最近在做与图像降噪有关的毕设,老师让看与denosing network 有关的论文, 从最普通的神经网络, 到卷积神经网络,残差神经网络, 再到DnCNN,把这些网络的结构, 降噪原理总结如下
1)MLP (multi layer perceptron):
结构 : 多层感知机实际上是一个非线性函数, 通过多个隐藏层, 将输入的向量值映射到输出向量。 例如一个含有两层隐藏层的MLP 可以写成
f(x) = b3 +W3tanh(b2+W2tanh(b1+W1x))
权重W1, W2, W3, 和偏重b1, b2, b3,构成了多层感知机的参数,并对每对参数施加tanh函数。隐藏层的数目以及层的大小确定了MLP的结构。 例如(256,2000, 1000, 10)-MLP 有两个隐藏层, 输入层的维度为256,第一个隐藏层的输出向量v1=tanh(b1+W1x) 的维度是2000, 第二个隐藏层的输出向量v2=tanh(b2+W2v1) 的维度是1000, 输出层结果f(x)的维度是10. 一般我们也把多层感知机叫做前馈神经网络。
降噪原理 : 我们要构建的MLP 能够将输入的带噪音的图片映射到没有噪音的干净图片, 通过在一组干净图片和对应的带噪音的图片上进行训练来更新MLP的参数。具体来说,随机从数据集中选取一张干净的图片y, 并生成y带有噪音的图片x, 用backpropagation算法,通过最小化f(x) 和无噪音图片y之间的误差来更新MLP的参数
为了提高后向传播算法效率, 一般我们会应用以下一些常见的处理方法
(1)Data Normalization: 把像素值由0-255映射到0-1, 同时均值为0, 方差为1
(2)Weight Initialization: 初始权重均值为0, 方差为σ=√N, 其中N为对应层的单元的数目
(3)Learning rate division: 在每一层, 我们把学习率除以N, 其中N 为对应层的单元(神经元)的数目。 这样我们就可以在不改变学习率的情况下更改隐藏层的神经元的数目
2)CNN(Convolutional Neural Network): 卷积神经网络经常被应用到物体识别领域,输入一张图片,输出一个二进制的预测结果。 但是在这里我们输入一个还有噪音的图片, 输出是一张干净的图片。
结构:卷积神经网络是一系列线性过滤和非线性转换操作。 输入和输出层包含一个或多个图片, 而中间层包含隐藏的神经元和特征映射, 特征图是这个算法中间步骤的计算结果。下图是用来进行图像降噪的神经网络结构。该网络有四个隐藏层,在每个隐藏层都有24个特征映射,在第2,3,4层,每层的特征映射都与上一层随机的八个特征映射相连。每个箭头代表了一次与5*5的过滤器进行的卷积操作. 因此整个神经网络包含15697个参数,需要进行642此卷积操作进行forward pass
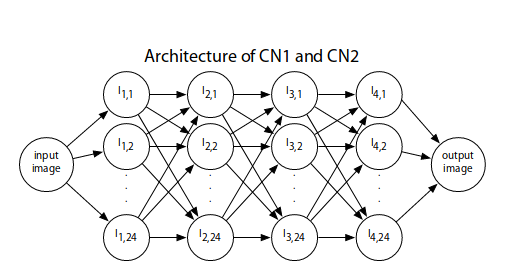
降噪原理:首先为了训练卷积神经网络我们需要把图像降噪任务转化为一个学习问题,因为我们已经假设我们在数据库中获得的都是干净的没有噪音的图片x, 那么在训练过程中我们需要一个给图片添加噪音的步骤n(x). 将卷积神经网络看成含有参数Φ的函数FΦ, 我们就可以通过最小化error ∑i(xi-FΦ(n(xi)))来更新网络中的参数
