一、BIO
Blocking IO(即阻塞IO);
1. 特点:
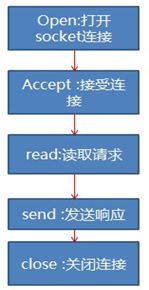
a) Socket服务端在监听过程中每次accept到一个客户端的Socket连接,就要处理这个请求,而此时其他连接过来的客户端只能阻塞等待;
b) 多线程处理多个连接,每个线程拥有自己的栈空间并且占用一些 CPU 时间。每个线程遇到外部未准备好的时候,都会阻塞掉。阻塞的结果就是会带来大量的线程上下文切换。且大部分线程上下文切换可能是无意义的。比如假设一个线程监听一个端口,一天只会有几次请求进来,但是该 cpu 不得不为该线程不断做上下文切换尝试,大部分的切换以阻塞告终。
2. 流程:
二、 NIO
Java New IO(即非阻塞IO )
1. 特点:
a) 由一个专门的线程来处理所有的 IO 事件,并负责分发。
b) 事件驱动机制:事件到的时候触发,而不是同步的去监视事件。
c) 线程通讯:线程之间通过 wait,notify 等方式通讯。保证每次上下文切换都是有意义的。减少无谓的进程切换。
2. 示例:
服务器端:
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.socket().bind(new InetSocketAddress(9999));
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
//do something with socketChannel...
}
客户端:
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("http://jenkov.com", 80));
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = socketChannel.read(buf);
String newData = "New String to write to file";
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put(newData.getBytes());
buf.flip();
while(buf.hasRemaining()) {
channel.write(buf);
}
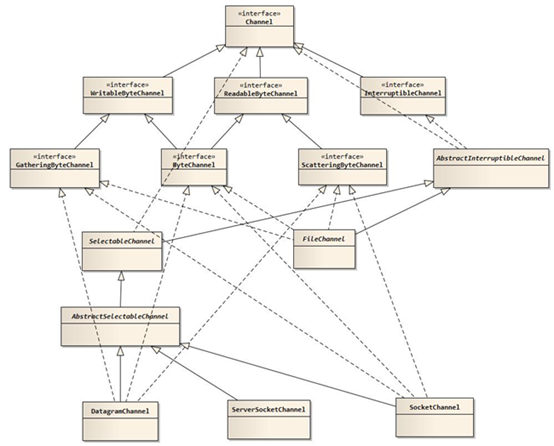
3. Channels(通道):
重要实现类:
1) FileChannel:从文件中读写数据。
2) DatagramChannel:能通过UDP读写网络中的数据。
3) SocketChannel:能通过TCP读写网络中的数据。
4) ServerSocketChannel:可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel。
重要方法:
Read(buf):从通道中读出数据到buf中;
Write(buf):将buf中的数据写入到通道中;
其中FileChanel提供了Map方法,返回一个MappedByteBuffer对象,代表内存映射文件IO,它可以比常规的基于流或者基于通道的I/O快的多。内存映射文件I/O是通过使文件中的数据出现为 内存数组的内容来完成的。
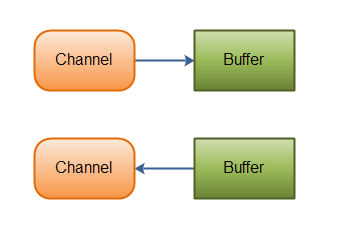
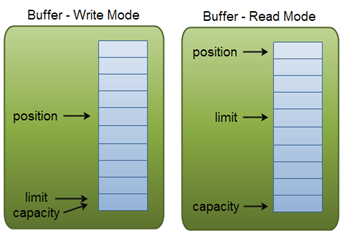
4. Buffers(缓冲区):
本质上是一块可以写入数据,然后可以从中读取数据的内存。用于和NIO通道进行交互(数据是从通道读入缓冲区,从缓冲区写入到通道中的);
继承关系:

重要属性:
|
序号 |
名称 |
属性功能 |
说明 |
|
1 |
capacity |
缓冲区大小 |
缓冲内存区域总的字节大小; |
|
2 |
limit |
实际数据大小 |
读模式时, limit表示你最多能读到多少数据;写模式下,表示你最多能往Buffer里写多少数据;写模式下,limit等于Buffer的capacity。 |
|
3 |
position |
当前位置 |
表示当前的位置。初始的position值为0,position最大可为capacity–1; |
重要方法:
|
序号 |
方法名 |
方法功能 |
说明 |
|
1 |
Flip |
切换到读模式 |
用于从写模式切换到读模式时调用的一个方法,表示最多能读取到多少内容; 具体实现为: 将position设回0,并将limit设置成之前position的值; |
|
2 |
