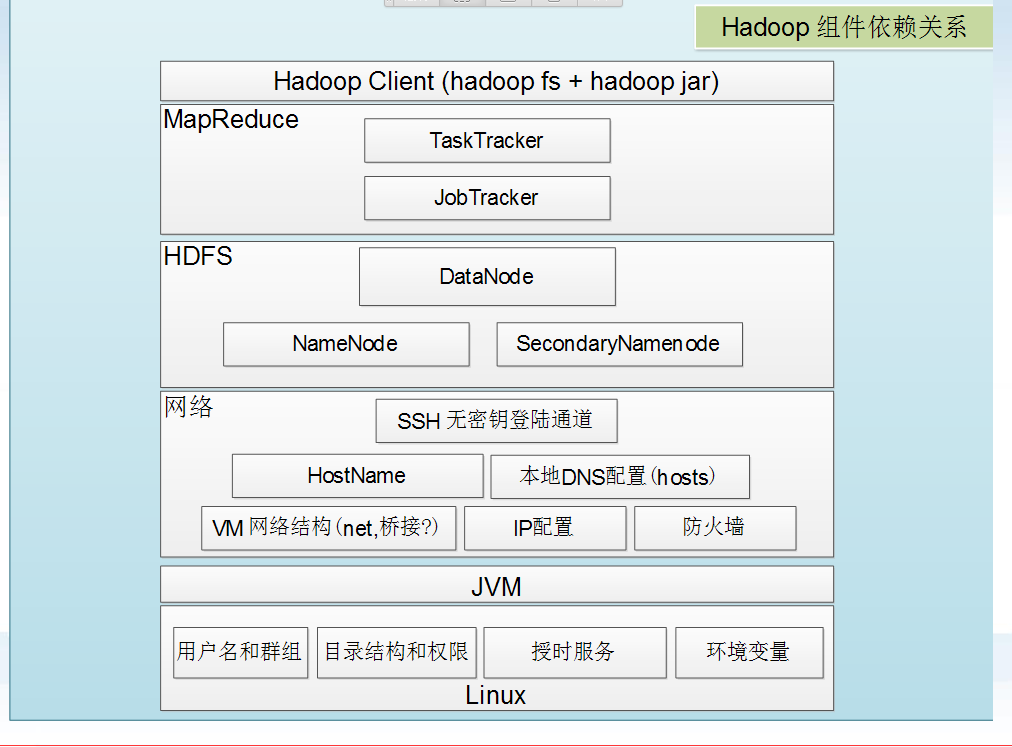
一、hadoop组件依赖关系
二、hadoop日志格式:
两种日志,分别以out和log结尾:
1 以log结尾的日志:通过log4j日志记录格式进行记录的日志,采用日常滚动文件后缀策略来命名日志文件,内容比较全。
2 以out结尾的日志:记录标准输出和标注错误的日志,内容比较少。默认的情况,系统保留最新的5个日志文件。
可以在/etc/hadoop/hadoop-env.sh中进行配置:
33 #Where log files are stored. $HADOOP_HOME/logs by default. 34 #export HADOOP_LOG_DIR = ${HADOOP_HOME}/logs
日志名称的解释:

二、hadoop启动和停止:
第一种方式:
启动:
start-dfs.sh
start-mapred.sh(hadoop 2.x为 start-yarn.sh)
停止:
stop-dfs.sh
stop-mapred.sh(Hadoop 2.x为 stop-yarn.sh)
全部启动:
start-all.sh
启动顺序:NameNode --> DataNode --> Secondary NameNode --> JobTracker --> TaskTracker
全部停止:
stop-all.sh
停止顺序:JobTracker --> TaskTracker --> NameNode --> DataNode --> Secondary NameNode
第二种方式(守护进程逐一启动和关闭):
启动:
1 hadoop-daemon.sh start namenode 2 hadoop-daemon.sh start datanoe 3 hadoop-daemon.sh start secondarynamenode 4 hadoop-daemon.sh start jobtracker 5 hadoop-daemon.sh start tasktracker
启动顺序和上面的启动顺序一样:NameNode --> DataNode --> Secondary NameNode --> JobTracker --> TaskTracker
停止:
1 1 hadoop-daemon.sh stop jobtracker 2 2 hadoop-daemon.sh stop tasktracker 3 3 hadoop-daemon.sh stop namenode 4 4 hadoop-daemon.sh stop datanoe 5 5 hadoop-daemon.sh stop secondarynamenode