有一点需要注意,因为整个训练集含有数百万个像素,所以在整个训练集上使用forward and backwardpass会非常的消耗时间,我们在这里选择Stochastic online gradient learning,从训练集中选择一小部分数据集,然后用他们梯度的平均值执行一次更新。具体来说,通过在6张训练集的图片上随即选取6*6 patches来进行梯度更新 。
3) Resnet 残差神经网络:
首先我们要明白残差神经网络是为了解决什么问题。研究发现随着网络层数的增加,其性能不但没有提升,反而出现了显著的退化,为了更直观的理解这个问题,我用两个神经网络来解释,左边的是shallow network, 右边的是deeper network,(通过在shallow network上添加layer得到)
1)最坏的情况:deeper model的前几层可以被shallow model代替,且deeper model的剩下基层相当于单位映射(单位映射的输入等于输出)
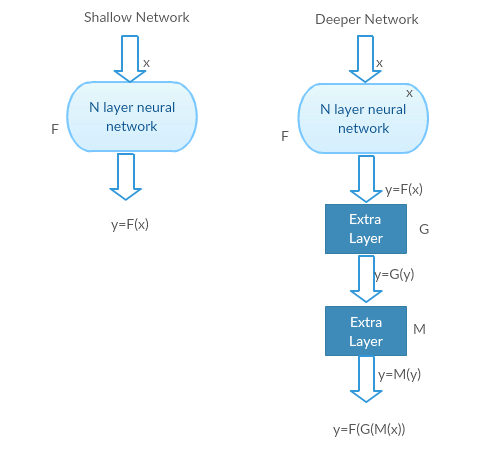
G, M 是单位映射(Identity function), 这两个网络的输出结果相同
2)好一点的情况: deeper model比shallow model有更好的预测值,和更小的误差
由上我们可以看出,在最坏的情况下,shallow model 和deeper model得到相同的精确值, 在好一点的情况下,deeper model 的结果要更好, 但是目前的实验表明deeper model表现并不好, 也就是说使用deeper model性能会下降, 而Deep Residual learning framework 就是用来解决这个问题
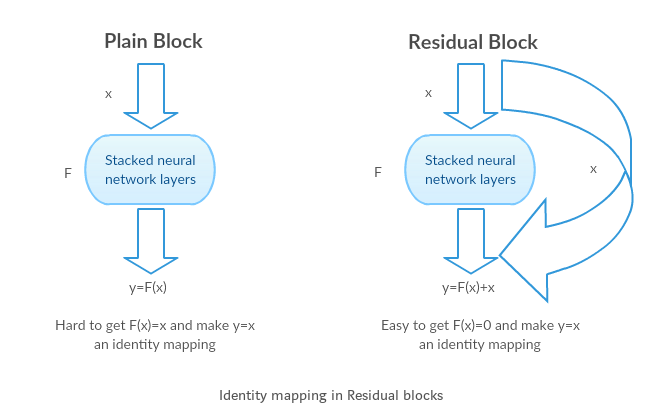
以前为了学习从x到y的映射我们通常要直接学习深度网络H(x), 但是resnet中定义了残差函数F(x) = H(x)-x, F(x)代表了多个卷积层级联,为深度网络中的某个隐藏层, x代表了单位映射. .残差单元的输出由多个卷积层级联的输出和输入元素间相加(保证卷积层输出和输入元素维度相同),再经过ReLU激活后得到。将这种结构级联起来,就得到了残差网络。典型网络结如下图所示。这里需要指出,作者假设优化残差函数比直接优化H(x)要更容易
如果单位映射已经处于最优状态, 那我们可以直接让残差等于0,F(x) = 0, 而不需要在把x放到一个单位映射中去(如deeper model中G, M). 而且让F(x) = 0比让F(x ) = x更容易解决.
在Beyond a Gaussian Denoiser: Residual Learningof Deep CNN for Image Denoising, 这篇论文中作者结合了Resnet进行图像降噪, 其网络结构如下
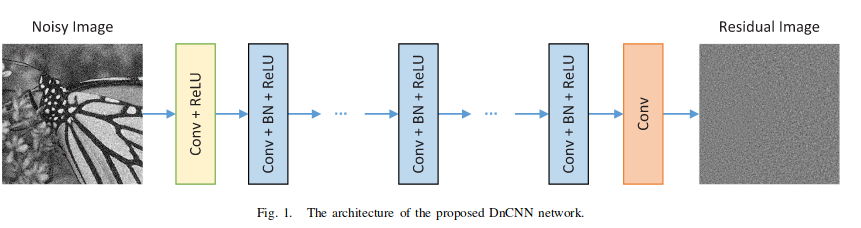
输入是含有噪音的图片y,输出是图片中的噪音v, 干净的图片x=y-v
对于上边这个网络,既可以用他进行直接降噪,F(y)即为预测的干净图片 ,也可以用他进行残差映射,得到R(y), 也就是图片的噪音。y-R(y)即为预测的干净图片 我们使用残差学习的原因就在于当原始映射接近于单位映射时, 使用残差映射更容易优化。在这里我们观察到的含有噪音的图片y其实跟干净图片x是非常接近的,尤其是当噪音程度非常低的时候。这里F(y)比R(y)更接近于单位映射,所以我们使用R(y)。