Lambda and Anonymous Classes(I)
前言
Java Lambda表达式的一个重要用法是简化某些匿名内部类(Anonymous Classes)的写法。实际上Lambda表达式并不仅仅是匿名内部类的语法糖,JVM内部是通过invokedynamic指令来实现Lambda表达式的。具体原理放到下一篇。本篇我们首先感受一下使用Lambda表达式带来的便利之处。
取代某些匿名内部类
本节将介绍如何使用Lambda表达式简化匿名内部类的书写,但Lambda表达式并不能取代所有的匿名内部类,只能用来取代函数接口(Functional Interface)的简写。先别在乎细节,看几个例子再说。
例子1:无参函数的简写
如果需要新建一个线程,一种常见的写法是这样:
// JDK7 匿名内部类写法
new Thread(new Runnable(){// 接口名
@Override
public void run(){// 方法名
System.out.println("Thread run()");
}
}).start();
上述代码给Tread类传递了一个匿名的Runnable对象,重载Runnable接口的run()方法来实现相应逻辑。这是JDK7以及之前的常见写法。匿名内部类省去了为类起名字的烦恼,但还是不够简化,在Java 8中可以简化为如下形式:
// JDK8 Lambda表达式写法
new Thread(
() -> System.out.println("Thread run()")// 省略接口名和方法名
).start();
上述代码跟匿名内部类的作用是一样的,但比匿名内部类更进一步。这里连接口名和函数名都一同省掉了,写起来更加神清气爽。如果函数体有多行,可以用大括号括起来,就像这样:
// JDK8 Lambda表达式代码块写法
new Thread(
() -> {
System.out.print("Hello");
System.out.println(" Hoolee");
}
).start();
例子2:带参函数的简写
如果要给一个字符串列表通过自定义比较器,按照字符串长度进行排序,Java 7的书写形式如下:
// JDK7 匿名内部类写法
List<String> list = Arrays.asList("I", "love", "you", "too");
Collections.sort(list, new Comparator<String>(){// 接口名
@Override
public int compare(String s1, String s2){// 方法名
if(s1 == null)
return -1;
if(s2 == null)
return 1;
return s1.length()-s2.length();
}
});
上述代码通过内部类重载了Comparator接口的compare()方法,实现比较逻辑。采用Lambda表达式可简写如下:
// JDK8 Lambda表达式写法
List<String> list = Arrays.asList("I", "love", "you", "too");
Collections.sort(list, (s1, s2) ->{// 省略参数表的类型
if(s1 == null)
return -1;
if(s2 == null)
return 1;
return s1.length()-s2.length();
});
上述代码跟匿名内部类的作用是一样的。除了省略了接口名和方法名,代码中把参数表的类型也省略了。这得益于javac的类型推断机制,编译器能够根据上下文信息推断出参数的类型,当然也有推断失败的时候,这时就需要手动指明参数类型了。注意,Java是强类型语言,每个变量和对象都必需有明确的类型。
简写的依据
也许你已经想到了,能够使用Lambda的依据是必须有相应的函数接口(函数接口,是指内部只有一个抽象方法的接口)。这一点跟Java是强类型语言吻合,也就是说你并不能在代码的任何地方任性的写Lambda表达式。实际上Lambda的类型就是对应函数接口的类型。Lambda表达式另一个依据是类型推断机制,在上下文信息足够的情况下,编译器可以推断出参数表的类型,而不需要显式指名。Lambda表达更多合法的书写形式如下:
// Lambda表达式的书写形式
Runnable run = () -> System.out.println("Hello World");// 1
ActionListener listener = event -> System.out.println("button clicked");// 2
Runnable multiLine = () -> {// 3 代码块
System.out.print("Hello");
System.out.println(" Hoolee");
};
BinaryOperator<Long> add = (Long x, Long y) -> x + y;// 4
BinaryOperator<Long> addImplicit = (x, y) -> x + y;// 5 类型推断
上述代码中,1展示了无参函数的简写;2处展示了有参函数的简写,以及类型推断机制;3是代码块的写法;4和5再次展示了类型推断机制。
自定义函数接口
自定义函数接口很容易,只需要编写一个只有一个抽象方法的接口即可。
// 自定义函数接口
@FunctionalInterface
public interface ConsumerInterface<T>{
void accept(T t);
}
上面代码中的@FunctionalInterface是可选的,但加上该标注编译器会帮你检查接口是否符合函数接口规范。就像加入@Override标注会检查是否重载了函数一样。
有了上述接口定义,就可以写出类似如下的代码:
ConsumerInterface<String> consumer = str -> System.out.println(str);
进一步的,还可以这样使用:
class MyStream<T>{
private List<T> list;
...
public void myForEach(ConsumerInterface<T> consumer){// 1
for(T t : list){
consumer.accept(t);
}
}
}
MyStream<String> stream = new MyStream<String>();
stream.myForEach(str -> System.out.println(str));// 使用自定义函数接口书写Lambda表达式
参考文献
- The Java® Language Specification
- http://viralpatel.net/blogs/lambda-expressions-java-tutorial/
- 《Java 8函数式编程 [英]沃伯顿》
Lambda and Anonymous Classes(II)
前言
读过上一篇之后,相信对Lambda表达式的语法以及基本原理有了一定了解。对于编写代码,有这些知识已经够用。本文将进一步区分Lambda表达式和匿名内部类在JVM层面的区别,如果对这一部分不感兴趣,可以跳过。
不是匿名内部类的简写
经过第一篇的的介绍,我们看到Lambda表达式似乎只是为了简化匿名内部类书写,这看起来仅仅通过语法糖在编译阶段把所有的Lambda表达式替换成匿名内部类就可以了。但实时并非如此。在JVM层面,Lambda表达式和匿名内部类有着明显的差别。
匿名内部类实现
匿名内部类仍然是一个类,只是不需要程序员显示指定类名,编译器会自动为该类取名。因此如果有如下形式的代码,编译之后将会产生两个class文件:
public class MainAnonymousClass {
public static void main(String[] args) {
new Thread(new Runnable(){
@Override
public void run(){
System.out.println("Anonymous Class Thread run()");
}
}).start();;
}
}
编译之后文件分布如下,两个class文件分别是主类和匿名内部类产生的:
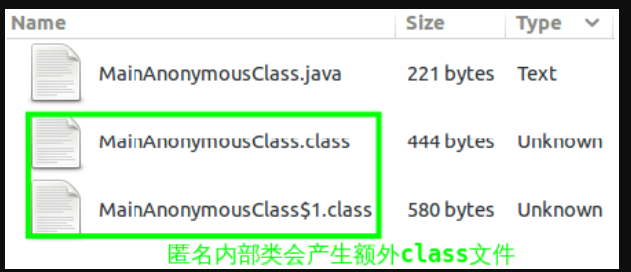
进一步分析主类MainAnonymousClass.class的字节码,可发现其创建了匿名内部类的对象:
// javap -c MainAnonymousClass.class
public class MainAnonymousClass {
...
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/Thread
3: dup
4: new #3 // class MainAnonymousClass$1 /*创建内部类对象*/
7: dup
8: invokespecial #4 // Method MainAnonymousClass$1."<init>":()V
11: invokespecial #5 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V
14: invokevirtual #6 // Method java/lang/Thread.start:()V
17: return
}
Lambda表达式实现
Lambda表达式通过invokedynamic指令实现,书写Lambda表达式不会产生新的类。如果有如下代码,编译之后只有一个class文件:
public class MainLambda {
public static void main(String[] args) {
new Thread(
() -> System.out.println("Lambda Thread run()")
).start();;
}
}
编译之后的结果:
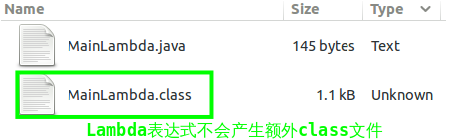
通过javap反编译命名,我们更能看出Lambda表达式内部表示的不同:
// javap -c -p MainLambda.class
public class MainLambda {
...
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/Thread
3: dup
4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable; /*使用invokedynamic指令调用*/
9: invokespecial #4 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V
12: invokevirtual #5 // Method java/lang/Thread.start:()V
15: return
private static void lambda$main$0(); /*Lambda表达式被封装成主类的私有方法*/
Code:
0: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #7 // String Lambda Thread run()
5: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
}
反编译之后我们发现Lambda表达式被封装成了主类的一个私有方法,并通过invokedynamic指令进行调用。
推论,this引用的意义
既然Lambda表达式不是内部类的简写,那么Lambda内部的this引用也就跟内部类对象没什么关系了。在Lambda表达式中this的意义跟在表达式外部完全一样。因此下列代码将输出两遍Hello Hoolee,而不是两个引用地址。
public class Hello {
Runnable r1 = () -> { System.out.println(this); };
Runnable r2 = () -> { System.out.println(toString()); };
public static void main(String[] args) {
new Hello().r1.run();
new Hello().r2.run();
}
public String toString() { return "Hello Hoolee"; }
}
参考文献
http://cr.openjdk.java.net/~briangoetz/lambda/lambda-state-final.html
Lambda and Collections
前言
我们先从最熟悉的Java集合框架(Java Collections Framework, JCF)开始说起。
为引入Lambda表达式,Java8新增了java.util.function包,里面包含常用的函数接口,这是Lambda表达式的基础,Java集合框架也新增部分接口,以便与Lambda表达式对接。
首先回顾一下Java集合框架的接口继承结构:
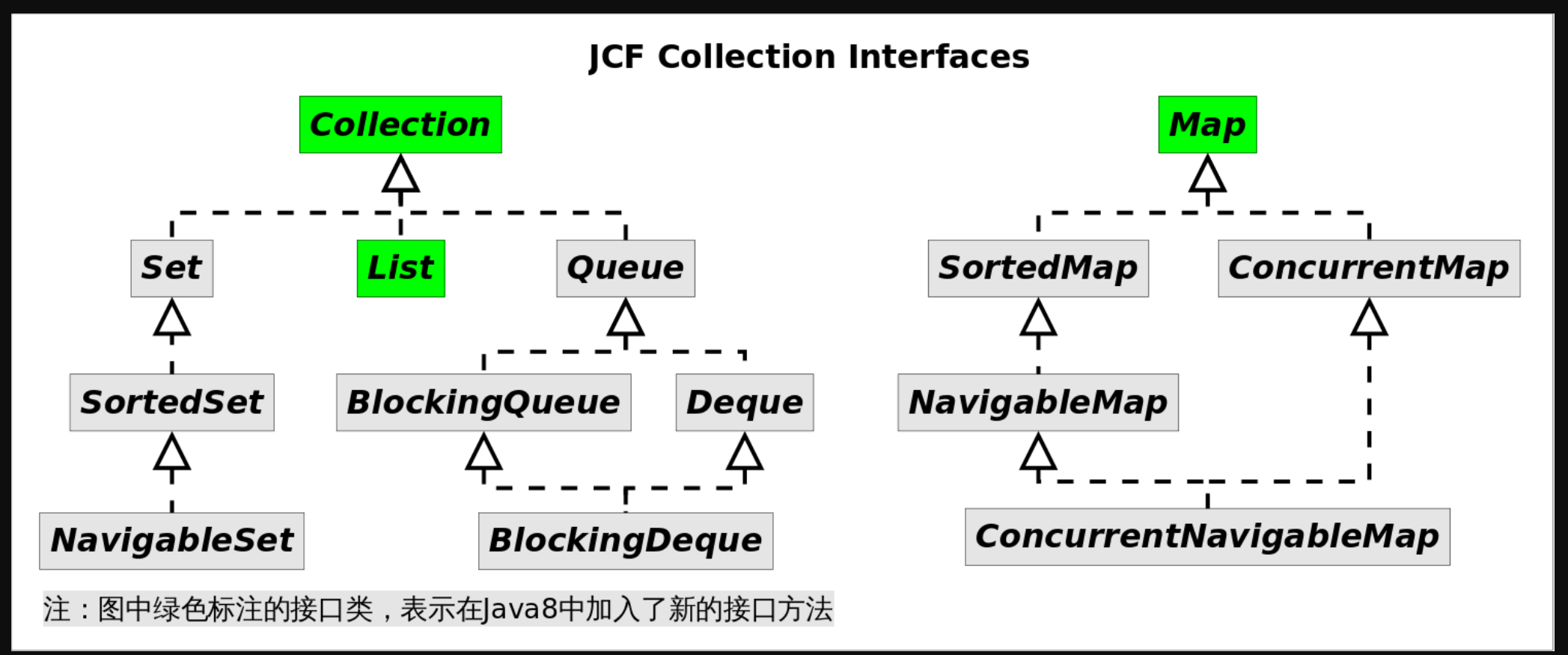
上图中绿色标注的接口类,表示在Java8中加入了新的接口方法,当然由于继承关系,他们相应的子类也都会继承这些新方法。下表详细列举了这些方法。
| 接口名 | Java8新加入的方法 |
|---|---|
| Collection | removeIf() spliterator() stream() parallelStream() forEach() |
| List | replaceAll() sort() |
| Map | getOrDefault() forEach() replaceAll() putIfAbsent() remove() replace() computeIfAbsent() computeIfPresent() compute() merge() |
这些新加入的方法大部分要用到java.util.function包下的接口,这意味着这些方法大部分都跟Lambda表达式相关。我们将逐一学习这些方法。
Collection中的新方法
如上所示,接口Collection和List新加入了一些方法,我们以是List的子类ArrayList为例来说明。了解Java7ArrayList实现原理,将有助于理解下文。
forEach()
该方法的签名为void forEach(Consumer<? super E> action),作用是对容器中的每个元素执行action指定的动作,其中Consumer是个函数接口,里面只有一个待实现方法void accept(T t)(后面我们会看到,这个方法叫什么根本不重要,你甚至不需要记忆它的名字)。
需求:假设有一个字符串列表,需要打印出其中所有长度大于3的字符串.
