MySQL数据库的备份和还原
备份:
mysqldump -u root -p dbcurr > 20190219.sql
mysqldump:备份命令
root:用户名
dbcurr:备份的数据库名称
>:备份符号
20190219.sql:备份的文件名
使用mysqldump备份多个数据库,需要使用-databases参数,多个数据库名称之间用空格隔开,使用mysqldump备份school库和test库:
mysqldump -u root -h 127.0.0.1 -p -databases school test > xx.sql
使用-all-databases参数备份系统中所有数据库,不需要指定数据库名称:
mysqldump -u root -h 127.0.0.1 -p -all-databases > xx.sql
备份数据库中的表用:
mysqldump -u root -h 127.0.0.1 -p school book(表) > xx.sql
还原:
mysql -u root -p dbcurr < 20190219.sql
mysql:还原命令
root:用户名
dbcurr:备份的数据库名称
<:还原符号
20190219.sql:还原的文件名
索引是提高select 操作性能的最佳方法,只是针对select起作用,对insert,update等无效,所有列类型都可以被索引,索引不能过多,会耗费性能,数据更新重构索引是非常耗时的,每个表至少支持16个索引,通俗的说索引是用来提高查询效率,不需要通过扫描全部表记录,而直接使用索引快速定位需要查询的值
设计索引的原则:
1、索引列
最适合索引的列是出现在where子句中的列,或连接子句中指定的列,而不是出现在select关键字后的选择列表的
2、唯一索引
对于唯一值的列,索引的效果最好,具有多个重复值的列,索引的效果最差,一般都对主键创建索引
3、使用短索引
节省大量索引空间,查询更快,减少IO
4、不要过度索引
过度使用索引会占用磁盘空间,当更新操作大于查询操作,索引要越少越好,索引要慎重
创建主键索引:索引列不能包含重复值,且不允许有空值,不能用create,alter的方式创建primary key索引
alter table table_name add primary key (column_list)
创建普通索引:这是最基本的索引,没有任何限制
create index index_name on table_name (column_list)
alter table table_name add index index_name(column_list)
例子:
给订单表orders中的订单状态和用户id加上组合索引:Create index status_user on orders(status,user_id);
创建唯一索引:它与普通索引类似,不同的是索引列的值必须唯一,但允许有空值
create unique index index_name on table _name (column list)
alter table table_name add unique (column list)
删除索引:drop index index_name on table_name
查看索引:show index from table_name
索引失效:
1、当sql语句中含有<>,not in,not exist,!=,like时,即使有索引也不会起作用
2、对索引列进行运算导致索引失效,索引列运算包括(+,-,*,/,!等)
错误的例子:select * from test where id-1=9
正确的例子:select * from test where id=10
3、不要将空的变量值直接与比较运算符(符号)比较
如果变量可能是空,应使用is null或 is not null进行比较
4、不要在SQL代码中使用双引号
字符常量使用单引号
视图是一种虚拟存在的表,对于使用视图的用户来说基本上是透明的,在数据库中并不占用存储空间
视图的作用:
1.使操作简单化
2.增加数据的安全性
3.提高表的逻辑独立性
创建视图的三种方式:
1、create view v as select * from table_name
2、create view v as select id,name,age from table_name
3、create view v as [vid,vname,vage]select id,name,age from table_name
查看视图:show create view view_name
修改视图:alter view v as select * from table_name
删除视图:drop view if exists 视图名列表
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,然后直接调用这些存储过程来执行已经定义好的SQL语句
MySQL中,创建存储过程的基本形式如下:
