import pandas as pd import numpy as np loginData = pd.read_excel("login0801.xlsx") #把空填0 loginData=loginData.fillna(0) print(loginData.head(10))
loginData=loginData[['user_id','1L','2L','3L','4L','5L','6L','7L']] #df.sum(axis=0):求和,默认对每一列求和;axis=1表示对每一行求和。 loginData=loginData.set_index('user_id') loginData['count']=loginData.sum(axis=1)
print(loginData.head(10)) #显示所有count的统计结果 #print(loginData['count'].value_counts())
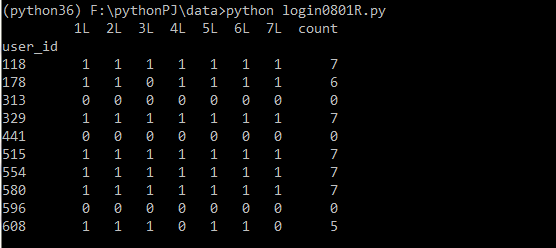

#显示0和7的统计 df0=loginData[loginData['count'].isin([0,7])] print(df0.shape[0]) #每个月都登录的店铺数 df1=loginData[loginData['count'].isin([7])] print(df1.shape[0])

#去掉0和7的显示 #df3=loginData[~loginData['count'].isin([0,7])]

import pandas as pd import numpy as np import datetime #查询 loginData = pd.read_excel("login_0729.xls") #未null补0 loginData=loginData.fillna(0) # 将数据类型转换为日期类型 loginData['date']=pd.to_datetime(loginData['login_date']).dt.normalize() # 将date设置为index loginData=loginData.set_index('date') #loginData.to_excel("a.xlsx") #输出2020-06-28到2020-07-28 的数据 #print(loginData.loc['2020-06-28':'2020-07-29'].head(10)) endData=loginData.loc['2020-06-28':'2020-07-29'] #print(endData.head(10)) #根据店铺和时间分组 #shop_data_group=endData.groupby(["shop_id","date"]) #print(shop_data_group.head(10)) #获取对应的用户ID userData= pd.read_excel("user.xlsx") userData=userData[['userId','shop_id']] #参考Excel的vlookup 把a表和b表同shopid数据 b复制到a df = pd.merge(endData, userData, how='left', on=['shop_id']) #df.to_excel("a2.xlsx") #根据店铺和时间分组 df2=df.groupby(["shop_id","date"]) df2.to_excel("a2.xlsx") #print(df.head(10))