背景
我在[第一篇文章中]已经介绍了如何实现一个多线程的todo应用,接下来我将会研究如何使这个服务器完成下面这几个功能。
- 1.使用正则表达式解析用户发送的请求数据;
- 2.使用
ThreadLocal技术; - 3.让浏览器也能够访问我们的服务器;
客户端数据解析
对于当前客户端数据解析是存在问题的,当一条命令包含了GET就进行GET操作是不正确的,例如当用户输入一条下面的命令。
AttackeGET/task_01/ok
服务器同样会给出查询结果,这个问题我们可以通过使用正则表达式来解决并且对比GET字符命令是否匹配,例如下面的方式实现。
if method == 'GET':
pass
解析用户请求,与发送用户请求应该是两部分工作,是可以分离的。所以可以新建一个文件parser.py并且编写一个解析类如下。
import re
class ClientRequestParser:
def __init__(self, data, db):
"""
The `data` is string from client side!
"""
try:
pattern = re.compile(r'(?P<method>.*)/(?P<command>.*)/(?P<status>.*)')
m = pattern.match(data)
self.request_data=m.groupdict()
self.request_method = self.request_data.get('method','No Key Found')
self.db=db
except :
print 'client command error'
self.request_method = 'no method'
def get(self, db, task_id):
response = db.get(task_id,'Key No Found')
return response
def post(self,db, command):
pattern = re.compile(r'(?P<key>.*)=(?P<value>.*)')
m = pattern.match(command)
post_data = m.groupdict()
key=post_data.get('key','Key No Found')
value=post_data.get('value','Key No Found')
db[key]=value
response='submit success'
return response
def response(self):
response=''
if self.request_method == 'GET':
print 'Get method'
task_id=self.request_data.get('command','No Key Found')
response=self.get(self.db, task_id)
elif self.request_method == 'POST':
command=self.request_data.get('command','No Key Found')
response=self.post(self.db, command)
else:
response = 'client request error'
response=response+'
'
return response
通过把解析用户请求的数据分离后,在回复用户请求时的逻辑就非常简单了。
import socket
import threading
from parser import ClientRequestParser
class ThreadSocket(object):
"""
"""
todo_list = {
'task_01':'see someone',
'task_02':'read book',
'task_03':'play basketball'
}
def __init__(self, host, port):
self.host = host
self.port = port
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.sock.bind((self.host, self.port))
def listen(self):
self.sock.listen(5)
while True:
client, address = self.sock.accept()
client.settimeout(60)
threading.Thread(target=self.handleClientRequest, args=(client, address)).start()
def handleClientRequest(self, client, address):
while True:
try:
data = client.recv(1024)
if data:
response=ClientRequestParser(data=data,db=self.todo_list).response()
client.send(response)
else:
raise error("Client has disconnected")
except:
client.close()
if __name__ == '__main__':
server=ThreadSocket('',9000)
server.listen()
所有代码可以通过git checkout v0.7获得,运行测试结果如下。

可以发现我们的设计目标同样实现了,那么到目前为止我们都没有测试多个客户端发起请求时会出现什么情况,下面测试两个终端模拟客户发起请求的运行截图。
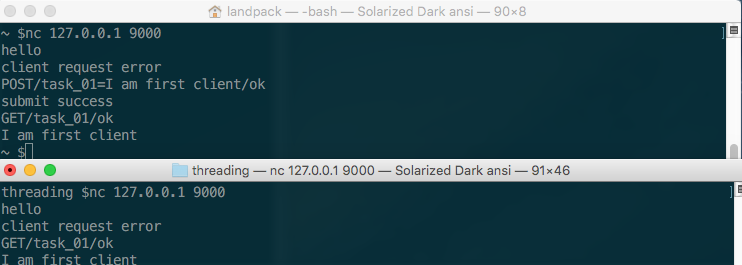
使用Thread Local技术
从上一节的运行截图的结果可以发现,第二个客户端访问服务器时也能看到你一个用户所POST的数据,这就会导致数据的不安全。那么如何才能让每一个线程又拥有自己独立的空间呢?这个就需要使用到ThreadLocal技术了,下面一起来看看代码如何实现。
首先在ThreadSocket类之前定义下面这个local实例,如下代码所示。
local = threading.local()
然后在ThreadSOcket类中listen方法中传递local参数。
threading.Thread(target=self.handleClientRequest, args=(client, address, local)).start()
并且把handleClientRequest也修改为接收local参数的方法。
def handleClientRequest(self, client, address,local):
local.todo_list = {}
最后修改ClientRequestParser的传人参数。
response=ClientRequestParser(data=data,db=local.todo_list).response()
当前的代码可以通过git checkout v0.8获得,运行结果如下:
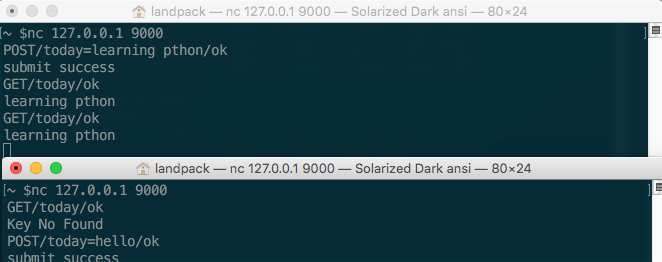
可以发现,第一个客户端所POST的数据与第二个客户端是完全分开的,他们的空间是彼此独立的。
修复BUG
到目前为止我一直都没有谈到程序中存在的几个bug原因很简单,我想把主要思路先理清楚。然而随着项目的扩大bug一直存在难免会照成很多不可预知的后果,所以现在让我先把他们列出来。
- 1.客户端没有任何提醒就断开连接 (套接字设置了超时或者是服务器端出现错误,但是异常捕获后没有提醒只是简单的关闭连接);
- 2.当客户端超时后断开连接了,子线程无法退出。(因为
client.close()执行完成后,没有调用break语句,从而导致子线程不断的循环读取已经释放的套接字); - 3.在异常处理阶段,没有实现
raise error("Client has disconnected")中的error方法; - 4.使用
CTRL+C无法中断服务器(主要原因是由于第二点列出的原因造成的,只要增加break就可以解决);
修复后的代码可以通过git checkout v0.8a获得。
支持浏览器访问
要让浏览器去访问服务器,就必须要实现http协议了。什么是http协议呢?我不打算用一大串文字去叙述,显然那是在重复造轮子而且造的轮子还不一定标准,相信你会找到适合自己理解的文档去理解什么是http协议的,下面首先让你体验一下浏览器发送请求给服务器的时候都会发送什么数据。打开一个终端使用下面的命令运行一段程序。
nc -l 0.0.0.0 9090
运行命令后服务器处于监听状态,可以使用你的浏览器访问下面这个地址。
http://127.0.0.1:9090
可以看到,你所打开的终端出现下面一下客户请求数据。
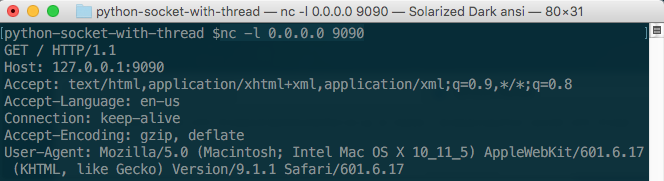
这个时候,你如果想了解每一行输出代表什么意思,可以查看http相关文档了。注意到我们的浏览器状态是一直阻塞等待着服务器回复的,运行结果如下。

现在要思考的问题就是我们怎么去回复这个浏览器呢?要想知道服务器返回什么给客户端,可以继续使用nc命令。下面使用nc这把网络瑞士军刀防伪百度主页。
nc www.baidu.com 80
当你输入完这个命令后会要求你输入一些数据而这些数据就是一个浏览器应该发起http请求的数据,下面我们可以新建一个文件为request.txt文件。
GET / HTTP/1.1
Host: www.baidu.com
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us
Connection: keep-alive