delimiter $$;
CREATE PROCEDURE 名称(参数列表)
BEGIN
SQL语句块
End
$$;
delimiter;
注意:
由括号包围的参数列必须总是存在,如果没有参数,也该使用一个空参数列(),每个参数默认都是一个in参数,要指定为其它参数,可在参数名之前使用关键词out或inout
变量定义:
declare 变量名 数据类型 default 默认值
参数类型:
in参数
表示该参数的值必须在调用存储过程之前指定,在存储过程中修改的值不能被返回,也就是调用的时候就得指定,默认传入的就是in参数
out参数
该值可在存储过程内部改变,并可以返回.往往是用于获取存储过程里的参数值
inout参数
该值可以在调用时指定,并可修改和返回
传参:
create procedure test_p(in 参数名 参数类型,out 参数名 参数类型)
调用:
call 存储过程名
drop procedure if exists insert_event;
delimiter $$;
create procedure insert_event()
begin
declare i int;
set i=1;
while i<3001 do
insert into student(s_id, s_name) values(i, '马刺');
set i=i+1;
end while;
end;
$$;
delimiter;
# 先执行上面的语句,再执行call那行,用存储过程向表插入3000条数据
call insert_event();
触发器是一个特殊的存储过程,不同的是存储过程要用CALL来调用,而触发器不需要使用CALL,也不需要手工启动,只要当一个预定义的事件发生的时候,就会被mysql自动调用
如何选择合适的存储引擎:
---MyISAM
如果应用不需要事务,处理的只是基本的CRUD操作,Create -> insert,Read -> select,Update -> update,Delete -> delete
---InnoDB
对事务完整性有比较高的要求,在并发条件下要求数据的一致性,有大量的增删改查操作,支持外键,对于类似计费或者财务系统等,对数据准确性要求比较高的系统使用InnoDB比较合适
比如说在人员管理系统中,删除一个人员,需要删除人员的基本资料,也要删除和该人员相关的信息,如邮箱,文章等,这些数据库操作语句就构成一个事务
锁概述
MySQL锁分为三种:
表级锁:开销小,锁定颗粒大,发生冲突的概率高,不会出现死锁(myisam 、memory)
行级锁:开销大,锁定颗粒小,发生冲突的概率低,会出现死锁(innodb)
页面锁:不需要关注
在mysql客户端输入:show status like 'table%';
通过检查table_locks_waited和 table_locks_immediate状态变量来分析系统上的表锁争夺,如果table_locks_waited的值比较高,说明存在比较严重的表锁争用情况
---获取InnoDB行锁争用情况
---show status like 'innodb_row_lock%'
---原因可能是Query语句所利用的索引不够合理
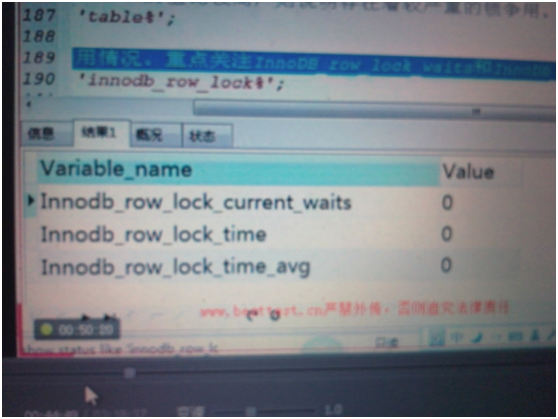
关注第一个和第三个,值越小越好
锁表命令:lock table table_name write,在第一个窗口锁表,在第二个窗口执行write操作,会卡住,证明锁住表了,unlock tables释放锁
set @@autocommit=0; # 关闭自动提交命令
set table_type =InnoDB; # 换数据库引擎命令
show variables like '%storage_engine%'; # 查看数据库存储引擎命令
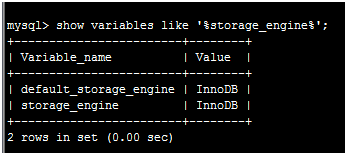
show variables like 'wait_timeout';
分析优化SQL的思路:
只要是数据库,要考虑从哪几方面入手
---选数据库,是Oracle,MySQL还是sqlserver,什么版本
---安装和部署,在Windows还是Linux平台上,安装在32位还是64位的机器上
---数据库本身,参数
---SQL语句
---表的设计和数据分布
---思想:抓取 (范围)>> 定位(缩小范围)>>分析并给出建议
抓取(范围):哪些sql语句需要优化
定位(缩小范围):筛选出比较严重的sql语句
---shell脚本
---慢查询
---explain
配置文件
Windows下的是my.ini
Linux下的是my.cnf
开启慢查询
慢查询主要针对抓取(范围)的,使用什么技术进行查询,抓取到那些比较耗时的sql语句
vi /etc/my.cnf,配置【mysqld】,在【mysqld】块中增加如下内容
---log_slow_queries=/var/log/mysql/slowquery.log(提前建立好这些目录与文件啊!)
