python day2
2019/10/5
1. 编码转换
编程是外国佬发明的,所以一开始的编码表只有英文与标点符号,没有中文的事。
ASCII编码表:一个字符占用两个字节。
后来中国人发明了GBK编码表,可以显示中文。
再后来又有了Unicode万国码. Unicode可以包容全世界人民的语言。Unicode是统一用4个字节来表示一个字符。python2默认使用unicode码表。
又有了utf-8。utf-8是表示英文仍然是两个字节,中文占用3到6个字节。现在python3默认使用utf-8作为编码方式。
每个模块的开头的# -*- coding:utf-8 -*-就是指明编码方式是utf-8。
python2.x的编码方式之间的转换如下:
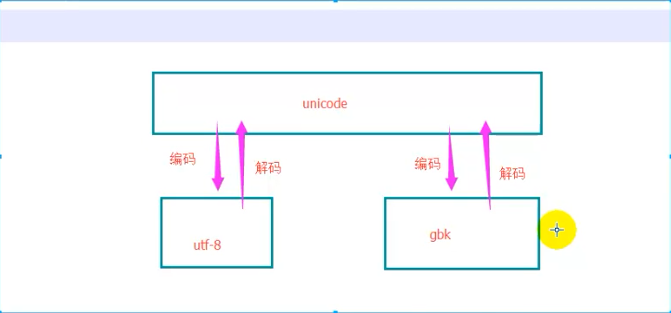
就是utf-8如果要转换成gbk,必须要通过unicode作为中转。
# -*- coding:utf-8 -*-
#下面是python2的情况
temp = '张三'
#decode()方法是解码,解码必须指定原来的编码方式,就是解码成unicode码。
temp_unicode = temp.decode('utf-8')
#编码也要指定需要编码的码表。
tem_gbk=temp_unicode.encode('gbk')
print(temp,temp_unicode,temp_gbk,sep=' ')
#下面是python3的情况
#python3中,自动转换utf-8,unicode,gbk
#python3中,移除了unicode类型
temp='李四'
temp_gbk=temp.encode('gbk')
2. python的基本数据类型
总共有八种基本数据类型:int(数字),float(浮点数),str(字符串),bool(布尔值),list(列表),tuple(元组),dict(字典),set(集合)。
每种数据类型都有自己独有的方法与属性。
python是强类型语言,不同类型之间不能相互运算。
可以通过type(x)函数判断某个变量x是哪种类型。
可以通过dir(x)函数来判断某个对象x有哪些方法。
可以通过help(type(x))函数来判断某个对象x的具体方法说明。
所有类型具备的方法都在它的类中。
2.1. 数值类型(int,float)
数值类型有加减乘除幂运算,也有比较操作等。
#打开buitlins模块,看到int类基本上都是魔法方法(左右两边都是双下划线叫魔法方法,比如__add__)。
int(x,base=10) #将数值型字符串x转化成整数,默认是10进制,也可以改成8,16。
a=2#将2赋值给变量2
a.__eq__(5) #就是判断2是否==5
a.__add__(5) #就是2+5
a.__sub__(1) # 2-1
a.__mul__(3) # 2*3
a.__div__(2) # 2/2,返回1.0
a.__divmod__(2) #2除以2,返回得是商和余组成的元组。
a.__floordiv__(2) # 就是2//2,取商是1。
a.__ge__(1) #就是a>=1,g是great,e是equal
a.__gt__(1) #就是a>1,g是great,t是than。
a.__le__(1) #就是a<=1,l是less,e是equal
a.__lt__(1) #就是a<1,l是less,t是than.
a.__mod__(2) #就是a%2,取余是0。
a.__pow__(3) # 2**3
a.__lshift__(2) # a<<2,a的二进制左移2位,相当于a*(2**2)
a.__rshift__(2) # a>>2,a的二进制右移2位,相当于a/(2**2)
2.2. str(字符串)
而str,就会有很多方法了。常用方法有:strip,index,切片,split,join,len.(记得学英语的时候,记不住太多单词,慢慢用着用着就会了。)
capitalize,center,count,decode,encode,endswith,startswith,expandtabs,find,index,format,join,isdigit,split,strip,title,lstrip,rstrip,partition,replace,swapcase,upper,lower.
