来源: ClickHouse原理解析与应用实践 (2020年出版的一本书)
ClickHouse: Click Stream Data WareHouse
1. 相关名词:
A. BI(商业智能)
B. OLTP 联机事务处理
C. OLAP 联机分析: 多维分析
1. ROLAP (Relational OLAP 关系型OLAP
2. MOLAP (Multidimensional OLAP 多维型OLAP 预先聚合结果,不存储细节
3. HOLAP (Hybrid OLAP 混合架构

D. SIMD (Single Instruction Multiple Data), CPU指令 可实现向量化执行, 单条指令操作多条数据,原理为在CPU寄存器层面实现数据的并行操作
E. Shard 分片
F. Replica 副本
2. ClickHouse 架构概述
A. 列式存储:列式存储在聚合某几列时,只需要扫描相应的列,速度快
B. 数据压缩:同一列的数据 具有相同的数据类型和语义,重复的概率高,压缩率高,ClickHouse 整体压缩比可达8:1,压缩后数据体量小,传输快
C. 向量化执行:数据级并行执行操作。ClickHouse利用SSE4.2 指令集实现
D. 是一种关系模型 支持SQL查询
E. 有多样化的表引擎可选(>20种)
1. 五种数据库引擎:
a. Ordinary 默认 可使用任意类型的表引擎
b. Dictionary 字典引擎
c. Memory 内存引擎 存放临时数据 服务重启会清除
d. Lazy 日志引擎
e. MySQL MySQL引擎 会拉取远端MySQL 的数据
F. 利用多线程: 线层级并行,与向量化执行互补,SIMD 不适用多分枝判断场景
G. 利用分布式: 支持分区(纵向扩展 利用多线程原理);支持分片(横向拓展,利用分布式原理)
H. 多主架构: Multi-Master 集群中每个节点角色对等,客户端访问任意节点都能得到相同的效果,规避了单点故障,系统架构简单
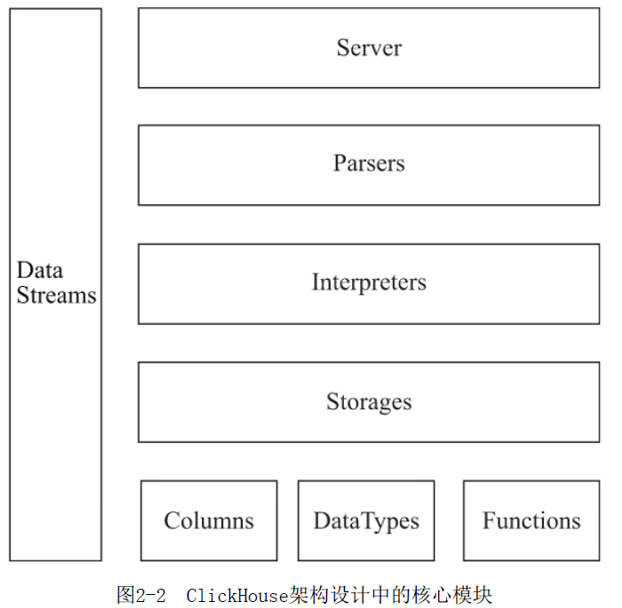
I. 基础概念
1. Column 一列数据: 包含 插入insertFrom;分页cut;过滤cut 方法
2. Field 代表单值 单列中的一行数据
3. DataType 数据类型,负责数据的序列化和反序列化
4. Block: 本质是由(Column, DataType, 列名称)组成,是ClickHouse内部数据操作是面向Block对象的,Column 提供数据读取能力,DataType知道如何正反序列化
5. Block流: IBlockInputStream 负责数据读取和关系运算,IBlockOutputStream 负责将数据输出到下一环节
6. IStorage 接口指代数据表
7. Parser 分析器 负责创建AST 对象(抽象语法树)
8. Interpreter 解释器 负责接收AST 并进一步创建查询的执行管道
9. Functions: 普通函数,包括四则运算 日期转化 IP地址脱敏等。普通函数是无状态函数。 普通函数采用向量化的方式直接作用于一整列数据
10. Aggregate Functions: 聚合函数, 由状态函数。 状态支持序列化和反序列化 可在分布式节点之间进行传输 实现增量计算
11. 集群和副本: ClickHouse 集群由分片组成,分片由副本组成
3. ClickHouse 数据类型
1. 三种基本类型
u 数值类型
l Int8 Int16 Int32 Int64; UInt8 UInt16 UInt32 UInt64;
