1. 朴素贝叶斯
贝叶斯决策理论方法是统计模型决策中的一个基本方法,基本思想如下:
(1) 已知类条件概率密度参数表达式和先验概率
(2) 利用贝叶斯公式转换成后验概率
(3) 根据后验概率大小进行决策分类。
贝叶斯概率研究的是条件概率,也就是研究的场景是在带有某些前提条件下,或者在某些背景条件的约束下发生的概率问题。贝叶斯公式:
设 D1、D2、...、Dn 为样本空间 S 的一个划分,如果以 P(Di) 表示 Di 发生的概率,且 P(Di) > 0 (i = 1, 2, ..., n)。对于任何一个事件 x, P(x) > 0,则有
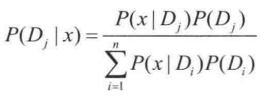
解释: 在一个样本空间里有很多事件发生, Di 就是指不同的事件划分,并且用 Di 可以把整个空间划分完毕,在每个 Di 事件发生的同时都记录事件 x 的发生, 并记录 Di 事件发生下 x 发生的概率。 等式右侧的分母部分就是 Di 发生的概率和 Di 发生时 x 发生的概率的加和, 所以分母这一项其实就是在整个样本空间里 x 发生的概率。 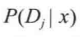 这一项是指 x 发生的情况下, Dj 发生的概率。不难看出,左侧和右侧分母项相乘得到的是在全样本空间里,在 x 发生的情况下,又发生 Dj 的情况的概率。右侧分子部分的含义是 Dj 发生的概率乘以 Dj 发生的情况下又发生 x 的概率。最后可化简为:
这一项是指 x 发生的情况下, Dj 发生的概率。不难看出,左侧和右侧分母项相乘得到的是在全样本空间里,在 x 发生的情况下,又发生 Dj 的情况的概率。右侧分子部分的含义是 Dj 发生的概率乘以 Dj 发生的情况下又发生 x 的概率。最后可化简为:

也就是说在,在全样本空间下,发生 x 的概率乘以在发生 x 的情况下发生 Dj 的概率,等于发生 Dj 的概率乘以在发生 Dj 的情况下发生 x 的概率。
贝叶斯分类器通常是基于这样一个假定: 给定目标值时属性之间相互条件独立。
举例: 假设某商品只有甲,乙,丙三家,市场占有率分别为 30%, 20%, 50%,他们次品率分别为 3%, 4%, 1%。上面的 x 就是指商品是次品这个事件。 指的就是商品是次品时,生产厂家是甲或乙或丙(也就是D1, D2, D3)的概率。
问题一: 购买此商品是次品的概率是多少?
此处就是求次品的全概率 = 30%*3% + 20%*4% + 50%*%1 这个全概率就是第一个公式中的分母。
问题二: 购买的商品是次品,求生产厂家分别是甲或乙或丙的概率?
利用第一个公式可得: 甲的概率 = 50%*1/全概率
2. 决策树归纳
比较好理解,如下图所示:
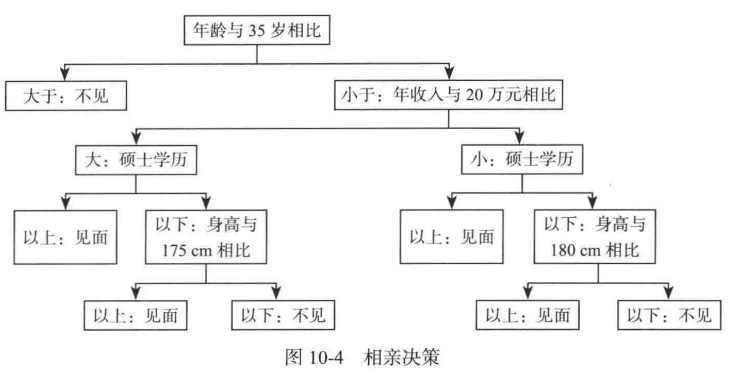
归纳过程:
(1) 样本收集。
以相亲为例,收集一个人看到各种条件的人后做出是否相亲的选择。这些数据为样本数据。
(2) 信息增益
整个样本的熵的计算如下(得出的值也叫期望信息):

m 的数量就是最后分类(决策)的种类,这个例子里 m 就是 2 --- 要么见面,要么不见。 pi 指的是这个决策项产生的概率。本例中有两个决策项,其概率就是两个决策项分别在结果集中出现的概率。
上面是以 “年龄与35岁相比”做为决策树的根,这是怎么得来的呢? 其实我们需要对样本数据用不同的字段(如身高,学历)来划分, 在这种划分规则下的熵为:

其中 v 表示一共划分为多少组。比如:如果以学历来划分并且有三种学历,则 v 就是3,pj 表示这种分组产生的概率,也可以认为是一种权重。 Info(Aj) 是在当前分组状态下的期望信息值。
用总体样本的期望信息减去以学历作为根计算出来的期望信息,就是信息增益。应该尝试其它字段做为根时的信息增益。信息增益越大,说明划分越有效。
注:需要对每个字段做计算以求得出较好的决策树模型,比较复杂。
3. 随机森林
随机森林算法会构造好棵树。当有新样本需要进行分类时,同时把这个样本给这几棵树,然后用类似民主投票表决的方式来决定新样本应该归属于哪类,哪一类得票多就归为哪一类。构建步骤:
(1) 随机挑选一个字段构造树的第一层,
(2) 随机挑选一个字段构造树的第二层;
。。。
(3) 随机挑选一个字段构造树的第n层;
(4) 在本棵树建造完毕后,还需要照这种方式建造 m 棵决策树。
4. 隐马尔可夫模型(Hidden Markov Model -- HMM)
马尔可夫链的核心是:在给定当前知识或信息的情况下,观察对象过去的历史状态对于预测将来是无关的。
假设有三种骰子(6面,4面,8面),随机抽一个骰子,掷出一个数字并记录。循环多次后,会得到一串数字。在隐马尔可夫模型中,不仅仅有这么一串可见状态链,还有一串隐含状态链,就是选出的骰子的序列。
一般来说, HMM 中的马尔可夫链其实就是指隐含状态链,因为实际是隐含状态(所选骰子)之间存在转换概率。
和 HMM 模型相关的算法主要分为3类,分别解决3种问题:
(1) 知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题在语音识别领域叫做解码问题。这个问题其实有两种解法。一种解法求最大似然状态路径。通俗地说就是求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法是求每次掷出的骰子分别是某种骰子的概率。
(2) 知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),想知道掷出这个结果的概率。
这个问题的目的其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明已知的模型很有可能是错的。
(3) 知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测多次掷骰子的结果(可见状态链),想反推出每种骰子是什么(转换概率)。
5. SVM(支持向量机)
支持向量机。样本中含N 个维度,当无法在 N 维空间上划分这些样本时,可以通过升维的方式,使得 N 维空间上的分类边界是 N + 1 维上的分类函数在 N 维空间上的投影。
使用核函数(Kernel) 进行构造高维的函数,常用的核函数是可以拿来直接使用的。如线性核函数、多项式核函数、径向基核函数(RBF核函数)、高斯核函数等。
SVM 解决问题的方法大概有以下几步:
(1) 把所有的样本和其对应的分类标记交给算法进行训练
(2) 如果发现线性可分,就直接找出超平面
(3) 如果发现线性不可分,那就映射到 n + 1维空间, 找出超平面
(4) 最后得到超平面的表达式,也就是分类函数
6. 遗传算法
遗传算法是处理问题的一种思想。以 0-1 背包问题为例,假设有6个物品(物品很少,可以用穷举法,这里仅作为说明),以下为大概的步骤
(1) 基因编码。 取某一物品的话,就标为1,不取就标为0
(2) 设计初始群体。 可以设计随机生成4个初始生物个体,假设随机的4个基因序列为: 101101, 011001, 100100, 110010
(3) 适应度计算。首先要用一个适应度的函数来做标尺。
此例适应度函数为物品的总价值。淘汰总质量不符全要求的。假设剩下的基因为前3个,各个基因的总价值分别为 62, 85, 103,其和为 62+85+103= 250,根据各自总价值所占的比例(即 62/250, 85/250, 103/250), 利用类似轮船堵来选择哪几个基因可以产生下一代。
(4) 产生下一代。上面得出的基因中,以某个位置为交叉点,进行基因重组。即一个基因在交叉点的前半段与另一个基因在交叉点的后半段组成一个新的基因。这样就组成了新的一代
(5) 迭代计算。 重复(3),(4)。如果发现连续几代适应度基本不增加甚至减少,则说明函数已经收敛了。则基本为我们所求的值。注意这个解并不一定是最优解。
遗传算法的注意事项:
(1) 初始群体的数量。 初始数量太少可能会导致在向量空间中覆盖面积过小而导致收敛琶了非最优解就终止了算法。
(2) 适应度函数。上面的轮盘赌算法只是一种算法。需要注意的是,淘汰比较弱的基因是可以的,但是不建议淘汰的比例太大。
(3) 基因重组。这个环节是变数比较大的。断开的位置几乎是可以随意进行的。