这段时间接了个需求,需要在我目前负责的数据系统上加个接口,主要是实现用户行为的记录。前端对接的项目主要有公司的PC,WAP,WEIXIN,APP等,每个端大概有两台左右的负载。因为目前我的这个项目主要是面向内部,负责数据运营相关的内容,是个单体项目。如果线上各个接入点不做限制,瞬间大量的并发进入必然会导致目前项目的崩溃,其他的功能也无法正常使用。
1、需求分析
通过前期的需求分析,目前线上系统无法进行限流处理,所以最终解决问题还是要从接口入手。
目前我对接口的处理有两种实现方案:
- 可以利用MQ实现消息的错峰,将消息发送到MQ服务器。
- 实现对接口的隔离限流,避免当前接口对其他功能的影响。
其实我认为最好的实现方案就是第一种了,可以保证消息的准确送达,避免并发资源的占用。不过,因为公司条件的限制暂时不能新增中间件,所以只能在现有系统上进行改造,最后只能采用第二种方法了。
2、Hystrix的简单介绍
官方的定义就不说了,这里简单说下我的理解。Hystrix作为断路器主要是实现对服务的容错保护,简单来说就是服务隔离、服务降级、服务熔断,服务限流这几项。
举个常见的例子,当你某宝【抢购】一个产品时,经常会弹出[网络错误,请重试。]的提示,这种时候是真的网络问题吗?显示不是。这种情况下其实是对调用的接口进行了降级处理,当降级的次数或比例达到一定的条件后,断路器就会直接打开,之后的访问就会直接降级,而不会判断是否降级了。达到对服务的容错保护以及给用户友好提示的目的。详细的流程可以看下图。
一般Hystrix的容错保护在微服务中是用在客户端,也就是调用方。而我这次实际上是用在了提供方,主要是前台的项目我无法控制,只能在接口上想方法了。目前我使用Hystrix的主要目的就是实现对服务的隔离和限流,而对降级和熔断反而不是特别的关心,当然实际的使用要结合场景。
因为一般Tomcat默认是一个线程池150个线程,如果单个热点接口的请求过多,就会造成其他功能没有线程可用甚至直接程序崩溃的问题。Hystrix的服务隔离主要有两种,常用的就是线程池隔离的方式,对热点接口建立单独的线程池避免对主程序的影响。另一种是信号量的方式,用的场景不是太多。两者的区别其实就是一个增大系统的开销,一个则直接限制了线程总的并发数,开销更小一些。
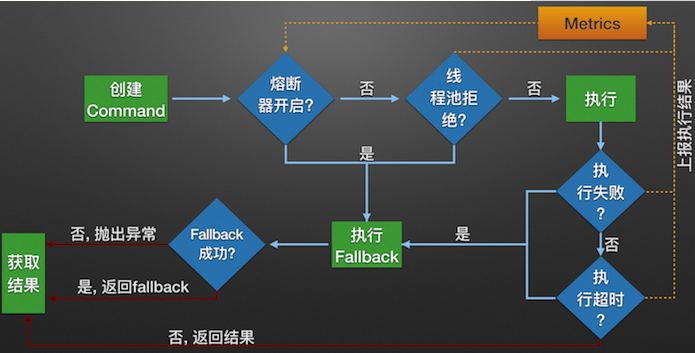
Hystrix服务调用逻辑图
3、项目中的应用实现
本文是在传统Spring项目中的应用,Springboot中的相关配置和依赖有稍许的不同。
maven依赖:
<!-- hystrix --> <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystrix-core</artifactId> <version>1.5.9</version> </dependency> <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystrix-metrics-event-stream</artifactId> <version>1.5.9</version> </dependency> <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystrix-javanica</artifactId> <version>1.5.9</version> </dependency>
在Spring的配置文件中配置Hystrix的切面信息
<bean id="hystrixAspect" class="com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect"></bean> <aop:aspectj-autoproxy />
主要是开启注解的AOP扫描,这里我们可以在这个类的源码中看到实现
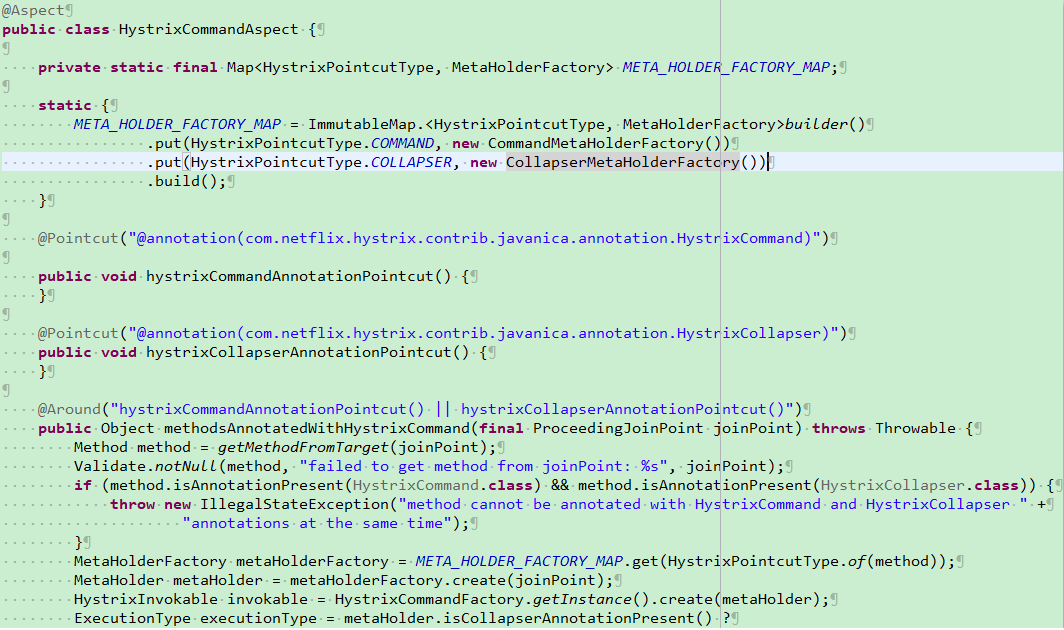
可以看到我们主要是通过这个类切面扫描Hystrix的相关注解,以达到接口处理前,提前执行Hystrix相关逻辑的代码。