---long_query_time=2(记录超过的时间,默认为10s)
如果已存在这两条语句,去掉log_slow_queries=/var/log/mysql/slowquery.log和long_query_time=2之前的#,阀值2秒可以自己设定,把超过2秒的语句提取出来
---配置完成以后重启MySQL服务器
重启MySQL命令/etc/init.d/mysqld restart(使用mysqld脚本启动)或service mysqld restart(使用service启动)
在MySQL客户端下执行
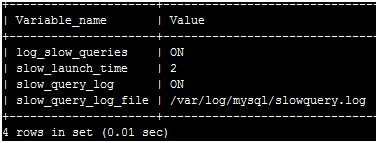
mysql>show variables like '%slow%';
查看慢查询日志是否开启,log_slow_queries和slow_query_log都为on,证明开启,如果没有开启,在mysql命令行输入
mysql>set global slow_query_log='ON';
常用的分析慢查询语句:
访问次数最多的20条sql语句:mysqldumpslow -s c -t 20 /var/log/mysql/slowquery.log
返回记录集最多的20条sql语句:mysqldumpslow -s r -t 20 /var/log/mysql/slowquery.log
按照时间返回前10条里面含有左连接的sql语句:mysqldumpslow -t 10 -s t -g "left join" /var/log/mysql/slowquery.log
-s是表示按照何种方式排序,c,t,l,r分别是按照记录次数、时间、查询时间、返回的记录数进行排序,ac,at,al,ar表示相应的倒序,-g后面可以写一个正则匹配模式,-t是top n的意思,即为返回前多少条的数据

395表示这条sql语句被执行了395次,平均的执行时间是0秒,总共的时间是0秒
select _mis_uid,_mis_reqip,_mis_time from t_mis_user_ip where _mis_time between N and N,通过between N and N,可以看到时间被抽象成了Number,那么接下来构造一个真正的sql语句或者问下开发,之后就可以用explain来优化
select _mis_uid,_mis_reqip,_mis_time from t_mis_user_ip where _mis_time between 1272247251and 1272247258
explain出来的语句有好多参数
id,select_type,table,type,possible_keys,key,key_len,ref,rows,extra
type表示MySQL在表中找到所需行的方式,又称"访问类型",常见的类型如下
由左至右,最差到最好,大参数关注type,小参数关注下面的
All,index,range,ref,eq_ref,(const,system),NULL
key显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL,需不需要添加索引,添加索引后能不能提高效率
rows表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,rows值越小越好
extra
---如果是Only index,这意味着信息只用索引树中的信息检索出来的,这比扫描整个表要快,这是最理想的状态
---如果是where used ,就是使用上了where限制
---如果是impossible where ,表示用不着where,一般就是没查出来啥
---如果此信息显示Using filesort 或者 Using temporary的话就会很吃力,where和order by的索引经常无法兼顾,如果按照where确定索引,那么在order by时必然会引起Using filesort,这就要看是先过滤再排序划算,还是先排序再过滤划算