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/601.6.17(KHTML, like Gecko) Version/9.1.1 Safari/601.6.17
注意到我把主机Host由原来的127.0.0.1 9000改为了指向www.baidu.com这个应该很容易理解的。回车两次后就可以得到如下的输出结果。下面首先把输出截图附上。
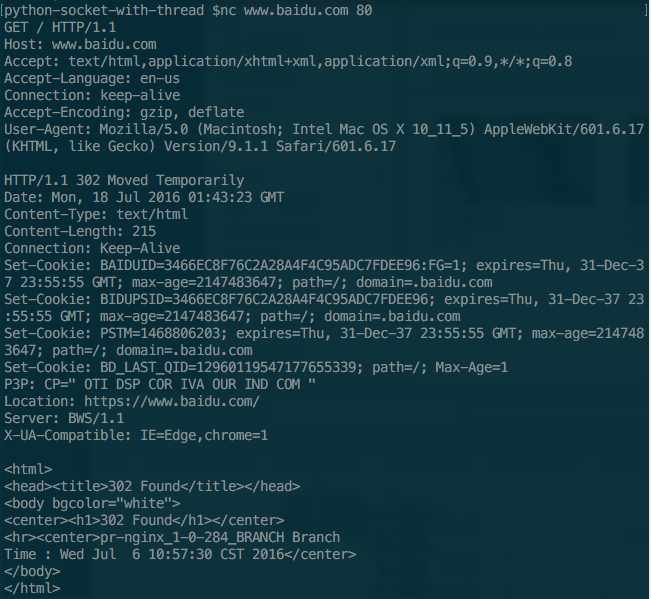
上面的截图是百度的服务器反馈截图,我们不能完全照搬别人的服务器数据我们需要修改的项目如下。
-
- 第一行的
HTTP/1.1 302 Moved Temporarily修改为HTTP/1.1 OK;
- 第一行的
-
- 删除那些
cookie设置项等;
- 删除那些
下面是我们的服务器应该反馈的输出文本文件以便你复制粘贴,当然当前的所有代码文件你都可以在我的 [github] 上获得。
HTTP/1.1 OK
Date: Mon, 18 Jul 2016 01:43:23 GMT
Content-Type: text/html
Content-Length: 215
Connection: Keep-Alive
Location: https://127.0.0.1:9000/
Server: BWS/1.1
X-UA-Compatible: IE=Edge,chrome=1
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>pr-nginx_1-0-284_BRANCH Branch
Time : Wed Jul 6 10:57:30 CST 2016</center>
</body>
</html>
现在我们知道服务器需要符合这样的格式这样一些数据浏览器才能够解析识别,如果你不理解什么是http协议的话可能对response.txt文件的前面部分会比较陌生,但是当你看到后半部分的时候,你会发现那是你熟悉的html协议。很多人经常把两者搞混,甚至有些人认为html不就是http协议吗?这些都是基础不扎实。那么我们回到服务器设计上来,我们需要服务器应答那些必要的数据。
首先,我们需要将文件response.txt加载称为一个字符串以备发送,在shell运行下面的命令可以实现这个读取功能。
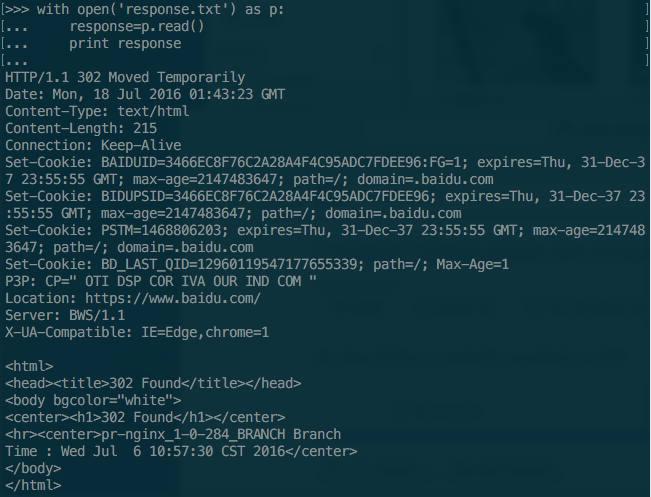
好啦,知道怎么实现这个功能后,咱们可以设计一个简单的make_response方法,下面让我们修改一下paser.py文件。
def response(self):
response=''
if self.request_method == 'GET':
print 'Get method'
task_id=self.request_data.get('command','No Key Found')
response=self.get(self.db, task_id)
elif self.request_method == 'POST':
command=self.request_data.get('command','No Key Found')
response=self.post(self.db, command)
else:
response = 'client request error'
response=response+'
'
#return response
return self.make_response(response)
def make_response(self,response):
response=''
with open('response.txt') as p:
response=p.read()
return response
你可以发现我们多增加了一个方法,并且修改了response方法的最后一行代码。当前版本的代码可以通过git checkout v0.9获得,下面可以测试一下运行效果。

为了进行下一步,我觉得对于http我们有必要了解下面这一行的意义。
Content-Length: 215
它指代的是html文件资源的大小,浏览器需要服务器提供这个参数以便解析展现到页面。那么下面我们如何分离这个html出来呢?有几点工作需要我们去做。
1.分离http头部与html分离;
2.实现html资源大小计算功能,并且把计算值填充到http的相关域中。
下面使用shell演示我们需要的效果。
注意在使用谷歌浏览器Chrome访问服务器时,如果服务器提供的html不完整会自动补全,那么这个过程可能会影响对http头部Content-Length域的理解。
总结
这篇本来早就写好了,一直没有来得及发布。主要是这段时间找工作哈!
[github]:https://github.com/landpack/python-socket-with-thread