l Float32 Float64
l Decimal(P,S) :P 总位数 S小数位数
n 不同Decimal做四则运算时 加减法取最大S 乘法取两S之和 除法S1/S2 取被除数S1
u 字符串类型
l String 长度不限
l FixedString(N) 长度为N 不足用null填充
l UUID 常用主键类型 32位 格式为8-4-4-4-12
u 事件类型
l DataTime: 时分秒 支持字符串形式写入
l DateTime64 可记录亚秒
l Date 只精确到天
2. 四种复合类型
u Array 数组 定义时使用array(T) 或 [T]; 可自动推断类型
u Tuple 元组 定义时使用tuple(T) 或 (T) 每个元素可设置不同数据类型
u Enum 枚举类型 定义时使用Enum8 或 Enum16 分别对应 键-值 类型 (String-Int8) 和 (String-Int16); k-v都不能为null ,但key允许是空字符串
u Nested 嵌套类型, 可在数据中嵌套一个表
3. 两种特殊类型
u Nullable 可声明某基础类型为 Nullable表示此字段是可选的 既可以是基础类型 又可以是Null 例如Nullable(Int8)
u Domain
l IPv4 基于UInt32封装 存IPv4地址 需要显示时通过IPv4NumToString 转化成字符串
l IPv6 基于FixedString(16) 封装 存IPv6
4. DDL 数据库定义语言
1. 建立数据库CREATE DATABASE IF NOT EXISTS db_name [ENGINE = engine]
2. 删除数据库 DROP DATABASE [IF EXISTS] db_name
3. 建表方法 3种
u 常规
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
…
) ENGINE = engine
u 复制其他表的结构 tablename2 代表其他表的结构
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name AS [db_name2.] table_name2 [ENGINE = engine]
u 从select子句创建 ,并将select出的数据顺带写入
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ENGINE = engine AS SELECT …
4. 临时表:建表前加TEMPORARY 关键字可建立临时表 生命周期与会话绑定
5. 分区表: 合并树(MergeTree支持分区表) 由PARTITION BY 指定区分键 不同键 存入不同的文件
CREATE TABLE partition_v1 (
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
6. 视图:
u 普通视图:不存数据 仅是一层查询映射
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name AS SELECT ...
u 物化视图: 存数据 ,使用POPULATE 会将源表数据一并导入,不使用则不导入。且物化视图 在原表更新时同步更新,删除时不会同步删除
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT .
7. 移动数据表 可实现重命名 和 移动数据表到不同数据库
RENAME TABLE [db_name11.]tb_name11 TO [db_name12.]tb_name12
8. 清空数据表 TRUNCATE TABLE [IF EXISTS] [db_name.]tb_name
9. 查询分区信息: system系统表查询状态

10. 删除某分区 ALTER TABLE tb_name DROP PARTITION partition_expr
11. 复制分区: ALTER TABLE B REPLACE PARTITION partition_expr FROM A
12. 重置分区某列数据源:ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr
13. DETACH 卸载分区 ATTACH 状态分区; 不删除物理数据 但查不到
14. 分布式DDL 执行: 在执行时加上 ON CLUSTER cluster_name 就会将DDL 语句在cluster_name 集群广播执行
5. 合并树表引擎汇总
1. MergeTree的TTL 和 多路径存储策略
u MergeTree的TTL P234
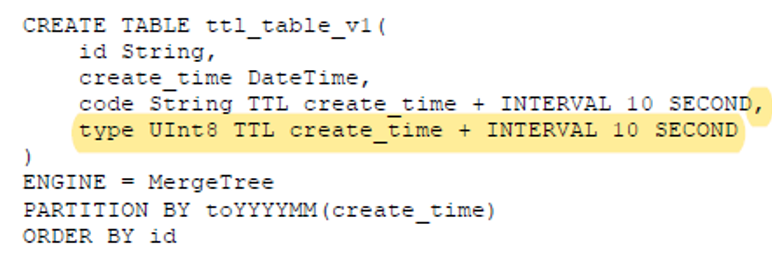
l 列级别TTL :例子 表示type存活时间是create_time+10秒 超过后会清空,取值为该列的默认值,若某列全被清空,则bin文件不保存此列
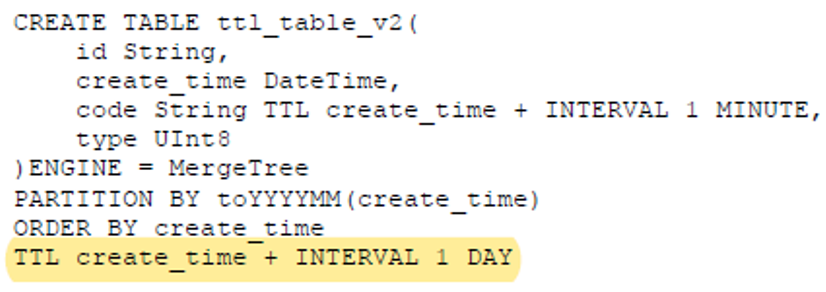
l 表级别TTL:当触发TTL 时 整行数据都会被删除
u MergeTree 多路径存储策略(3种)P238
l 默认策略: 所有分区保存在 config.xml 指定的path中
l JBOD 策略(Just a Bunch Of Disks),轮询写入各个磁盘
l HOT/CLOD:HOT 区域保存数据,分区数据大小累计达到阈值,数据自行引动到CLOD区域。一般HOT为SSD,高性能存储。
2. ReplacingMergeTree: 主键唯一的MergeTree(分区内唯一)
u 形式 ![]()
u ver 选填,填的话是表中的一个字段,此字段作为版本号,发生重复时保留版本号最大的行;不填的话 保留重复数据中的最后一行
u 使用ORDER BY 排序键作为判断重复的唯一主键 而不是 PRIMARY KEY
u 合并分区时 才会触发删除重复(只会删除同一分区的重复行)
3. SummingMergeTree: 预先汇总,终端只关心汇总结果,不关心明细,且汇总条件明确 P250
u 形式![]()
u col 选填,代表要汇总的数值型字段,若不填 则汇总所有非主键类型的字段,其他类型的字段取第一行数据
u ORDER BY 排序键 作为汇总的key,同一分区内的才会被汇总,只有在合并分区时才会触发汇总逻辑
u 支持嵌套结构的汇总, 但列中的嵌套字段必须以Map结尾,默认以嵌套字段的第一个字段作为聚合的Key,除此之外 以Key Id Type结尾的字段会与之形成复合key P253
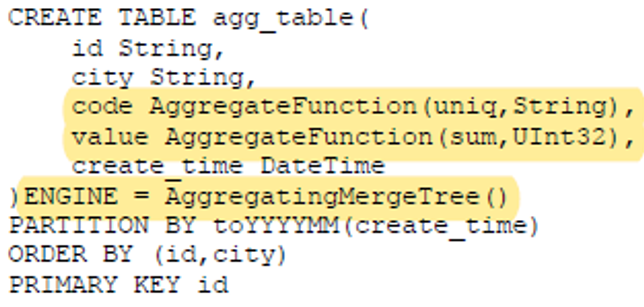
4. AggregatingMergeTree:用特定的聚合函数 提前聚合 如uniq、sum等
u 例子:code使用uniq聚合,value 使用sum聚合
u 插入时 使用 *State函数 使用INSERT SELECT 语法
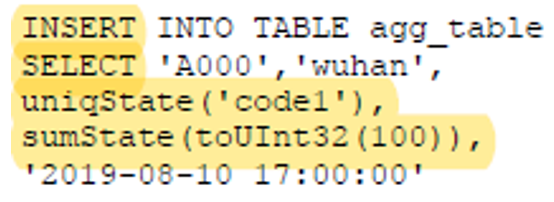
u 查询时 使用*Merge函数

u 一般配合物化视图使用,插入时直接插入原表 不用利用*State函数,查询时要查询物化视图,使用*Merge函数