/** * 提供客户行为接口 * */ @Controller @RequestMapping(value = "/test") public class BehaviorController { Logger logger = Logger.getLogger(BehaviorController.class); @Autowired private BehaviorService behaviorService; @RequestMapping(value="/addBehavior",method = RequestMethod.POST,produces = "application/json;charset=UTF-8") @ResponseBody @HystrixCommand(fallbackMethod = "fallback", threadPoolProperties = { @HystrixProperty(name = "coreSize", value = "20"), @HystrixProperty(name = "maxQueueSize", value = "100"), @HystrixProperty(name = "queueSizeRejectionThreshold", value = "20")}, commandProperties = { @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "30000"), @HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20") }) public String addBehavior(@RequestBody String parms) { //业务逻辑实现 return result; } public String fallback(@RequestBody String parms){ logger.info("fallback"); //失败的实现 return result; } }
注意:
请求的接口必须为public,fallback为降级的接口逻辑,可以为private,也可以为public。
但是要特别注意fallback方法的返回值和参数必须和请求方法相同。
另外需要说的是,当请求失败、被拒绝、超时或者断路器打开时,都会进入回退方法,但是进入回退方法并不意味着断路器已经被打开。
4、常用参数的介绍
|
参数 |
描述 |
默认值 |
|
execution.isolation.strategy |
隔离策略,有THREAD和SEMAPHORE THREAD - 它在单独的线程上执行,并发请求受线程池中的线程数量的限制 |
默认使用THREAD模式,以下几种场景可以使用SEMAPHORE模式: 只想控制并发度 外部的方法已经做了线程隔离 调用的是本地方法或者可靠度非常高、耗时特别小的方法(如medis) |
|
execution.isolation.thread.timeoutInMilliseconds |
超时时间 |
默认值:1000 在THREAD模式下,达到超时时间,可以中断 在SEMAPHORE模式下,会等待执行完成后,再去判断是否超时 设置标准: 有retry,99meantime+avg meantime 没有retry,99.5meantime |
|
execution.timeout.enabled |
HystrixCommand.run()执行是否应该有超时。 |
默认值:true |
|
fallback.isolation.semaphore.maxConcurrentRequests |
设置在使用时允许执行fallback方法的最大并发请求数 |
默认值:10 |
|
circuitBreaker.requestVolumeThreshold |
设置滚动时间窗中,断路器熔断的最小请求数 |
默认值:20 滚动窗口默认10s,即10s内失败请求达到20个,熔断器即打开 |
|
coreSize |
设置执行命令线程池的核心线程数。 |
默认值:10 |
|
maxQueueSize |
设置执行命令线程池的核心线程数。 |
默认值:-1 当设置为-1时,线程池使用SynchronousQueue实现的队列,否则将使用LinkedBlockingQueue实现的队列 |
|
queueSizeRejectionThreshold |
为队列设置拒绝阈值 |
默认值:5 当设置该参数后,即使队列没有达到最大值也能拒绝请求。 注意:当maxQueueSize属性为-1的时候,该属性不会生效 |
另外需要特别注意的是:fallback的属性maxConcurrentRequests,当请求达到了最大并发数时,后续的请求将会被拒绝并抛出异常(因为它已经没有后续的fallback可以被调用了),异常信息一般为com.netflix.hystrix.exception.HystrixRuntimeException: xxxxxxx fallback execution rejected.
