协同过滤有两种思路:
(1) 邻居方法
(a) 基于用户。系统通过分析一个用户和哪些用户的特征比较像,然后看看这些用户喜欢买哪类的商品,再从这些商品里挑出一些推荐给该用户。
(b) 基于商品。系统通过分析用户的购买行为来判断用户喜欢的商品类型,然后从那些用户喜欢的商品类型里挑出一些推荐给用户。
(2) 基于模型的推荐算法。
1. 基于用户的协同过滤
以下面的用户与商品偏好为例,0 为没有兴趣, 10为非常有兴趣。量化的方法可以从用户给产品的反馈打分上去看,也可以从他购买的频繁程度上去看,也可以从他浏览的频繁程度上去看。商品的分类到底是大类还是更小的分类,可以通过实践作调整。
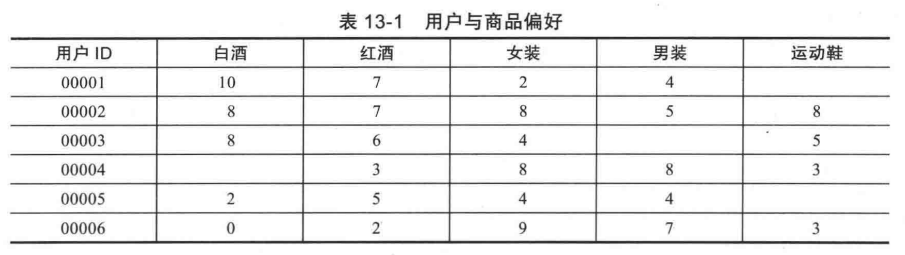
若以 用户 00001 为研究对象,要找到和他兴趣最接近的人,怎么做比较才好?可以使用余弦相似性。利用以下的公式计算
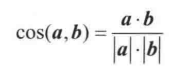
其中 a,b 都是空间向量。如果它们方向一致,结果是1,表示很相似。那么计算用户 00002 和 用户 00001 的已知部分的爱好相似程度:
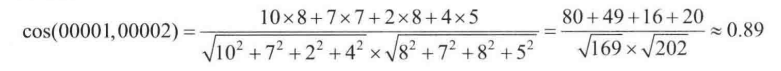
2. 基于商品的协同过滤
中心思想是“很多人喜欢商品A, 同时他们也喜欢商品 B,所以 A 和 B 应该是比较类似的商品。”
(1) 计算商品之间的相似度
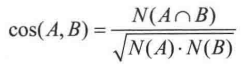
其中分子是同时喜欢A 和 B 两个商品的用户数量,分母是喜欢A的用户数量和喜欢 B 的用户数量的乘积的平方根