1 Series
a:类似一维数组的对象,每一个数据与之相关的数据标签组成
b:生成的左边为索引,不指定则默认从0开始。
1 from pandas import Series,DataFrame 2 import pandas as pd 3 #series 一组数据与相关得数据标签组成 4 obj=Series([4,7,-5,3]) 5 obj#索引在左边 值在右边

c:可以通过values和index属性获取数组的表示形式和索引对象
1 obj.values#array([ 4, 7, -5, 3], dtype=int64) 2 obj.index
d:跟定索引值
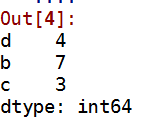
1 obj2=Series([4,7,-5,3],index=['d','b','a','c']) 2 obj2 3 obj2.index

e:通过索引值得到值
1 obj2['a'] 2 obj2[['c','a','d']] 3 obj2[obj2>0]
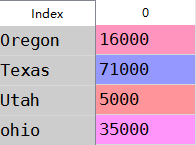
f:如果数据在python字典中 可以直接通过字典来创建Series
1 sdata={'ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000} 2 obj3=Series(sdata) 3 obj3
g:Series中非常重要的功能就是在多个Series运算的时候会自动匹配相同的索引进行操作
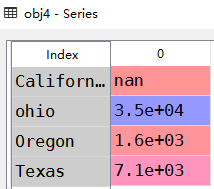
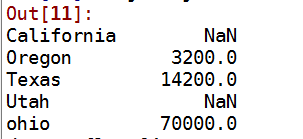
1 #如果数据在Python字典中 可以直接通过这个字典来创建Series 2 sdata={'ohio':35000,'Texas':7100,'Oregon':1600,'Utah':5000} 3 obj3=Series(sdata) 4 obj3 5 6 #如果只是传入一个字典 那么结果Series中索引就是字典得键 缺失为nan 7 states=['California','ohio','Oregon','Texas'] 8 obj4=Series(sdata,index=states) 9 10 #使用isnull notnull判断缺失值 11 12 13 #Series中一个非常重要的功能就是在算数运算中自动对其不同索引得数据 14 obj3 15 obj4 16 obj3+obj4

h:series中有个特别的属性 name属性
1 bj4.name='population' 2 obj4.index.name='state' 3 ob
