研究MapD有一个多月了,是时候总结一下如何进行MaPD的部署了。
关于MapD有部署主要是参考了以下的两个链接,这里重新整理总结一下,一是为了以后自己看着方便,一是说一下自己的部署的过程中遇到的问题,如果有人也在研究这一方向,欢迎一起探讨、一起进步。另:本人只是新手,如有错误,欢迎指正。
链接1:https://www.leiphone.com/news/201705/jPar4mkGAnXCgLQz.html,原链接为:http://tech.marksblogg.com/compiling-mapd-ubuntu-16.html
链接2:https://www.qcloud.com/community/article/451419
以上的两个链接都是比较官方的安装方法。其中链接1使用的是MapD公布在GitHub上的方法进行安装的,使用的是MapD的源代码文件,包括了从编译到运行的全部过程。
链接2使用的是MapD公布在自己官网上的方法进行安装的,使用的是经过编译的文件,方法相对简单一些。
我在Ubuntu上使用链接1的方法能够正常完成安装。在Centos上使用链接2的方法也能够完成安装。我同事在Ubuntu上使用链接2的方法也能完成安装。都是经过实测的。
这里链接2要注意的是:1.安装完成CUDA后要重启一下,否则完成的MapD只能布置在cpu上这一种模式。
2.如果要对大的数据操作的话,不要把数据存储在/var/lib/mapd,因为它和root是一个扇区。建议建在/home/mapd-data中。
3.systemctl r 用法如下:以mysql为例:
启动mysql服务:systemctl start mysqld.service
停止mysql服务:systemctl stop mysqld.service
重启mysql服务:systemctl restart mysqld.service
查看mysql服务当前状态:systemctl status mysqld.service
设置mysql服务开机自启动:systemctl enable mysqld.service
停止mysql服务开机自启动:systemctl disable mysqld.service
下面详说使用方案一的方法:
我用的是服务器,CPU是ppcle64,GPU是4个p100,系统是Ubuntu 16.0.1。目前MapD只推荐在Ubuntu和Centos上安装。
安装 MapD's 附件
我会从在 apt 的资源列表中,启用资源库源代码开始。
$ sudo sed -i --
's/# deb-src/deb-src/g'
/etc/apt/sources.list
之后刷新 apt 资源列表,安装 39 个包。
$ sudo apt update
$ sudo apt install
autoconf
autoconf-archive
binutils-dev
bison++
bisonc++
build-essential
clang-3.8
clang-format-3.8
cmake
cmake-curses-gui
default-jdk
default-jdk-headless
default-jre
default-jre-headless
flex
git-core
golang
google-perftools
libboost-all-dev
libcurl4-openssl-dev
libdouble-conversion-dev
libevent-dev
libgdal-dev
libgflags-dev
libgoogle-glog-dev
libgoogle-perftools-dev
libiberty-dev
libjemalloc-dev
libldap2-dev
liblz4-dev
liblzma-dev
libncurses5-dev
libpng-dev
libsnappy-dev
libssl-dev
llvm-3.8
llvm-3.8-dev
maven
zlib1g-dev
下一步,我会下载安装 8.0 版本的英伟达 CUDA Toolkit。它会安装显卡驱动,并取代所有已存在的驱动(这里需要注意!!!看一下自己的CPU架构方式,比如他这里用的是amd64,而我用的是X86-64,可以根据他的网址去看一下,然后相应的修改)。
$ curl -L -O https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb
$ sudo dpkg -i cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb
$ sudo apt update
$ sudo apt install cuda
新驱动装好之后,重启系统(最好看一下是不是能正常联网,我用的服务器连不上网了,找了半天才的到毛病。不过这和MapD的安装无关,是我服务器的事,只是随便提一下)。
$ sudo reboot
系统备份之后,英伟达的系统管理界面应该显示对你的驱动和 GPU 的检测诊断。(在这里能看到各个GPU的运行状态)
$ nvidia-smi
MapD 利用 Thrift 在客户和服务器之间进行交流。我将从资源哪里安装它。0.10.0 版本的 Thrift 与 MapD 的兼容性是很不错的。
$ sudo apt build-dep thrift-compiler
$ curl -O http://apache.claz.org/thrift/0.10.0/thrift-0.10.0.tar.gz
$ tar xvf thrift-0.10.0.tar.gz
$ pushd thrift-0.10.0
$ ./configure
--with-lua=no
--with-python=no
--with-php=no
--with-ruby=no
--prefix=/usr/local/mapd-deps
$ make -j $(nproc)
$ sudo make install
$ popd
Folly 是一个有 11 个组件的 C++ 算法库。它由 Facebook 发布,在 MapD 源代码中到处都有使用。下面是从资源编译、创建该算法库的步骤:(这个地方如果你的gcc版本不够的话,需要自己升级一下)
$ curl -O -L https://github.com/facebook/folly/archive/v2017.04.10.00.tar.gz