Java7及以前我们可以用增强的for循环实现:
// 使用曾强for循环迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(String str : list){
if(str.length()>3)
System.out.println(str);
}
现在使用forEach()方法结合匿名内部类,可以这样实现:
// 使用forEach()结合匿名内部类迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach(new Consumer<String>(){
@Override
public void accept(String str){
if(str.length()>3)
System.out.println(str);
}
});
上述代码调用forEach()方法,并使用匿名内部类实现Comsumer接口。到目前为止我们没看到这种设计有什么好处,但是不要忘记Lambda表达式,使用Lambda表达式实现如下:
// 使用forEach()结合Lambda表达式迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach( str -> {
if(str.length()>3)
System.out.println(str);
});
上述代码给forEach()方法传入一个Lambda表达式,我们不需要知道accept()方法,也不需要知道Consumer接口,类型推导帮我们做了一切。
removeIf()
该方法签名为boolean removeIf(Predicate<? super E> filter),作用是删除容器中所有满足filter指定条件的元素,其中Predicate是一个函数接口,里面只有一个待实现方法boolean test(T t),同样的这个方法的名字根本不重要,因为用的时候不需要书写这个名字。
需求:假设有一个字符串列表,需要删除其中所有长度大于3的字符串。
我们知道如果需要在迭代过程冲对容器进行删除操作必须使用迭代器,否则会抛出ConcurrentModificationException,所以上述任务传统的写法是:
// 使用迭代器删除列表元素
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Iterator<String> it = list.iterator();
while(it.hasNext()){
if(it.next().length()>3) // 删除长度大于3的元素
it.remove();
}
现在使用removeIf()方法结合匿名内部类,我们可是这样实现:
// 使用removeIf()结合匿名名内部类实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(new Predicate<String>(){ // 删除长度大于3的元素
@Override
public boolean test(String str){
return str.length()>3;
}
});
上述代码使用removeIf()方法,并使用匿名内部类实现Precicate接口。相信你已经想到用Lambda表达式该怎么写了:
// 使用removeIf()结合Lambda表达式实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(str -> str.length()>3); // 删除长度大于3的元素
使用Lambda表达式不需要记忆Predicate接口名,也不需要记忆test()方法名,只需要知道此处需要一个返回布尔类型的Lambda表达式就行了。
replaceAll()
该方法签名为void replaceAll(UnaryOperator<E> operator),作用是对每个元素执行operator指定的操作,并用操作结果来替换原来的元素。其中UnaryOperator是一个函数接口,里面只有一个待实现函数T apply(T t)。
需求:假设有一个字符串列表,将其中所有长度大于3的元素转换成大写,其余元素不变。
Java7及之前似乎没有优雅的办法:
// 使用下标实现元素替换
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(int i=0; i<list.size(); i++){
String str = list.get(i);
if(str.length()>3)
list.set(i, str.toUpperCase());
}
使用replaceAll()方法结合匿名内部类可以实现如下:
// 使用匿名内部类实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(new UnaryOperator<String>(){
@Override
public String apply(String str){
if(str.length()>3)
return str.toUpperCase();
return str;
}
});
上述代码调用replaceAll()方法,并使用匿名内部类实现UnaryOperator接口。我们知道可以用更为简洁的Lambda表达式实现:
// 使用Lambda表达式实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(str -> {
if(str.length()>3)
return str.toUpperCase();
return str;
});
sort()
该方法定义在List接口中,方法签名为void sort(Comparator<? super E> c),该方法根据c指定的比较规则对容器元素进行排序。Comparator接口我们并不陌生,其中有一个方法int compare(T o1, T o2)需要实现,显然该接口是个函数接口。