s1 = 'love is Not {0} EaSy'
s1.capitalize() # 返回s1的一份复制,并且是首字母大写,其余小写
s1.center(20,'-') # 让字符串在指定长度内居中,不够的长度以第二个参数进行填充。第二个参数默认是空格。
s1.count('N',2,10) #从指定长度统计第一个参数即N出现的次数。后面两个参数2与10可以不写,默认是None,就会搜寻整个字符串。
s1.decode('utf-8) # 某UTF8解码
s1.encode('gbk') #以gbk码表进行编码。
s1.endswith('y',1,8) #判断指定索引长度即第2个到7个是否以y结束,为真则返回True,假则是False。
s1.find('e',3,6) # 从指定索引长度即第3个到第5个,去找到e,如果找到了,返回e的索引值,找不到则返回-1
s1.index('e') # 返回e的索引值,如果e不存在,则会报错。也可以指定索引长度。
s1.format('so') #字符串的格式化,将so代替占位符{0}。
‘*’.join([1,2,3]) #join是连接方法,参数一般是可迭代对象。使用*去连接列表中元素,并返回一个字符串‘123’
s1.isdigit() #判断s1是否是整数型字符串
s1.split(' ') #以传递的参数空格作为分隔符,返回一个列表,即['love','is','Not','{0}','EaSy']
s1.strip() #去掉字符串左右两边的空格。
s1.title() # 每一个单词的首字母都大写
s1.lstrip() #去掉左边的空格。
s1.rstrip() # 去掉右边的空格
s1.partition('is') # 按照给定字符串,分成三部分,并返回一个元组。
s1.replace('Not','so') # 将not替换为so
s1.swapcase() #大小写一一转换
s1.upper() #全部大写
s1.lower() #全部小写
s1.isalnum() #判断字符串是否是由字母或数字组成。
s1.isalpha() #判断字符串是否全部由字母组成。
3. for 迭代遍历
for迭代遍历的语法格式如下:
for item in iterable:
执行语句
一开始的时候不是太懂,是没有搞懂迭代与遍历的意思,可迭代对象是iterable,iterable或者为空,或者至少有1个以上的元素,for item in iterable就是把item当作iterable里面的每一个元素,这样iterable里面的每个元素都走一遍就叫迭代。
比如:for x in [1,2,3,4]意思就是x按照顺序依次等于1,2,3,4,后面的执行语句每次都执行一次。
4. 列表list
形如[1,'2',True,'张三']这样用中括号括起来的就是列表list。列表的元素可以是任意数据类型,也就是说列表里面还可以嵌套列表。
列表是有顺序的,就是有索引值,列表的第一个元素的索引值从0开始,第二个元素索引值是1,依此类推。
定义列表有两种方法,一种是直接用中括号写,比如list1 = [1,3,'4',],第二种就是使用内置函数list,比如list1=list(1,2,3)(一个变量后面跟着括号叫做函数调用,比如list()就是调用list函数)
列表的方法:索引,切片,append,clear,count,extend,index,insert,pop,remove,reverse,sort.
列表也是可迭代的。凡是可是用索引来查元素的,就是有序的。
list1=[1,2,'3',True,'x'] #定义一个列表包含5个元素,并将其赋值给变量list1.
# 列表的索引
list1[0] # 取列表的第1个元素1
list1[-1] # 索引值也可以是负数,表示倒着取,-1表示最后一个元素。
list1[2] #取列表的第3个元素,即'3'。
list1[-2] # 取列表的倒数第2个元素,即True.