$ tar xvf v2017.04.10.00.tar.gz
$ pushd folly-2017.04.10.00/folly
$ autoreconf -ivf
$ ./configure
--prefix=/usr/local/mapd-deps
$ make -j $(nproc)
$ sudo make install
$ popd
Bison 是 MapD 生成 SQL 解析器(parser)的两个库之一。下面是编译、创建步骤:
$ curl -O -L https://github.com/jarro2783/bisonpp/archive/1.21-45.tar.gz
$ tar xvf 1.21-45.tar.gz
$ pushd bisonpp-1.21-45
$ ./configure
$ make -j $(nproc)
$ sudo make install
$ popd
下面,在 MapD 编译之前,要确保我们用的是想要的那个 LLVM 二进制版本。
$ for BIN in llvm-config llc clang clang++ clang-format
do
sudo update-alternatives
--install
/usr/bin/$BIN
$BIN
/usr/lib/llvm-3.8/bin/$BIN
1
done
我会用如下代码,在环境变量中添加可执行文件和库文件的路径。(下面的路径是对应的,如果默认是安装的话,不需要更改。如果是自己新建文件夹后安装的,则需要改成相应的路径)
$ sudo vi /etc/profile.d/mapd-deps.sh
LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
LD_LIBRARY_PATH=/usr/lib/jvm/default-java/jre/lib/amd64/server:$LD_LIBRARY_PATH
LD_LIBRARY_PATH=/usr/local/mapd-deps/lib:$LD_LIBRARY_PATH
LD_LIBRARY_PATH=/usr/local/mapd-deps/lib64:$LD_LIBRARY_PATH
PATH=/usr/local/cuda/bin:$PATH
PATH=/usr/local/mapd-deps/bin:$PATH
export LD_LIBRARY_PATH PATH
$ sudo chmod +x /etc/profile.d/mapd-deps.sh
$ source /etc/profile.d/mapd-deps.sh
编译 MapD
我会复制 MapD 的核心源代码资源库,然后检查 21fc39 commit。只用比较好的发布版本或者 master branch 是一个好主意。但出于让这些指令前后一致的考虑,这里的代码实现只针对那一特定的 commit。
$ git clone https://github.com/mapd/mapd-core.git
$ cd mapd-core
$ git checkout 21fc39
我会为 MapD 创建一个 build 文件夹,在开启修补漏洞的前提下编译源代码。
$ cd ~/mapd-core/build
$ cmake -DCMAKE_BUILD_TYPE=debug ..
$ make -j $(nproc)
运行 MapD
经过 MapD 的二进制编译,我会创建一个数据文件夹,初始化,然后设置 MapD 的数据库服务器和它的 Immerse 网络服务器。(这是一种临时的方式,如果MapD一直使用的话,推荐使用链接2中的二.3的方式安装)
$ mkdir ~/mapd-data
$ bin/initdb --data ~/mapd-data
$ bin/mapd_server --data ~/mapd-data &
$ bin/mapd_web_server &
请注意,这些服务与所有网络界面绑定。所以,请确认 TCP 端口 9090、9091 和 9092,对你不想访问的系统用防火墙阻止。Immerse 网络服务器应该在 TCP 端口 9092 上。
$ open http://127.0.0.1:9092/
在 Immerse UI 的顶端,有一个到 SQL 编辑器的链接。哪里,你可以在 MapD 环境里运行 SQL。注意只有检索文本框里的第一行 SQL 命令会被执行,所以下面的三个请求每次单个运行。
CREATE TABLE testing (
pk INTEGER
);
INSERT INTO testing (pk)
VALUES (123);
SELECT *
FROM testing
LIMIT 1;
如果你从命令行与 MapD 交互,下面的代码会设置它们的 CLI,并使用默认证书和数据库连接到 MapD 服务器。(这里指的是MapD的mapdql接口,和sql的命令行是一样的,可以直接输入指令)
$ bin/mapdql -p HyperInteractive
这里可以用链接2的方法进行验证:
进入mapd的安装目录,可以看到里面有一个可执行文insert_sample_data,执行这一文件:
./insert_sample_data
然后你会看到下面的提示:
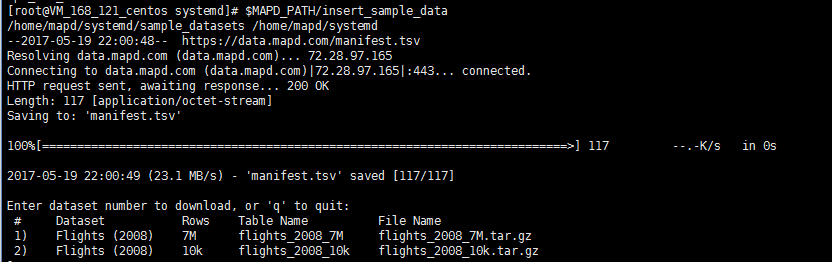
1:里面有7百万行数据(这里原博主算错了,这是一个百万级的数据库文件)
2:里面有1万行数据
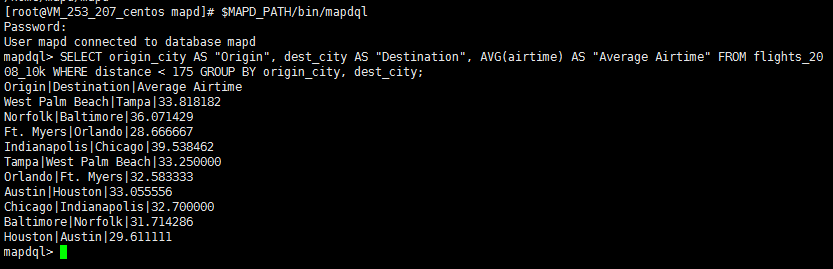
然后输入查询语句开始查询:
SELECT origin_city AS "Origin", dest_city AS "Destination", AVG(airtime) AS
"Average Airtime" FROM flights_2008_10k WHERE distance < 175 GROUP BY origin_city,
dest_city;
如果看到以下内容说明成功:
这里使用另一个终端访问服务器,然后使用以下语句,可以看到mapd_server部署在每个GPU上,并且可以实时检测GPU的各种使用率:
watch -n 0.1 nvidia-smi
学习更多设置数据库的操作,请查询 MapD 官方使用指南以及 GitHub 页面。