需求:假设有一个字符串列表,按照字符串长度增序对元素排序。
由于Java7以及之前sort()方法在Collections工具类中,所以代码要这样写:
// Collections.sort()方法
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Collections.sort(list, new Comparator<String>(){
@Override
public int compare(String str1, String str2){
return str1.length()-str2.length();
}
});
现在可以直接使用List.sort()方法,结合Lambda表达式,可以这样写:
// List.sort()方法结合Lambda表达式
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.sort((str1, str2) -> str1.length()-str2.length());
spliterator()
方法签名为Spliterator<E> spliterator(),该方法返回容器的可拆分迭代器。从名字来看该方法跟iterator()方法有点像,我们知道Iterator是用来迭代容器的,Spliterator也有类似作用,但二者有如下不同:
Spliterator既可以像Iterator那样逐个迭代,也可以批量迭代。批量迭代可以降低迭代的开销。Spliterator是可拆分的,一个Spliterator可以通过调用Spliterator<T> trySplit()方法来尝试分成两个。一个是this,另一个是新返回的那个,这两个迭代器代表的元素没有重叠。
可通过(多次)调用Spliterator.trySplit()方法来分解负载,以便多线程处理。
stream()和parallelStream()
stream()和parallelStream()分别返回该容器的Stream视图表示,不同之处在于parallelStream()返回并行的Stream。Stream是Java函数式编程的核心类,我们会在后面章节中学习。
Map中的新方法
相比Collection,Map中加入了更多的方法,我们以HashMap为例来逐一探秘。了解Java7HashMap实现原理,将有助于理解下文。
forEach()
该方法签名为void forEach(BiConsumer<? super K,? super V> action),作用是对Map中的每个映射执行action指定的操作,其中BiConsumer是一个函数接口,里面有一个待实现方法void accept(T t, U u)。BinConsumer接口名字和accept()方法名字都不重要,请不要记忆他们。
需求:假设有一个数字到对应英文单词的Map,请输出Map中的所有映射关系.
Java7以及之前经典的代码如下:
// Java7以及之前迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
System.out.println(entry.getKey() + "=" + entry.getValue());
}
使用Map.forEach()方法,结合匿名内部类,代码如下:
// 使用forEach()结合匿名内部类迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach(new BiConsumer<Integer, String>(){
@Override
public void accept(Integer k, String v){
System.out.println(k + "=" + v);
}
});
上述代码调用forEach()方法,并使用匿名内部类实现BiConsumer接口。当然,实际场景中没人使用匿名内部类写法,因为有Lambda表达式:
// 使用forEach()结合Lambda表达式迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach((k, v) -> System.out.println(k + "=" + v));
}
getOrDefault()
该方法跟Lambda表达式没关系,但是很有用。方法签名为V getOrDefault(Object key, V defaultValue),作用是按照给定的key查询Map中对应的value,如果没有找到则返回defaultValue。使用该方法程序员可以省去查询指定键值是否存在的麻烦.
需求;假设有一个数字到对应英文单词的Map,输出4对应的英文单词,如果不存在则输出NoValue
// 查询Map中指定的值,不存在时使用默认值
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
// Java7以及之前做法
if(map.containsKey(4)){ // 1
System.out.println(map.get(4));
}else{
System.out.println("NoValue");
}
// Java8使用Map.getOrDefault()
System.out.println(map.getOrDefault(4, "NoValue")); // 2
putIfAbsent()
该方法跟Lambda表达式没关系,但是很有用。方法签名为V putIfAbsent(K key, V value),作用是只有在不存在key值的映射或映射值为null时,才将value指定的值放入到Map中,否则不对Map做更改.该方法将条件判断和赋值合二为一,使用起来更加方便.
remove()
我们都知道Map中有一个remove(Object key)方法,来根据指定key值删除Map中的映射关系;Java8新增了remove(Object key, Object value)方法,只有在当前Map中key正好映射到value时才删除该映射,否则什么也不做.