#可以通过索引直接修改列表的元素
list[0] = 8 #将第1个由1改为8了
#列表的切片
#切片就是取列表的某一段。切片是按照索引值来进行的,并且是包括左边不包括右边,即左包右不包。
list1[0:2]#表示从索引值0开始,一直到索引值为2结束(不包括2),也就是取索引值0与1这两个元素,并返回这两个元素组成的新列表,即[1,2]。
list1[0:2:2]#切片有三个参数,第一个表示从哪开始,第二个表示到哪结束,第三个表示步长,步长即每隔多少个取一个。
#上面表示从0开始,到2结束,步长为2。即取奇数项索引,所以只取到了元素1。
list1[:]#第一个参数不写则默认是0,第二个参数不写,则默认是列表长度,第三个参数不写则默认是1,所以这里表示复制一份列表。
list1[-4::-2]#表示倒着取,步长为2,前面的索引值也得是负数。结果是[2]。
#往列表的最后项追加元素
list1.append(7)
#往列表里面插入指定索引位置元素
list1.insert(1,'李四')
#统计列表中某个元素的出现次数,可以指定索引长度。
list1.count(1,0,3)#表示在索引值从0到3终止这个切片段,1这个元素出现了多少次。如果不指定索引长度,则默认是整个列表。
#扩展,将另一个可迭代对象的元素添加到列表的末尾。
a=list(1,2,3)
list1.extend(a)#
#返回某个元素的索引值,也可以指定索引长度
list1.index(1,0,4),如果不写,则默认是整个列表第一次出现元素1的索引值。
#pop是从列表中抽取一个元素,返回且删除这个元素。参数是索引值。
list1.pop(-2)#删除倒数第2个元素
list1.pop()#不写索引值,则默认删除最后一个元素。
#remove是删除元素,参数是删除元素。
list1.remove('x')#删除元素x
#反转,就是倒着顺序显示列表
list1.reverse()#将元素按照反转的顺序进行排列
#排序,sort(self,key=None, reverse=False)。key是传递一个排序函数,而reverse是布尔值,默认为False,则按升序进行排列,如果为真,则按逆序进行排列。
#排序时,英文与数字默认按照ASCII码表进行排序,中文按UNICODE码。
list2=[-1,-2,3,7,-9]
list2.sort()
list1.sort(key=abs,reverse=True)
5. 元组tuple
形如(1,2,'3',True)的就是元组。元组是有序的可迭代的不可变对象。
元组与列表差不多,只是没有增删改切片方法,所以元组是不可变对象。
定义元组有两种方法,一种是直接定义:t1=(1,2,'3',True),
第二种就是使用tuple函数,t1=tuple(list(1,2,3)),tuple后面跟可迭代对象。
元组可以通过索引查看元素,但是没有切片。
6. 字典dict
字典是key:value形式的键值对的集合,无序的,可迭代的,可变对象。
定义字典有两种方法,一种是直接定义:d1={1:'x','some':2,3:True}
第二是通过dict函数定义:d2=dict(1=3,name='lanxing',z=True)
注意:key必须是不可变对象,value则可以是任意数据类型。
字典的方法:key索引,clear,copy,fromkeys,get,items,keys,pop,popitem,setdefault,update,values。
d1={1:'x','some':2,3:True}#定义一个dict
v1= d1[1] #通过key来访问value
v2= d1['some']
d1['some']='y' #通过key来修改value,如果key存在,则修改value,如果不存在,则创建新的key:value对。
d1[‘x'] = 'z' #创建新的key:value对。
d1.copy() #浅复制一份字典
d2=dict() #创建一个空字典
#fromkeys(S[,v])方法表示创建一个新字典,新字典的key是来自第一个参数,值是可选的,默认是None,如果写了,则每个值都是一样的。
d3=d2.fromkeys(d1,'x')
#D.get(k[,d]),根据key获得值,如果key存在,则返回D[key],不存在则返回d,默认d就是None
d1.get('hello',5) #返回5,因为索引hello并不存在
#返回所有的键值对,键值对以元组展示,所有的元组存储在列表中
d1.items() #输出是形如dict_items([(1, 'x'), ('some', 2), (3, True)])
#d1.keys(),返回所有的key列表
d1.keys()
#d1.keys(),返回所有的key列表
d1.values()
#d1.pop(key[,v])输出指定key的值在屏幕上,并删除指定key的键值对,如果key不存在会报错。也可以指定key不存在时,返回的值。
d1.pop(1)
#随机删除一个键值对。
d1.popitem()
#D.setdefault(k[,v=none]),如果k存在,则返回D[k],不存在则创建D[k]=v。
d1.setdefault('z','helloworld')
’‘’
def update(self, E=None, **F): # known special case of dict.update
""" 更新
{'name':'alex', 'age': 18000}
[('name','sbsbsb'),]
"""
"""
D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k in F: D[k] = F[k]
"""
pass
‘’‘
d3 = {'name':'张三','age':18}
d1.update(d3,sex='male',hobby='coding')
{'some': 2, 3: True, 'name': '张三', 'age': 18, 'sex': 'male', 'hobby': 'coding'}
7. 枚举enumerate
为可迭代对象增加序列号:0,1,2,3...,默认从0开始,可以指定。
for k,v in enumerate(list(('name1','name2','name3'))):
#('name1','name2','name3')是一个元组,list括号只接一个参数,即可迭代对象,而元组是可迭代对象。enumerate括号也是传入的可迭代对象。
print(k,v)
8. range和xrange
8.1. python2.x
range()立刻在内存中生成数字序列。
xrange(1,10,3)生成可迭代的数字序列。左包,右不包。从1开始,到10终止,步长为3。
8.2. python3.x中
range等于xrange.
