机器学习中用到的一些统计方面的概念。
1. 标准差
公式:
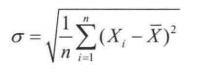
假设一个班有30个学生,每个学生的语文课的考试成绩是 Xi, 平均分是80,标准差 不是每个学生的成绩减去平均分的平方的和,再除以学生数,然后再开方。
意义: 标准差越大,表示学生之间的水平相差较大。
2. 加权均值
平均值计算时,按照权重的。比如股东大会的投票,股权多的人,虽然也只是一票,但是这一票代表的权重是不一样的。
3. 中位数
用中位数来描述样本的分布,在一定程度上可以消除个别极端值对整体样本的影响。常见的应用是去掉一个最高值和最低值,然后求平均。
4. 欧式距离
定义:在一个N维度的空间里,求两个点的距离。这个距离需要用两个点在各个维度的坐标相减,平方后加和再开方。
二维应用: 勾股定理
5. 曼哈顿距离(出租车距离)
定义:两个点在标准坐标系上的绝对轴距总和。 c = | y1-y2 | + | y1-y2 |
应用:计算棋盘上两子之间经过的格数。还有可以方便的计算两个街区之间的经过的街区数。
6. 同比和环比
如:今年7月份的销售额同比增长80%,环比增长 20%。
同比是指与相邻时段的同一时期相比。 上面的意思是 今年7月份比去年7月份增长80%。
环比是指跟上一个报告期相比。上面的意思是 今年7月比今年6月增长20%。注意:对于周期性比较明显的产业,比如网吧什么的,环比并不能代表经营的好坏。比如7,8月份,学生放假,营业额会高。9月份开学后,就降低了。
7. 抽样
抽样需要注意抽取的样品要有代表性。
8. 高斯分布(又称正态分布)
高斯分布的概率密度函数:
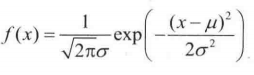 exp 是指自然常数 e 的幂函数,即 e 的多少次幂的概念
exp 是指自然常数 e 的幂函数,即 e 的多少次幂的概念
曲线图:
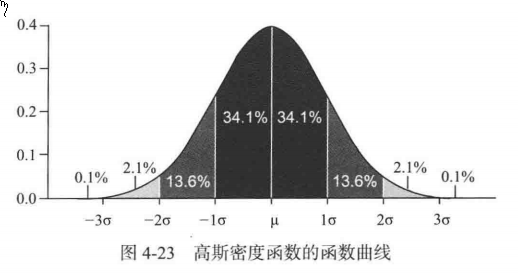
高斯分布所表现出的分布特点就是: 一般般的很多,极端的较少。
如对某地区1000名男性进行身高抽样,结果发现身高是一个 μ = 175cm 的高斯分布, σ=10cm。那么这样一个说明,就可以得出下面的结论:
身高在 165~175 大约有341人, 身高在 175~185 大约有 341人, 155~165 大约有 136人, 185~195 的人大约有 136人。 这几项加起来,就覆盖了 95.4% 的样本, 如果再多加一个 σ 的话,就涵盖了 99.6% 的样本了。
9. 泊松分布
泊松分布适用于描述单位时间内随机事件发生的次数。也就是说在一个标准时间里,发生这件事的发生率是λ 次(这是一个具体的数字,不是一个概率值),那发生 k 次的概率是多少。公式:
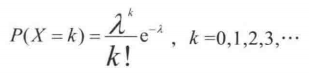 参数 λ 是单位时间(或单位面积)内随机事件的平均发生率
参数 λ 是单位时间(或单位面积)内随机事件的平均发生率
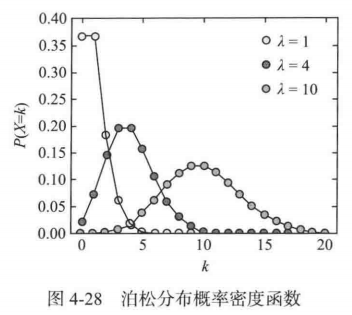
泊松分布适用的事件需要满足以下3个条件:
(1) 这个事件是一个小概率的事件 (2) 事件的每次发生是独立的,不会相互影响。 (3) 事件的概率是稳定的。
例子: 假设在一个公共汽车站上有很多不同线路的公交车,而且平均每5分钟会来 2 辆公交车,求 5分钟内来5辆公交车的概率有多大?