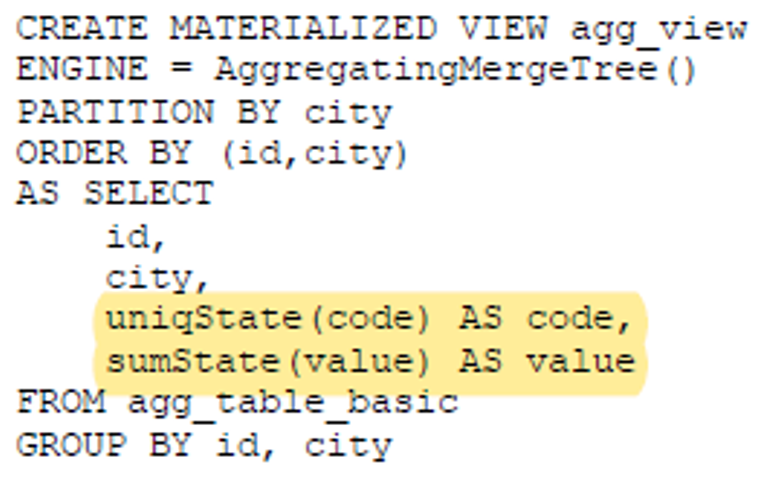
u 使用ORDER BY 作为聚合key,同一分区同一key中的聚合字段会进行合并,非聚合字段使用第一行数据的取值
5. CollapsingMergeTree 折叠合并树(使得合并树支持删除修改)
u 定义一个sign标记位字段,标记为1和-1的一组数据会抵消删除
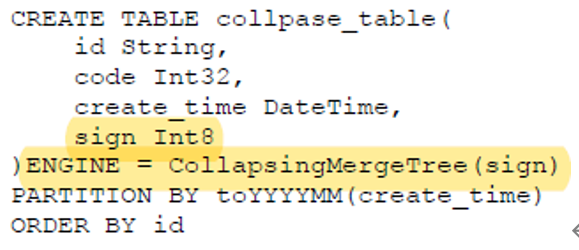
u 合并分支时触发,但要求1和-1的两条数据的相邻的,多线程模式下会出现问题
6. VersionedCollapsingMergeTree
u 除了指定sign,还要指定ver 代表版本号,版本号会作为排序条件自动加到ORDER BY 末端,多线程情况下,无论写入顺序如何 都能以正确的顺序读取并进行折叠
6. 其他类型表引擎
1. 外部存储类型: P275 ClickHouse可对接 HDFS、MySQL、JDBC(可于PostgreSQL SQLite 、H2对接)、Kafka、文件File(TSV,CSV JSON)
2. 内存类型:数据直接放在内存中 有更好的查询性能
u Memory表引擎: 数据不会被压缩 也不会被格式转化 直接保存再内存中,服务重启会全部丢失
u Set表引擎: 数据先写至内存 再同步到磁盘 且去重
u Join 表引擎: 为JOIN查询而生 也是先写到内存 再同步到磁盘
u Buffer 表引擎: 高并发场景下 若写入速度远大于合并速度 可用Buffer缓解此问题,先将内容写到Buffer中,Buffer再在合适的时机写到目标表中 P297
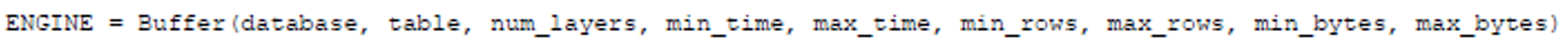
l database,table 目标数据库和目标表;num_layers 写入时线程数(默认16);三处极值的参数,触发条件有二:1、三组极值都满足最小值 2、某组极值满足最大值
3. 日志类型:不支持并发读写,写时不能查。适用于少写多查。
u TinyLog: 日志家族中性能最低的,不支持分区,不支持并行读取,适用于简单场景
u StripeLog: 所有列用一个文件保存,支持并行查询
u Log:数据按列存,便于压缩,支持并行查询,是日志家族中性能最高的
4. 接口类型 : 不存储数据,类似视图
u Merge 合并多个查询的结果集
u Dictionary 让用书通过数据表查询字典 会加载到内存中
u Distribute 作为分布式表的代理,自动开展数据写入分发、查询路由
5. 其他类型
u Live View 类似事件监听器 可将一条SQL的查询结果作为监控目标,当目标变化时 可及时发出相应 P314
u NULL: 与Unix系统的空设备类似,向NULL表写数据 系统会正确返回且忽略数据,发起查询也会返回空表。 使用物化视图若不想保留源表数据,则可将原表引擎设为NULL
u URL: 这个表引擎等价于HTTP客户端,当用SQL进行SELECT查询时,底层会使用GET请求从远程查询数据并返回;当SQL用INSERT 插入时,底层会将其转换成对应的POST请求 P317
7. 数据查询
1. 数据查询性能优化:
u 遵循左大 右小的原则:数据量小的放在右侧,因为JOIN查询时 右边都会全部加载到内存与左表进行比较
u JOIN查询没有缓存支持:即使相同的SQL,每次也会生成全新的执行计划。若大量使用 可考虑上层应用侧缓存 或 JOIN表引擎 来改善性能
u ClickHouse实现的PREWHERE 性能优于WHERE,将optimize_move_to_prewhere 设置为1 ,系统可自动优化SQL语句。PREWHERE原理是先只读取PREWHERE 指定的列字段,用数据过滤条件进行判断,判断后再读取SELECT查找的其他字段。
