GROUP BY 是分组查询, 一般 GROUP BY 是和 聚合函数配合使用,你可以想想
你用了GROUP BY 按 ITEM.ITEMNUM 这个字段分组,那其他字段内容不同,变成一对多又改如何显示呢,比如下面所示
A B
1 abc
1 bcd
1 asdfg
select A,B from table group by A
你说这样查出来是什么结果,
A B
abc
1 bcd
asdfg
右边3条如何变成一条,所以需要用到聚合函数,比如
select A,count(B) 数量 from table group by A
这样的结果就是
A 数量
1 3
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面
order by 和group by的区别
order by 从英文里理解就是行的排序方式,
默认的为升序
order by 后面必须列出排序的字段名,可以是多个字段名。
它不需要查询结果中出现order by的栏位.
更改Order by里的栏位只会影响查询结果的顺序,而不影响查询出的记录总数,和每条记录的内容.
group by 从英文里理解就是分组。必须有“聚合函数”来配合才能使用,使用时至少需要一个分组标志字段。 什么是“聚合函数”?像sum()、count()、avg()等都是“聚合函数” 使用group by 的目的就是要将数据分类汇总。
group by是按指定的列对满足Where条件的所有记录分组,并对组内的一些数值型栏位计算出每组的一个统计指标,如求和、求个数、求平均值、求最大值、求最小值、、、、、、、
它对查询结果有个要求:查询结果中的出现的栏位必须是Group
by中栏位的子集。
更改Group by里栏位的顺序不会对查询结果有任何影响;
但是更改Group by的栏位,会对查询得到的记录数量,以及各个汇总函数的结果造成影响。
一般如:
select 单位名称,count(职工id),sum(职工工资) form [某表] group by 单位名称
这样的运行结果就是以“单位名称”为分类标志统计各单位的职工人数和工资总额。
在sql命令格式使用的先后顺序上,group by 先于 order by。
select 命令的标准格式如下:
SELECT select_list [INTO new_table] FROM table_source [WHERE
search_condition] [GROUP BY group_by_expression] [HAVING
search_condition] [ORDER BY order_expression [ASC|DESC]]
order by 是按字段排序
group by 是按字段分类
参考:http://wenku.baidu.com/view/a9aeaec75fbfc77da269b144.html
SQL中的Where,Group By,Order By和Having
说到SQL语句,大家最开始想到的就是他的查询语句:
select * from tableName;
这是最简单的一种查询方式,不带有任何的条件。
当然在我们的实际应用中,这条语句也是很常用到的,当然也是最简单的。在考虑到性能的时候,我们一般不这么写!具体怎么写,请关注后续的文章。。。
下面我们着重的看下文章标题所提到的几个子句。
一、Where
在英文中翻译为:在哪里,在什么地方。
在SQL语句中又该如何进行翻译呢?
如下一句:
select * from tableName where id="2012";
就是寻找表tableName中,id=2012的记录。
这里的where对查询的结果进行了筛选。只有满足where子句中条件的记录才会被查询出来。
对于where子句没什么高深的东西,而且也是最常见的东西,大家都太熟了。在这里不进行过多的介绍哈!
二、Group By
group by子句,我们放在select子句中的列必须也要放在group by子句中,除非在select子句中不指定任何列。 这句总感觉有问题?请大牛指点。
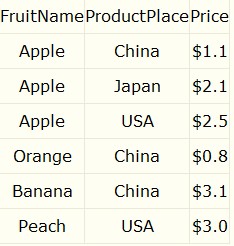
我们先看上面的这个表格,假如现在让你找出Apple在China,Japan,USA的平均价格,你怎么办?
我们可以这么做:select avg(price) from tablename where fruitname="apple";
Group By 一般是和一些聚合函数一起使用,比如上面我们用到的求平均的函数avg,还有求和sum,求个数count,求最大max,求最小min and so on.
对于上表,求每种水果的最大的价格:select fruitname,productplace,max(price) from tablename group by fruitname
Group By 还有一个重要的合作对象,他就是having
三、Having
我们用Group By 进行分组后,如何对分组后的结果进行一个筛选呢?having来帮您解决这个难题。
1.首先看一个例子:求平均价格在3.0以上的水果
如果我们使用这个:
select fruitname,avg(price) from tablename where avg(price)>=3.0 group by fruitname ;
这样能否达到我们的要求呢?
答案是否定的,因为where子句不能使用聚合函数。为了解决这个问题,我们来用下我们的杀手锏,他就是Having;
改写如下:select fruitname,avg(price) from tablename group by fruitname having avg(price)>=3.0;
2.我们继续看Having的另外一个匪夷所思
select fruitname,avg(price) from tablename group by fruitname having price<2.0;
这个查询的结果你们觉得会是什么呢?
没错,就是 orange 0.8 ;只有这一条记录
为什么呢?为什么Apple没有被查到呢,因为apple的有的价格超出了2.0.
另外运算符in也可以用在having 子句。
select fruitname,avg(price) from tablename group by fruitname having fruitname in ("orange","apple");
四、Order By
Order By是对查询的结果进行一个再排序的过程,一般放在查询语句的最后,可以是单列,也可以实现多列的排序。
分为升序asc和降序desc,默认的为升序。
Order By单列的排序比较简单,多列的也不麻烦。
select * from tablename group by friutname order by fruitname asc,price desc.
转自:http://blog.csdn.net/qitian0008/article/details/7840845