数据流容错机制
该文档翻译自Data Streaming Fault Tolerance,文档描述flink在流式数据流图上的容错机制。
-------------------------------------------------------------------------------------------------
一、介绍
flink提供了可以一致地恢复数据流应用的状态的容错机制,该机制保证即使在错误发生后,反射回数据流记录的程序的状态操作最终仅执行一次。值得注意的是,该保证可以降低为“至少执行一次”,具体描述见下。
容错机制持续地从分布式数据流图中取得快照。对于拥有少量状态的流式应用,这些快照是非常轻量级的,故它们可以在频繁获取时仍然不过多影响运行效率。流式应用的状态将被存储在一个配置位置中(如一个master节点、HDFS中等)。
在程序失效时(不论源自硬件、网络、软件等),flink将会停止分布式数据流图,而后系统将会重启Operator并重置它们到最近成功的检查点。输入流将会被充值到状态快照的时间点。flink保证重启的并行数据流图中的所有已处理的记录都不会出现在检查点状态之前的部分中。
Note:要使得机制支持其所有的保证,数据流source需要能够将流倒回到指定的之前的点。Apache Kafka有这个方法,flink与Kafka的connector可以利用该方法完成倒回的功能
Note:由于Flink的检查点由分布快照实现,以下的“检查点”和“快照”是同意义的。
二、检查点
Flink容错机制的核心是获取数据流和Operator状态的一致分布式快照。这些快照作为系统可以撤回的一致检查点。Flink的机制所获取的快照在"
Lightweight Asynchronous Snapshots for Distributed Dataflows"中有所描述。它发展自分布式快照的标准Chandy-Lamport算法,并且经过定制适配了Flink的执行模型。
2.1 Barriers
Flink的分布式快照的核心元素是stream barriers。这些barriers被注入到数据流中,作为数据流的一部分和其他数据一同流动(正如InfoSphere的punctuation),barriers不会超过其他数据到达(乱序到达)。一个Barrier将数据流中的数据分割成两个数据集,即进入当前快照的数据和进入下一次快照的数据。每个Barrier带有一个ID,该ID为将处于该Barrier之前的数据归入快照的检查点的ID。Barrier不会打断数据流的流动,所以它是十分轻量级的。来自不同的快照的多个Barrier可以同一时间存在于同一个流中,也就是说,不同的快照可以并行同时发生。
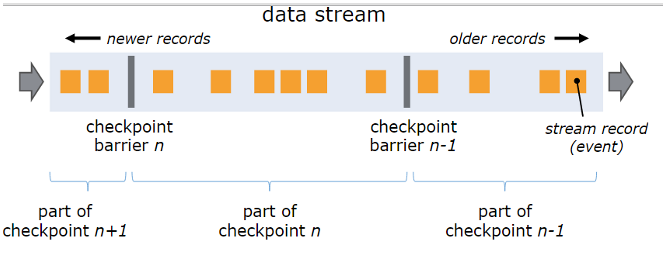
图1 Barriers
数据流中的Barrier是在数据流的source处被插入到并行数据流图的。快照n的barrier被插入的点(成为Sn),就是在源数据流中快照n能覆盖到的数据的最近位置,如在Apache Kafaka中,这个位置就是上一个数据(record)在分区(partition)中的偏移量(offset)。这个位置Sn将会交给checkpoint coordinator(Flink的JobManager中)。
这些Barrier随数据流流动向下游,当一个中间Operator在其输入流接收到快照n的barrier时,它在其所有的输出流中都发送一个快照n的Barrier。当一个sink operator(流DAG的终点)从其输入流接收到n的Barrier,它将快照n通知给checkpoint coordinator。在所有Sink都通知了一个快照后,这个快照就完成了。
当快照n完成后,由于数据源中先于Sn的的数据已经通过了整个data flow topology,我们就可以确定不再需要这些数据了。

图2 对齐操作
接受多于1个输入流的Operator在处理快照的Barrier时,需要对多输入流进行对齐(align)操作,具体过程如上图所示:
1. Operator一旦从输入流中收到快照n的barrier,它在其他所有的输入流中都收到快照n的barrier之前,都不能继续处理新的数据。否则,它将把属于快照n和快照n+1的数据混起来。
2. 收到Barrier n的数据流将被暂时搁置起来,从这些数据流中收到的数据将不会被进一步处理,而是放进一个输入缓存中(input buffer)
3. 当最后的数据流收到Barrier n,Operator将所有等待的输出数据发送出去,然后发送Barrier n。
4。 在这之后,Operator将恢复处理输入流的数据,先处理input buffer中的数据,再处理新接收的数据。
2.2 状态(State)
当Operator包含任何形式的状态,该状态一定也是快照的一部分。Operator的状态有着不同的形式:
1. 用户定义状态(User-defined state):该状态直接由transformation方法(如map(), filter())来创建和修改。用户定义状态可以简单地是一个Java对象函数的变量,或函数的相关的key-value状态(具体见于流应用的状态)
2. 系统状态(System state):该状态指在Operator计算中的数据缓存。窗口缓存就是一个典型例子,系统内部收集、聚集(aggregate)窗口数据直到窗口数据逐出(如窗口滑动、evaluated and evicted)。
当Operator在它所有的输入流都收到Barrier时,在将Barrier发送到输出流之前,它将会对其状态进行快照。此时,所有在Barrier之前的数据对状态的更新操作都将完成,而在Barrier之后的数据对状态的更新操作都不会执行。由于快照的状态可能会很大,它将会在后台被保存的一个可配置状态中。默认地,它使用JobManager拥有的内存,但对于严谨的配置来说,应当配置一个可靠的分布式存储(如HDFS)。在保存状态之后,Operator通知checkpoint,并发送快照Barrier到期输出流中,并继续其他处理。
目前的快照包括2个部分:
1. 对每个并行数据流的数据源,快照开始时,数据流的偏移量(offset)或位置(position)。
2. 每个Operator存储的该快照的状态的指针。
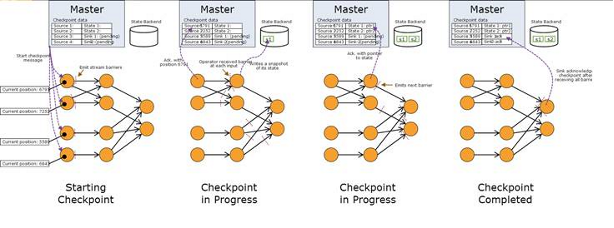
图3 检查点存储状态
2.3 只执行一次 VS. 至少执行一次
对齐操作可能会给流应用增加延迟(latency),通常这些额外时延都仅是毫秒级的,但也有在一些异常情况下延迟明显增长的情况。一些应用对所有数据都严格要求极低延迟(几毫秒),在这些应用中,Flink提供一个可以跳过检查点中对齐操作的开关接口。检查点快照依然将在Operator在所有输入流接收到检查点Barrier时生成。
当选择跳过对齐操作时,即使Operator在一些输入流中接收到检查点n的Barrier,它仍将继续处理所有输入数据。在这种情况下,Operator在检查点n快照生成之前,也会处理属于快照n+1的数据。在恢复时,这些数据将会重复出现,因为它们既属于检查点n的状态快照,也会在检查点n之后的数据重放(replay)中出现。
NOTE: 对齐操作仅用于拥有多前驱的Operator(Join)或多发送方的Operator(如一个重分区(repartitioning)/洗牌(shuffle)后的流)。由于这一点,对于仅带有“
embarrassingly parallel streaming operations”的数据流图,即使在至少执行一次(at least once)的模式下也会给出只执行一次(exact once)的保证。【这段我没有看懂。。】
2.4 恢复
Flink恢复时的机制是十分直接的:在系统失效时,Flink选择最近的已完成的检查点k,系统接下来重部署整个数据流图,然后给每个Operator在检查点k时的相应状态。数据源则被设置为从数据流的Sk位置开始读取。例如,在Apache Kaffa执行恢复时,系统会通知消费者从偏移Sk开始获取数据。
如果状态是以递增的形式快照的,则Operator会从最近的完整快照开始,然后应用一系列的递增快照来更新该种状态。