rewind |
重读Buffer中的所有数据; |
将position设回0,limit保持不变,仍然表示能从Buffer中读取多少数据; |
|
3 |
Clear compact |
清空缓冲区 |
limit用于将整个缓冲区全部清空,而compact用于在缓冲区还有部分未读完的数据时,将未读完的数据拷贝到缓冲区最前面,将其余部分全部清空; limit和compact在清除缓冲区时都是修改的指针,使得往缓冲区里面写入数据时能覆盖,并不会真正清空缓冲区里面的内容; |
|
4 |
Mark reset |
标记 恢复标记 |
mark()方法标记Buffer中的一个特定position。通过调用reset()方法恢复这个position; |
|
5 |
Equals compareTo |
判断是否相等 比较大小 |
equals相等的条件: 1.有相同的类型(byte、char、int等)。 2.Buffer中剩余的byte、char等的个数相等。 3.Buffer中所有剩余的byte、char等都相同。 compareTo:判断Buffer A小于Buffer B的条件: 1.第一个不相等的元素小于另一个Buffer中对应的元素 。 2.所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)。 备注:剩余元素是从 position到limit之间的元素 |
|
6 |
slice |
缓冲区分片 |
根据现有的缓冲区对象来创建一个子缓冲区,即在现有缓冲区上切出一片来作为一个新的缓冲区,但现有的缓冲区与创建的子缓冲区在底层数组层面上是数据共享的,也就是说,子缓冲区相当于是现有缓冲区的一个视图窗口 |
|
7 |
asReadOnlyBuffer |
创建只读缓冲区 |
这个方法返回一个与原缓冲区完全相同的缓冲区,并与原缓冲区共享数据,只不过它是只读的。如果原缓冲区的内容发生了变化,只读缓冲区的内容也随之发生变化; |
|
8 |
allocateDirect |
直接缓冲区 |
给定一个直接字节缓冲区,Java虚拟机将尽最大努 力直接对它执行本机I/O操作。也就是说,它会在每一次调用底层操作系统的本机I/O操作之前(或之后),尝试避免将缓冲区的内容拷贝到一个中间缓冲区中 或者从一个中间缓冲区中拷贝数据。 |
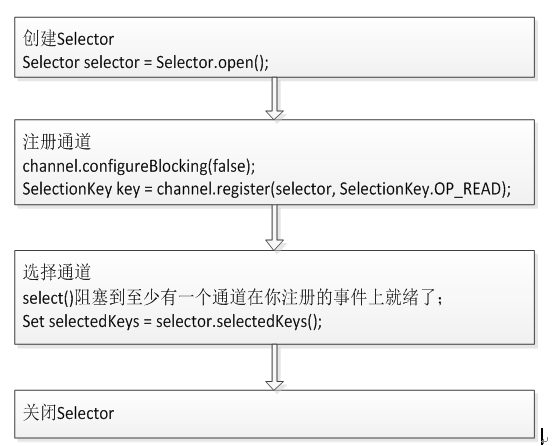
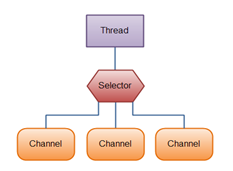
5. Selectors(选择器):
选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。
要使用Selector,得向Selector注册Channel,然后调用它的select()方法,接下来就等待事件就绪并处理事件;
使用事项:
1) 与Selector一起使用时,Channel必须处于非阻塞模式下。这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式。而套接字通道都可以。
2) 选择器监听的事件集合有:SelectionKey.OP_CONNECT, SelectionKey.OP_ACCEPT, SelectionKey.OP_READ, SelectionKey.OP_WRITE;
3) 从SelectionKey中分离出事件的方法:
int interestSet = selectionKey.interestOps();
boolean isInterestedInAccept=(interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT;
boolean isInterestedInConnect = (interestSet & SelectionKey.OP_CONNECT) == SelectionKey.OP_CONNECT;
boolean isInterestedInRead = (interestSet & SelectionKey.OP_READ) == SelectionKey.OP_READ;
boolean isInterestedInWrite = (interestSet & SelectionKey.OP_WRITE) == SelectionKey.OP_WRITE;
同样SelectionKey中也封装了上面的方法:
selectionKey.isAcceptable();
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();
使用流程: