1. 想用 sqoop 增量的方式导入到 hive。运行下面的命令:
sqoop import --connect jdbc:mysql://192.168.7.159:3306/test
--username root --password 123456
--query "select name, age, dept, update_dt from emp WHERE $CONDITIONS"
--hive-import --hive-database default --hive-table emp_tmp
--target-dir /warehouse/tablespace/managed/hive/emp_tmp
--fields-terminated-by '�01' --incremental lastmodified
--check-column update_dt --last-value '2018-03-21' --append -m 1
错误提示: --incremental lastmodified option for hive imports is not supported
我晕, --incremental lastmodified 和 --hive-import 竟然不能同时使用。把 lastmodified 改成 append 后就可以运行了。看了 sqoop 的官方文档,append 通常用于自增的 id 列,lastmodified 用于更新的日期列,日期同样也可以比较大小啊,有点不明白为什么 lastmodified 不可以。
2. 上面命令中,如果去掉 “--hive-import --hive-database default --hive-table emp_tmp” 后,同样可以导入数据,在 hive 中运行 select * from emp_tmp 可以看到有数据,但是运行 select count(1) from emp_tmp 出来的结果是 0
3. 上面命令中 “-m” 指定有多少个 map 任务,如果任务数大于 1,则需要额外指定 --split-by <分割列>
4. 用下面的命令可以创建一个 job。
sqoop job --create emp_job -- import
--connect jdbc:mysql://192.168.7.159:3306/test
--username root --password 123456
--query "select name, id, age, dept, update_tm from emp where $CONDITIONS"
--target-dir /warehouse/tablespace/managed/hive/emp
--fields-terminated-by '�01' --hive-delims-replacement ' '
--null-string "" --null-non-string ""
--hive-import --hive-database default --hive-table emp
--incremental lastmodified --check-column update_tm --last-value '1980-01-01 00:00:00' --append -m 1
使用 sqoop job --exec emp_job 就可以进行一次导入了,sqoop 会自动记录上一次的更新时间,用于替换以后跑这个 job 时 last-value 的值
5. 怎么查询 sqoop 的 job 每次用到的 last-value 的值?
找到 metastore.db.script 这个文件所在的位置,打开它,搜索 incremental.last.value ,每个 job 都会对应一个。
find / -name metastore.db.script
2. 查询表中的记录时,出现 ORC split generation failed with exception: org.apache.orc.FileFormatException: Malformed ORC file 的异常
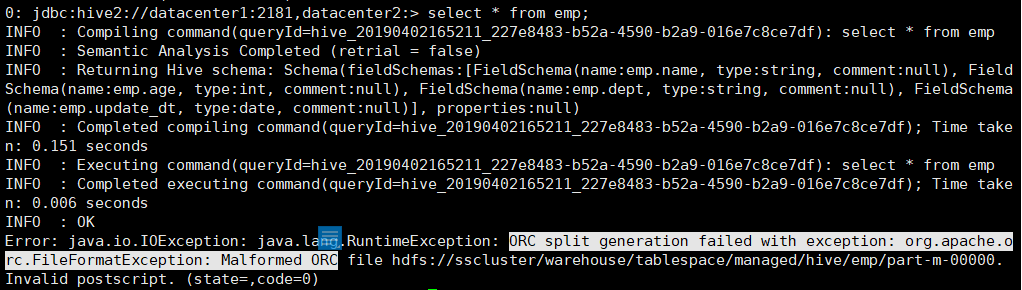
原因:HDP 的 hive 中设置了默认存储格式为 ORC, 用 sqoop 增量方式导入 emp 表时,使用的是 textfile 的格式。所以查询时就出现这个问题。很奇怪,sqoop 可以指定 avro,parquet 等格式,唯独没有 ORC 格式。