更多参数见官方文档:https://github.com/Netflix/Hystrix/wiki/Configuration
另外附一个网友翻译的文档:https://blog.csdn.net/tongtong_use/article/details/78611225
5、接口测试
并发接口测试的方法很多,可以写代码,也可以用apache batch以及jmeter等工具。以常用的jmeter为例,测试本接口。
设置环境变量:
JMETER_HOME D:apache-jmeter-3.0
CLASSPATH %JMETER_HOME%libextApacheJMeter_core.jar;%JMETER_HOME%libjorphan.jar;%JMETER_HOME%lib/logkit-2.0.jar;
新建线程组:
设置并发参数:
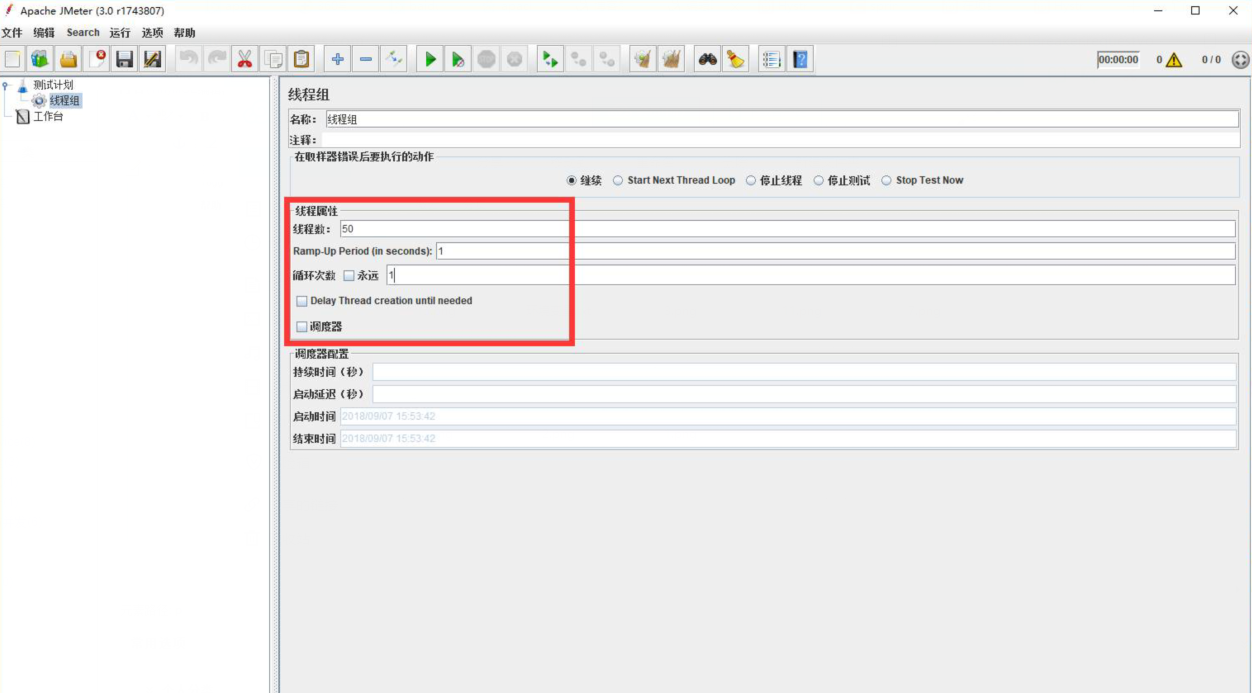
第一个参数为线程数,第二个参数为启动时间,第三个参数为请求次数。以上述配置为例即为1秒内启动50个线程,每个线程请求一次。
添加HTTP请求
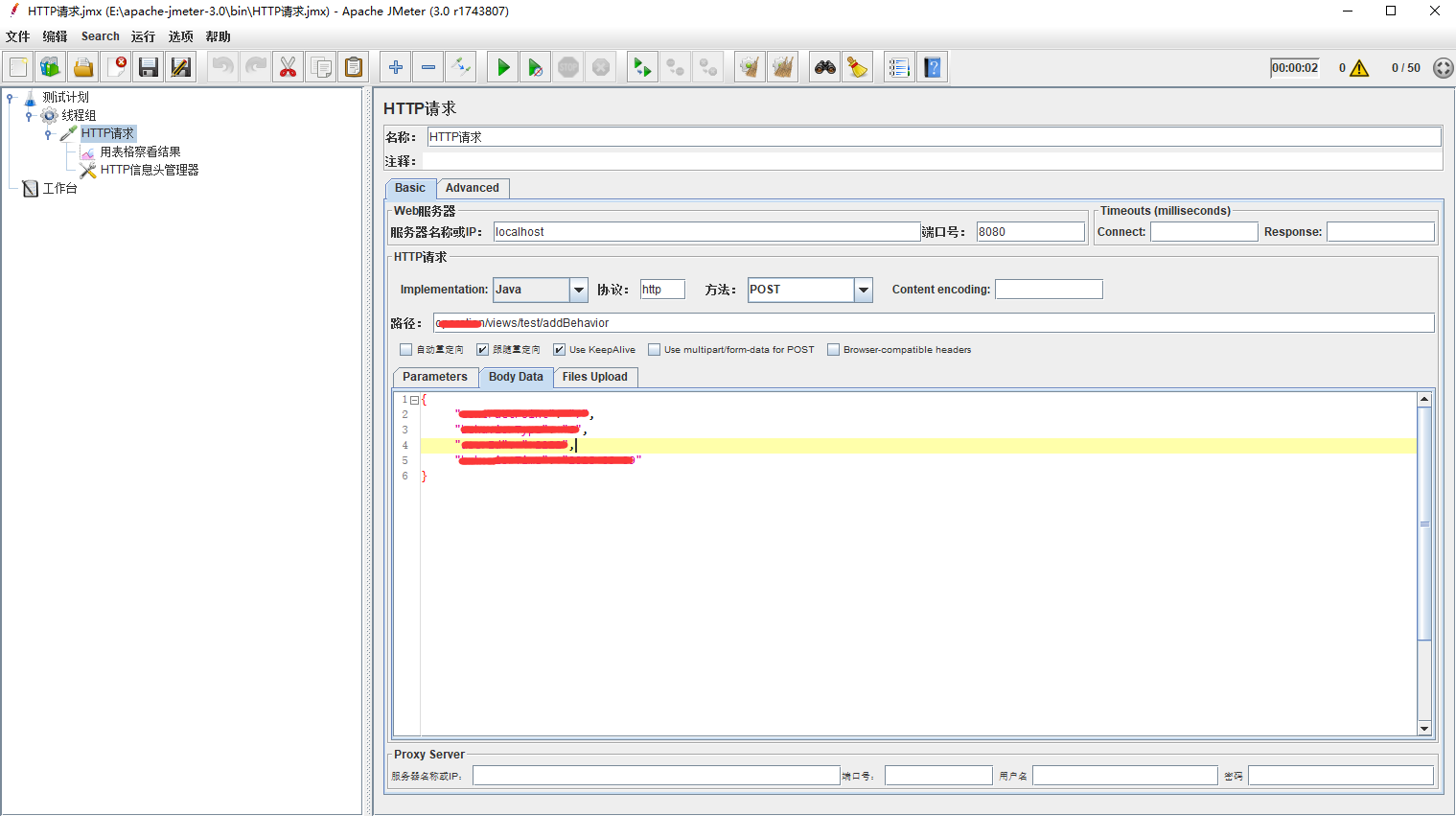
这里设置请求的路径,参数等等。
设置请求头信息,因人而异
我的设置:Content-Type:application/json
表格查看结果
查看结果:
这个可以根据机器的性能进行测试,以我的接口为例,当设置并发数为100以内时,基本上不会有降级处理,当并发数大于100时,就会有部分请求进入降级接口了。
6、接口监控
实际项目中,经常需要对我们的接口和项目情况进行监控,Hystrix已经为我们考虑到了。Hystrix提供了近乎实时的监控,Hystrix会实时的,累加的记录所有关于HystrixCommand的执行信息,包括执行了每秒执行了多少请求,多少成功,多少失败等等,更多指标请查看:https://github.com/Netflix/Hystrix/wiki/Metrics-and-Monitoring
在web.xml中添加下述配置:
<!-- for Hystrix --> <servlet> <display-name>HystrixMetricsStreamServlet</display-name> <servlet-name>HystrixMetricsStreamServlet</servlet-name> <servlet-class>com.netflix.hystrix.contrib.metrics.eventstream.HystrixMetricsStreamServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>HystrixMetricsStreamServlet</servlet-name> <url-pattern>/hystrix.stream</url-pattern> </servlet-mapping>
启动应用。访问http://hostname:port/项目名/hystrix.stream,可以看到下面信息

这种是最原生的监控使用方式,大家可以另外集成Hystrix 提供的一个 Dashboard 应用。Dashboard 是一个单独的应用,我们可以独立部署。如果需要监控整个 Hystrix 集群,就需要使用 Turbine 应用。Turbine 也是 Netflix 开源的一个服务。但是使用 Hystrix Stream 和 Turbine 存在一个明显的不足,那就是无法查看历史的监控数据。解决这个问题就需要我们自己来实现了。
监控的相关不是本文的重点,就不多介绍了,大家可以百度下hystrix在微服务项目中监控的实现,这里网上文章很多,基本上和传统项目没有任何区别了,大家可以参考实现。