2. 查询性能分析
u 未提供EXPLAIN功能 但可以通过将其服务日志设置到 DEBUG 或TRACE级别 可变相实现EXPLAIN功能 P362
u Clickhouse-client –h ch5.nauu.com –send_logs_leve=trace<<<”SQL语句”
来源: ClickHouse原理解析与应用实践 (2020年出版的一本书)
ClickHouse: Click Stream Data WareHouse
1. 相关名词:
A. BI(商业智能)
B. OLTP 联机事务处理
C. OLAP 联机分析: 多维分析
1. ROLAP (Relational OLAP 关系型OLAP
2. MOLAP (Multidimensional OLAP 多维型OLAP 预先聚合结果,不存储细节
3. HOLAP (Hybrid OLAP 混合架构
D. SIMD (Single Instruction Multiple Data), CPU指令 可实现向量化执行, 单条指令操作多条数据,原理为在CPU寄存器层面实现数据的并行操作
E. Shard 分片
F. Replica 副本
2. ClickHouse 架构概述
A. 列式存储:列式存储在聚合某几列时,只需要扫描相应的列,速度快
B. 数据压缩:同一列的数据 具有相同的数据类型和语义,重复的概率高,压缩率高,ClickHouse 整体压缩比可达8:1,压缩后数据体量小,传输快
C. 向量化执行:数据级并行执行操作。ClickHouse利用SSE4.2 指令集实现
D. 是一种关系模型 支持SQL查询
E. 有多样化的表引擎可选(>20种)
1. 五种数据库引擎:
a. Ordinary 默认 可使用任意类型的表引擎
b. Dictionary 字典引擎
c. Memory 内存引擎 存放临时数据 服务重启会清除
d. Lazy 日志引擎
e. MySQL MySQL引擎 会拉取远端MySQL 的数据
F. 利用多线程: 线层级并行,与向量化执行互补,SIMD 不适用多分枝判断场景
G. 利用分布式: 支持分区(纵向扩展 利用多线程原理);支持分片(横向拓展,利用分布式原理)
H. 多主架构: Multi-Master 集群中每个节点角色对等,客户端访问任意节点都能得到相同的效果,规避了单点故障,系统架构简单
I. 基础概念
1. Column 一列数据: 包含 插入insertFrom;分页cut;过滤cut 方法
2. Field 代表单值 单列中的一行数据
3. DataType 数据类型,负责数据的序列化和反序列化
4. Block: 本质是由(Column, DataType, 列名称)组成,是ClickHouse内部数据操作是面向Block对象的,Column 提供数据读取能力,DataType知道如何正反序列化
5. Block流: IBlockInputStream 负责数据读取和关系运算,IBlockOutputStream 负责将数据输出到下一环节
6. IStorage 接口指代数据表
7. Parser 分析器 负责创建AST 对象(抽象语法树)
8. Interpreter 解释器 负责接收AST 并进一步创建查询的执行管道
9. Functions: 普通函数,包括四则运算 日期转化 IP地址脱敏等。普通函数是无状态函数。 普通函数采用向量化的方式直接作用于一整列数据
10. Aggregate Functions: 聚合函数, 由状态函数。 状态支持序列化和反序列化 可在分布式节点之间进行传输 实现增量计算
11. 集群和副本: ClickHouse 集群由分片组成,分片由副本组成