停止顺序和上面的启动顺序一样:JobTracker --> TaskTracker --> NameNode --> DataNode --> Secondary NameNode
第三种方式:
启动:
start-all.sh
停止:
stop-all.sh
三、测试
1 HDFS测试
对HDFS文件系统进行查看文件,对文件的基本操作。
hadoop fs -put hdfs://master01:9000 /xxx //上传文件 hadoop fs -get hdfs://master01:9000 /xxx //下载文件
hadoop fs -cat hdfs://master01:9000 /xxx //查看文件
2 MapReduce程序测试
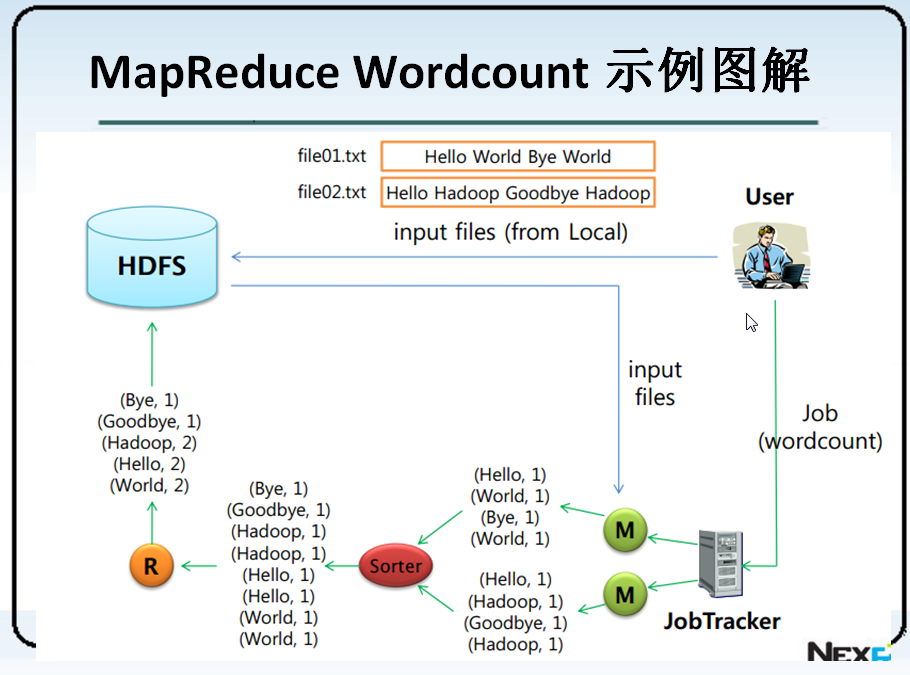
测试一个wordcount程序,思路是首先往文件系统中去上传一些文本文件,然后通过wordcount函数执行。
hadoop fs -mkdir /laowang/ //在HDFS中创建一个文件夹 hadoop fs -mkdir /laowang/input //在该文件夹下再创建一个文件夹 hadoop fs -put /software/hadoop2.7.3/conf/*.xml /laowang/input/ //将我们指定的文件上传到刚刚创建的文件夹中 hadoop jar hadoop-examples-x.x.x.jar wordcount /laowang/input/ /laowang/output/ //使用wordcount函数运行。前者是输入路径,后者是输出路径
3 查看MapReduce的运行状态
可以通过端口号50030查看MapReduce的执行状态,端口号50070查看HDFS的文件结构。
4 MapReduce Wordcount 示例图解
四、hadoop配置文件
三大基础配置文件:
1 core-site.xml
配置hadoop common project 的相关属性,hadoop框架的基础属性配置。
2 hdfs-site.xml
配置HDFS project 的相关属性。
3 mapred-site.xml
配置与MapReduce框架相关的属性。
额外配置文件:
1 master:
主节点,并不是配置hadoop 主节点的信息,而是配置HDFS辅助节点的信息。
2 slaves:
从节点,配置hadoop 中HDFS和MapReduce框架的从节点信息。
五、配置文件与五大守护进程的相互联系(重要)
