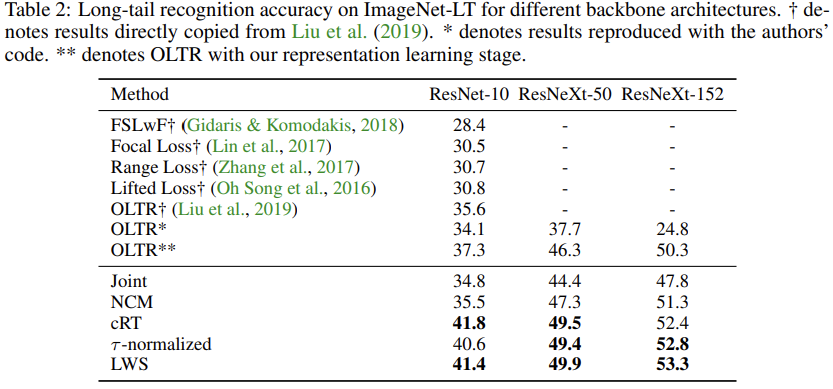
- On ImageNet-LT, we report results with ResNet-{10, 50, 101, 152} (He et al., 2016) and ResNeXt-{50, 101, 152}(32x4d) (Xie et al., 2017) but mainly use ResNeXt-50 for analysis.
- Similarly, ResNet-{50, 101, 152} is also used for iNaturalist 2018.
- For all experiements, if not specified, we use SGD optimizer with momentum 0.9, batch size 512, cosine learning rate schedule (Loshchilov & Hutter, 2016) gradually decaying from 0.2 to 0 and image resolution 224×224.
- In the first representation learning stage, the backbone network is usually trained for 90 epochs. (这里都使用Instance-balanced sampling for representation learning)
- In the second stage, i.e., for retraining a classifier (cRT), we restart the learning rate and train it for 10 epochs while keeping the backbone network fixed.
具体实验
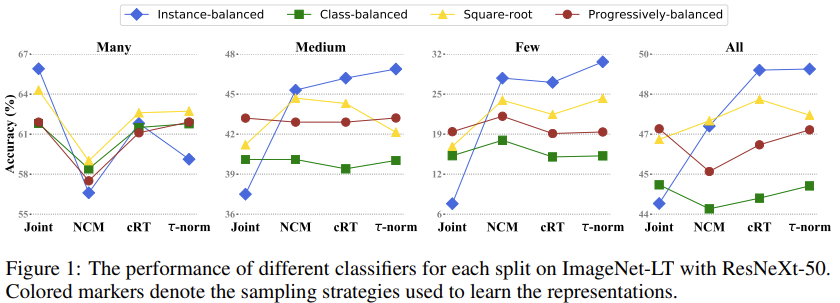
要注意, 这个图中的采样策略都是在指代表征学习过程中使用的采样策略.
联合训练时不同采样策略的效果比较
来自附录中的补充图表
For the joint training scheme (Joint), the linear classifier and backbone for representation learning are jointly trained for 90 epochs using a standard cross-entropy loss and different sampling strategies, i.e., Instance-balanced, Class-balanced, Square-root, and Progressively-balanced.
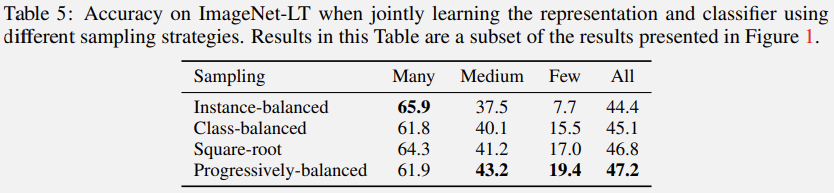
图1和表5中的Joint之间的对比可以看出来:
- 使用更好的采样策略可以获得更好的性能. 联合训练中不同采样策略的结果验证了试图设计更好的数据采样方法的相关工作的动机.
- 实例平衡采样对于many-shot而言表现的更好, 这是因为最终模型会高度偏向与这些many-shot类.
解耦学习策略的有效性
比对图1, 可以知道, 这里在第二阶段使用的是cRT策略来调整模型
For the decoupled learning schemes, we present results when learning the classifier in the ways, i.e., re-initialize and re-train (cRT), Nearest Class Mean (NCM) as well as τ-normalized classifier.
从图1中整体可以看出来:
- 在大多数情况下, 解耦训练策略都是要好于整体训练的.
- 甚至无参数的NCM策略都表现的不是很差. 其整体性能主要是由于many-shot时表现太差而拉了下来.
- 不需要额外训练或是采样策略的NCM和( au)-normalized策略都表现出了极具竞争力的性能. 他们的出色表现可能源于他们能够自适应地调整many-/medium-/few-shot类的决策边界(如图4所示).
- 在所有解耦方法中, 当涉及到整体性能以及除了many-shot之外的所有类别拆分时, 我们都会看到, 实例平衡采样提供了最佳结果. 这特别有趣, 因为它意味着数据不平衡可能不是一个会影响学习高质量表示的问题.实例平衡采样可以提供最通用的表征.
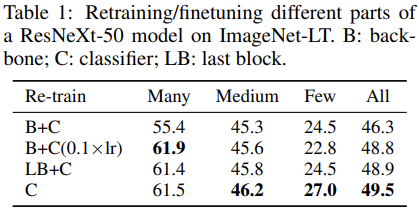
为了进一步对比, 表1中列举了将backbone与线性分类器联合微调时模型(B+C和B+C(0.1xlr))、仅微调backbone最后一个block(LB+C), 或者固定backbone而重训练分类器(C)的几种情形.
表1中可以看出来:
- 微调整个模型性能最差.
- 固定backbone, 效果最好(因为是长尾分布的任务, 所以更多关注整体效果和少样本类的效果).
- 解耦训练的设定, 是很适用于长尾识别任务的.
不同平衡分类器策略的效果比较
在图2 (左) 中, 我们凭经验显示了所有分类器的权重向量的L2范数, 以及相对于训练集中的实例数降序排序的训练数据分布.
我们可以观察到:
- 联合分类器 (蓝线) 的权重范数与相应类的训练实例数呈正相关.
- more-shot类倾向于学习具有更大幅度的分类器. 如图4所示, 这在特征空间中产生了更宽的分类边界, 允许分类器对数据丰富的类具有更高的准确性, 但会损害数据稀缺的类.
- τ-normalized分类器 (金线) 在一定程度上缓解了这个问题, 它提供更平衡的分类器权重大小.
- 对于re-training策略(绿线), 权重几乎是平衡的, 除了few-shot类有着稍微更大的权重范数.
- NCM方法会在图中给出一条水平线, 因为在最近邻搜索之前平均向量被L2归一化了.
- 在图2 (右) 中, 我们进一步研究了随着τ-normalization分类器的温度参数τ的变化时, 性能如何变化. 该图显示随着τ从0增加, 多样本类精度急剧下降, 而少样本类精度急剧增加.
与现有方法的对比
额外的实验
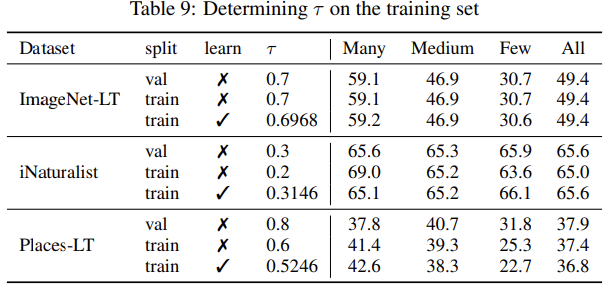
- ( au)的选择: 当前的设置中, 参数tau是需要验证集来确定, 这在实际场景中可能是个缺点. 为此, 作者们设计了两种更加自适应的策略:
- 从训练集上寻找tau: 表9中可以看到, 最终在测试集合上的效果是很接近的.
-
We achieve this goal by simulating a balanced testing distribution from the training set.
- We first feed the whole training set through the network to get the top-1 accuracy for each of the classes.
- Then, we average the class-specific accuracies and use the averaged accuracy as the metric to determine the tau value.
-
As shown in Table 9, we compare the τ found on training set and validation set for all three datasets. We can see that both the value of τ and the overall performances are very close to each other, which demonstrates the effectiveness of searching for τ on training set.
-
This strategy offers a practical way to find τ even when validation set is not available.
-
- 从训练集上学习tau: We further investigate if we can automatically learn the τ value instead of grid search.
- To this end, following cRT, we set τ as a learnable parameter and learn it on the training set with balanced sampling, while keeping all the other parameters fixed (including both the backbone network and classifier).
- Also, we compare the learned τ value and the corresponding results in the Table 9 (denoted by “learn” = ✓). This further reduces the manual effort of searching best τ values and make the strategy more accessible for practical usage.
- 从训练集上寻找tau: 表9中可以看到, 最终在测试集合上的效果是很接近的.
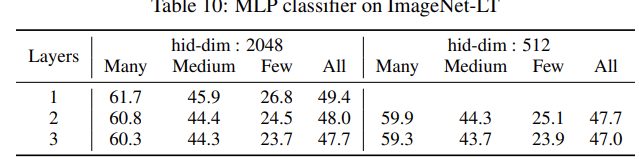
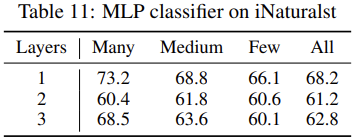
- MLP分类器和线性分类器的比较: We use ReLU as activation function, set the batch size to be 512, and train the MLP using balanced sampling on fixed representation for 10 epochs with a cosine learning rate schedule, which gradually decrease the learning rate to zero.
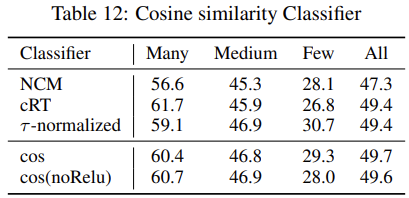
- 使用余弦相似度计算来替换线性分类器: We tried to replace the linear classifier with a cosine similarity classifier with (denoted by "cos") and without (denoted by "cos(noRelu)") the last ReLU activation function, following [Dynamic few-shot visual learning without forgetting].
实验小结
尽管抽样策略在共同学习表征和分类器时很重要, 实例平衡采样提供了更多可推广的表示, 在适当地重新平衡分类器之后, 无需精心设计的损失或memory单元, 即可实现最先进的性能.
参考链接
- 论文:https://arxiv.org/pdf/1910.09217.pdf
- 代码:https://github.com/facebookresearch/classifier-balancing
- 《Decoupling Representation and Classifier》笔记 - 千佛山彭于晏的文章 - 知乎https://zhuanlan.zhihu.com/p/111518894
- Long-Tailed Classification (2) 长尾分布下分类问题的最新研究 - 青磷不可燃的文章 - 知乎https://zhuanlan.zhihu.com/p/158638078
- openreview页面:https://openreview.net/forum?id=r1gRTCVFvB¬eId=SJx9gIcsoS
- 基于GRU和am-softmax的句子相似度模型 - 科学空间|Scientific Spaces:https://kexue.fm/archives/5743