此例中, λ = 2, k = 5 , 那么  , 得出的概率为 3.61%
, 得出的概率为 3.61%
一个结合泊松分布和累积概率的例子: 有一家书店,新华字典销售一直较为稳定而且数量较少(概率较小的事件),平均每周卖出4套。作为书店老板,新华字典应该备多少本为宜?
这里 λ= 4,求 k 为多少比较合适。 我们可以先求出 k 所对应的各个概率的大小,如下:
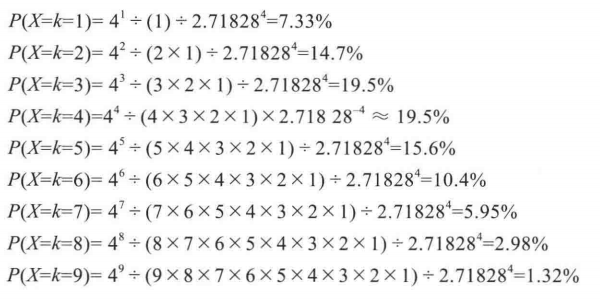
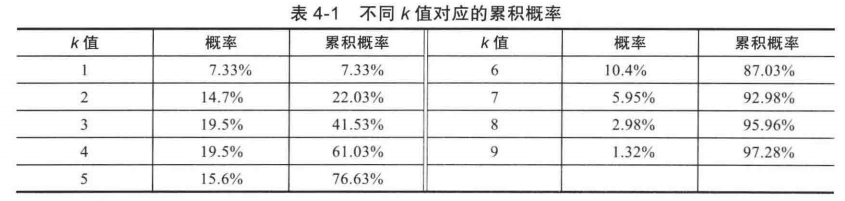
从上表可以看出,在备货为5件的情况下,大概有 76.63%的销售周不会有供不应求的情况,这些销售周内会有 7.33% 的销售周卖出 1 本, 14.7% 的销售周卖出 2 本。。。也就是说一年52周,大概有 40周满足销售需求。k 值增大为 7 时,大概 92.98% 的销售周不会有供不应求的情况。
也可以看出, k 小于 λ 的时候,累积函数增加很快,而且每次增加的量要比上一次多。
10. 伯努力分布
伯努力分布的分布率:
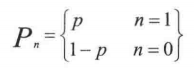 也可以写成:
也可以写成: 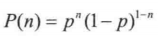
伯努力分布的应用需满足以下条件:
(1)各次试验中的事件是互相独立的,每一次 n=1 和 n=0 的概率分别为 p 和 q
(2)每次试验都只有两种结果,即 n=0 或 n=1
满足伯努力分布的样本有一个非常重要的性质,即满足公式: 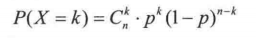
说明: X 指的是试验次数, 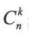 指的是组合,
指的是组合,  指的就是 p 的 n 次幂与 (1-p) 的 n-k 次幂的乘积。
指的就是 p 的 n 次幂与 (1-p) 的 n-k 次幂的乘积。
这个公式表示, 如果一个试验满足 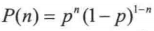 的伯努力分布,那么在连续试验 n 次的情况下,出现 n=1的情况发生恰好 k 次的概率为
的伯努力分布,那么在连续试验 n 次的情况下,出现 n=1的情况发生恰好 k 次的概率为 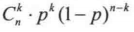 。 n=1就是对应概率为 p 的情况。
。 n=1就是对应概率为 p 的情况。
例如: 李四参加雅思考试,每次考试通过的概率为 1/3, 不通过的概率为 2/3。如果他连续考试 4 次,那么恰好通过 2 次的概率为多少?
此例中 p=1/3, n=4,k=2, 代入公式得到 8/27