replace()
在Java7及以前,要想替换Map中的映射关系可通过put(K key, V value)方法实现,该方法总是会用新值替换原来的值.为了更精确的控制替换行为,Java8在Map中加入了两个replace()方法,分别如下:
replace(K key, V value),只有在当前Map中key的映射存在时才用value去替换原来的值,否则什么也不做.replace(K key, V oldValue, V newValue),只有在当前Map中key的映射存在且等于oldValue时才用newValue去替换原来的值,否则什么也不做.
replaceAll()
该方法签名为replaceAll(BiFunction<? super K,? super V,? extends V> function),作用是对Map中的每个映射执行function指定的操作,并用function的执行结果替换原来的value,其中BiFunction是一个函数接口,里面有一个待实现方法R apply(T t, U u).不要被如此多的函数接口吓到,因为使用的时候根本不需要知道他们的名字.
需求:假设有一个数字到对应英文单词的Map,请将原来映射关系中的单词都转换成大写.
Java7以及之前经典的代码如下:
// Java7以及之前替换所有Map中所有映射关系
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
entry.setValue(entry.getValue().toUpperCase());
}
使用replaceAll()方法结合匿名内部类,实现如下:
// 使用replaceAll()结合匿名内部类实现
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll(new BiFunction<Integer, String, String>(){
@Override
public String apply(Integer k, String v){
return v.toUpperCase();
}
});
上述代码调用replaceAll()方法,并使用匿名内部类实现BiFunction接口。更进一步的,使用Lambda表达式实现如下:
// 使用replaceAll()结合Lambda表达式实现
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll((k, v) -> v.toUpperCase());
简洁到让人难以置信.
merge()
该方法签名为merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction),作用是:
- 如果
Map中key对应的映射不存在或者为null,则将value(不能是null)关联到key上; - 否则执行
remappingFunction,如果执行结果非null则用该结果跟key关联,否则在Map中删除key的映射.
参数中BiFunction函数接口前面已经介绍过,里面有一个待实现方法R apply(T t, U u).
merge()方法虽然语义有些复杂,但该方法的用方式很明确,一个比较常见的场景是将新的错误信息拼接到原来的信息上,比如:
map.merge(key, newMsg, (v1, v2) -> v1+v2);
compute()
该方法签名为compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction),作用是把remappingFunction的计算结果关联到key上,如果计算结果为null,则在Map中删除key的映射.
要实现上述merge()方法中错误信息拼接的例子,使用compute()代码如下:
map.compute(key, (k,v) -> v==null ? newMsg : v.concat(newMsg));
computeIfAbsent()
该方法签名为V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction),作用是:只有在当前Map中不存在key值的映射或映射值为null时,才调用mappingFunction,并在mappingFunction执行结果非null时,将结果跟key关联.
Function是一个函数接口,里面有一个待实现方法R apply(T t).
computeIfAbsent()常用来对Map的某个key值建立初始化映射.比如我们要实现一个多值映射,Map的定义可能是Map<K,Set<V>>,要向Map中放入新值,可通过如下代码实现:
Map<Integer, Set<String>> map = new HashMap<>();
// Java7及以前的实现方式
if(map.containsKey(1)){
map.get(1).add("one");
}else{
Set<String> valueSet = new HashSet<String>();
valueSet.add("one");
map.put(1, valueSet);
}
// Java8的实现方式
map.computeIfAbsent(1, v -> new HashSet<String>()).add("yi");
使用computeIfAbsent()将条件判断和添加操作合二为一,使代码更加简洁.
computeIfPresent()
该方法签名为V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction),作用跟computeIfAbsent()相反,即,只有在当前Map中存在key值的映射且非null时,才调用remappingFunction,如果remappingFunction执行结果为null,则删除key的映射,否则使用该结果替换key原来的映射.
这个函数的功能跟如下代码是等效的:
// Java7及以前跟computeIfPresent()等效的代码
if (map.get(key) != null) {
V oldValue = map.get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null)
map.put(key, newValue);
else
map.remove(key);
return newValue;
}
return null;
总结
- Java8为容器新增一些有用的方法,这些方法有些是为完善原有功能,有些是为引入函数式编程,学习和使用这些方法有助于我们写出更加简洁有效的代码.
- 函数接口虽然很多,但绝大多数时候我们根本不需要知道它们的名字,书写Lambda表达式时类型推断帮我们做了一切.