根据案例二explain分析:一般是由参数或代码导致的问题
---sql语句生成了一个巨大的临时表,内存放不下,于是全部拷贝到磁盘,导致IO飙升
---extra列看到Using Temporary就意味着使用了临时表
---找开发或dba进行拆分sql
explain局限性:
---explain只能解释select操作
---explain不考虑各种cache
当服务器的负载增加时,使用show processlist来查询慢的/有问题的查询,使用慢查询日志,找出执行慢的查询,使用explain来决定查询功能是否合适
mysql优化目标是减少IO次数和降低CPU计算,filesort含义:mysql需要进行实际的排序操作而不能通过索引获得已排序数据
reset master:所有二进制日志将被删除,mysql会重新创建二进制日志
purge master logs:只删除部分二进制日志文件
purge master logs to 'log_name':第一种方法指定文件名,执行该命令将删除文件名编号比指定文件名编号小的所有日志文件
purge master logs before 'date':第二种方法指定日期,执行该命令将删除指定日期以前的所有日志文件
查看健康状态:
---一个shell脚本showmysql.sh
首先创建shell目录,放在根目录下,把showmysql.sh用rz命令上传到shell目录下
---配置my.cnf,增加如下面所示的内容

首先进入/etc目录,然后vi my.cnf,在最下面增加这些内容:[client],user=root,password=123123这三行
---安装bc,执行yum install bc
在任一路径下执行yum install bc,中途有提示,输入y
---chmod
在shell目录下,chmod 777 showmysql.sh
--- sh
在【root@小强shell】下执行sh showmysql.sh这个命令,就看到想要的结果
数据库架构优化方案:
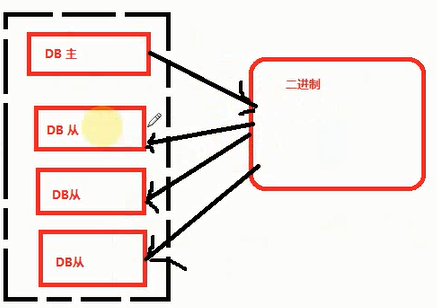
主从复制的原理
思想:读写分离,数据集中写(追加写)在主服务器上,从服务器上零散读(追加读),主库追加写,从库追加读,缓解数据库压力,主要是查询压力,因为查询一般大于写
原理总结:
a、master(主服务器)将更新的数据写入数据库中,再将更新的语句放入binary log中
b、slave(从服务器)首先要开启I/O thread和SQL thread线程
c、然后通过I/O thread将主服务器binary log中的内容复制出来,放入relay log(中继日志)中
d、再通过SQL thread从relay log中读取出二进制日志,然后更新自己的数据库
注意事项:主从复制数据更新是线性的过程,只能从主服务器向从服务器更新,不能反过来更新,主从解决不了数据量大的问题,大数据从磁盘到内存,内存很可能放不下导致宕机
逻辑IO是操作系统发起的IO,这个数据可能会放在磁盘上,也可能会放在内存或cache里
物理IO是设备驱动发起的IO,这个数据最终会落在磁盘上
典型的数据库三大问题
---过量的数据库调用
---连接池(忘了关闭、满了)
---sql问题(索引、锁等)
业务层面导致
select选择句柄的时候是遍历所有句柄,句柄有事件响应时,select遍历所有句柄才能获取到哪些句柄有事件通知,因此效率非常低,epoll不用遍历所有句柄,就是句柄上有事件响应马上选择出来,效率非常高
监控mysql
---安装第三方工具(sp on mysql)
---破解
双击sp on mysql压缩包,解压到指定文件夹,文件夹取名为sp on mysql,一路next,还要破解,要不然用不了,上面输入:295710059649205163750 ,下面输入:Bergelmir/CORE
数据库性能测试如何去做?
一是选择几条重要的SQL语句测试性能,loadrunner里加压
二是通过数据库接口去压,考虑缓存还是不考虑缓存,有缓存数据会存到缓存里,没有缓存会对数据库产生压力