for i in range(1,10,3):
print(i)
9. 作业
'''
一、元素分类
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
二、查找
查找列表中元素,移除每个元素的空格,并查找以 a或A开头 并且以 c 结尾的所有元素。
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
三、输出商品列表,用户输入序号,显示用户选中的商品
商品 li = ["手机", "电脑", '鼠标垫', '游艇']
四、购物车
功能要求:
要求用户输入总资产,例如:2000
显示商品列表,让用户根据序号选择商品,加入购物车
购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。
附加:可充值、某商品移除购物车
1
2
3
4
5
6
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
五、用户交互,显示省市县三级联动的选择
1
2
3
4
5
6
7
8
9
10
11
12
13
dic = {
"河北": {
"石家庄": ["鹿泉", "藁城", "元氏"],
"邯郸": ["永年", "涉县", "磁县"],
}
"河南": {
...
}
"山西": {
...
}
}
'''
#第一题
'''
d1 = {}
list0 = [x*10+x for x in range(1, 10)]
list1 = []
list2 = []
for x in list0:
if x > 66:
list1.append(x)
elif x < 66:
list2.append(x)
d1['k1'] = list1
d1['k2'] = list2
print(d1)
'''
#第二题
'''
list0=[li,tu,dic.values()]
list1 = []
for j in list0:
for i in j:
i=i.strip()
if i.startswith('a') or i.startswith('A') and i.endswith('c'):
list1.append(i)
print(list1)
'''
#第三题
'''
li = ["手机", "电脑", '鼠标垫', '游艇']
for k, g in enumerate(li):
print(k,g)
while True:
choice = input('请输入商品序列号选择商品')
if choice.isdigit():
if 0<=int(choice)<=len(li):
print(li[int(choice)])
else:
break
'''
#第四题
'''
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
for k, v in enumerate(goods):
list1 = list(v.values())
print(k, list1[0], list1[1])
asset = int(input('请输入你的总资产:'))
list2 = []
sum = 0
dict1 = {}
while True:
choice = input('请输入序列号选择商品或或c清除商品或或m充值或q退出:>>>')
if choice.strip().isdigit():
num = int(choice)
if 0 <= num < len(goods):
if asset - goods[num]['price'] >= 0:
list2.append(goods[num]['name'])
asset = asset - goods[num]['price']
sum += goods[num]['price']
dict1[goods[num]['name']] = goods[num]['price']
print('购买商品%s成功,花费金额%s,总共消费金额%s,剩余金额%s' %
(goods[num]['name'], goods[num]['price'], sum, asset))
else:
print('余额不足,请充值')
elif choice.strip().lower() == 'c':
print('购物清单如下:')
set2 = set(list2)
list3 = []
for k, v in enumerate(set2):
print('序号:%s 数量:%s 商品:%s 总金额:%s' %
(k, list2.count(v), v, list2.count(v)*dict1[v]))
list3.append(v)
choice2 = int(input('请输入移除的商品序列号:>>>'))
list2.remove(list3[choice2])
asset = asset + dict1[list3[choice2]]
elif choice.strip().lower() == 'm':
money = int(input('请输入充值金额:>>>'))
asset = asset + money
elif choice.strip().lower() == 'q':
print('购买商品如下:')
set2 = set(list2)
for k, v in enumerate(set2):
print('序号:%s 数量:%s 商品:%s 总金额:%s' %
(k, list2.count(v), v, list2.count(v)*dict1[v]))
print('剩余金额%s' % asset)
break
else:
print('输入错误,请输入序列号')
'''
#第五题
'''
dic = {
"河北": {
"石家庄": ["鹿泉", "藁城", "元氏"],
"邯郸": ["永年", "涉县", "磁县"],
},
"河南": {
'郑州': ['郑一', '郑二'],
'开封': ['开一', '开二']
},
"山西": {
'太原': ['太一', '太二'],
'同大': ['同一', '同二']
}
}
for k, v in enumerate(dic.keys()):
print(k, v)
while True:
province_choice = int(input('请输入序号选择哪个省:>>>').strip())
if province_choice == 0:
list1=list(dic['河北'].keys())
for i in range(len(list1)):
print(i,list1[i] )
city_choice = int(input('请输入序号选择哪个市:>>>').strip())
if city_choice == 0:
list2 = dic['河北']['石家庄']
for j in range(len(list2)):
print(j,list2[j])
town_choice = int(input('请输入序号选择哪个县:>>>').strip())
if town_choice==0:
print(list2[0])
elif town_choice==1:
print(list2[1])
elif town_choice==2:
print(list2[2])
elif province_choice == 1:
pass
else:
pass
'''