3. ClickHouse 数据类型
1. 三种基本类型
u 数值类型
l Int8 Int16 Int32 Int64; UInt8 UInt16 UInt32 UInt64;
l Float32 Float64
l Decimal(P,S) :P 总位数 S小数位数
n 不同Decimal做四则运算时 加减法取最大S 乘法取两S之和 除法S1/S2 取被除数S1
u 字符串类型
l String 长度不限
l FixedString(N) 长度为N 不足用null填充
l UUID 常用主键类型 32位 格式为8-4-4-4-12
u 事件类型
l DataTime: 时分秒 支持字符串形式写入
l DateTime64 可记录亚秒
l Date 只精确到天
2. 四种复合类型
u Array 数组 定义时使用array(T) 或 [T]; 可自动推断类型
u Tuple 元组 定义时使用tuple(T) 或 (T) 每个元素可设置不同数据类型
u Enum 枚举类型 定义时使用Enum8 或 Enum16 分别对应 键-值 类型 (String-Int8) 和 (String-Int16); k-v都不能为null ,但key允许是空字符串
u Nested 嵌套类型, 可在数据中嵌套一个表
3. 两种特殊类型
u Nullable 可声明某基础类型为 Nullable表示此字段是可选的 既可以是基础类型 又可以是Null 例如Nullable(Int8)
u Domain
l IPv4 基于UInt32封装 存IPv4地址 需要显示时通过IPv4NumToString 转化成字符串
l IPv6 基于FixedString(16) 封装 存IPv6
4. DDL 数据库定义语言
1. 建立数据库CREATE DATABASE IF NOT EXISTS db_name [ENGINE = engine]
2. 删除数据库 DROP DATABASE [IF EXISTS] db_name
3. 建表方法 3种
u 常规
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
…
) ENGINE = engine
u 复制其他表的结构 tablename2 代表其他表的结构
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name AS [db_name2.] table_name2 [ENGINE = engine]
u 从select子句创建 ,并将select出的数据顺带写入
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ENGINE = engine AS SELECT …
4. 临时表:建表前加TEMPORARY 关键字可建立临时表 生命周期与会话绑定
5. 分区表: 合并树(MergeTree支持分区表) 由PARTITION BY 指定区分键 不同键 存入不同的文件
CREATE TABLE partition_v1 (
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
6. 视图:
u 普通视图:不存数据 仅是一层查询映射
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name AS SELECT ...
u 物化视图: 存数据 ,使用POPULATE 会将源表数据一并导入,不使用则不导入。且物化视图 在原表更新时同步更新,删除时不会同步删除
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT .
7. 移动数据表 可实现重命名 和 移动数据表到不同数据库
RENAME TABLE [db_name11.]tb_name11 TO [db_name12.]tb_name12
8. 清空数据表 TRUNCATE TABLE [IF EXISTS] [db_name.]tb_name
9. 查询分区信息: system系统表查询状态
10. 删除某分区 ALTER TABLE tb_name DROP PARTITION partition_expr
11. 复制分区: ALTER TABLE B REPLACE PARTITION partition_expr FROM A
12. 重置分区某列数据源:ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr
13. DETACH 卸载分区 ATTACH 状态分区; 不删除物理数据 但查不到
14. 分布式DDL 执行: 在执行时加上 ON CLUSTER cluster_name 就会将DDL 语句在cluster_name 集群广播执行
5. 合并树表引擎汇总
1. MergeTree的TTL 和 多路径存储策略
u MergeTree的TTL P234
l 列级别TTL :例子 表示type存活时间是create_time+10秒 超过后会清空,取值为该列的默认值,若某列全被清空,则bin文件不保存此列
l 表级别TTL:当触发TTL 时 整行数据都会被删除
u MergeTree 多路径存储策略(3种)P238
l 默认策略: 所有分区保存在 config.xml 指定的path中
l JBOD 策略(Just a Bunch Of Disks),轮询写入各个磁盘
l HOT/CLOD:HOT 区域保存数据,分区数据大小累计达到阈值,数据自行引动到CLOD区域。一般HOT为SSD,高性能存储。
2. ReplacingMergeTree: 主键唯一的MergeTree(分区内唯一)
u 形式
u ver 选填,填的话是表中的一个字段,此字段作为版本号,发生重复时保留版本号最大的行;不填的话 保留重复数据中的最后一行
u 使用ORDER BY 排序键作为判断重复的唯一主键 而不是 PRIMARY KEY
u 合并分区时 才会触发删除重复(只会删除同一分区的重复行)
3. SummingMergeTree: 预先汇总,终端只关心汇总结果,不关心明细,且汇总条件明确 P250
u 形式
u col 选填,代表要汇总的数值型字段,若不填 则汇总所有非主键类型的字段,其他类型的字段取第一行数据
u ORDER BY 排序键 作为汇总的key,同一分区内的才会被汇总,只有在合并分区时才会触发汇总逻辑
u 支持嵌套结构的汇总, 但列中的嵌套字段必须以Map结尾,默认以嵌套字段的第一个字段作为聚合的Key,除此之外 以Key Id Type结尾的字段会与之形成复合key P253
4. AggregatingMergeTree:用特定的聚合函数 提前聚合 如uniq、sum等
u 例子:code使用uniq聚合,value 使用sum聚合
u 插入时 使用 *State函数 使用INSERT SELECT 语法
u 查询时 使用*Merge函数
u 一般配合物化视图使用,插入时直接插入原表 不用利用*State函数,查询时要查询物化视图,使用*Merge函数
u 使用ORDER BY 作为聚合key,同一分区同一key中的聚合字段会进行合并,非聚合字段使用第一行数据的取值
5. CollapsingMergeTree 折叠合并树(使得合并树支持删除修改)
u 定义一个sign标记位字段,标记为1和-1的一组数据会抵消删除
u 合并分支时触发,但要求1和-1的两条数据的相邻的,多线程模式下会出现问题
6. VersionedCollapsingMergeTree
u 除了指定sign,还要指定ver 代表版本号,版本号会作为排序条件自动加到ORDER BY 末端,多线程情况下,无论写入顺序如何 都能以正确的顺序读取并进行折叠
6. 其他类型表引擎
1. 外部存储类型: P275 ClickHouse可对接 HDFS、MySQL、JDBC(可于PostgreSQL SQLite 、H2对接)、Kafka、文件File(TSV,CSV JSON)
2. 内存类型:数据直接放在内存中 有更好的查询性能
u Memory表引擎: 数据不会被压缩 也不会被格式转化 直接保存再内存中,服务重启会全部丢失
u Set表引擎: 数据先写至内存 再同步到磁盘 且去重
u Join 表引擎: 为JOIN查询而生 也是先写到内存 再同步到磁盘
u Buffer 表引擎: 高并发场景下 若写入速度远大于合并速度 可用Buffer缓解此问题,先将内容写到Buffer中,Buffer再在合适的时机写到目标表中 P297
l database,table 目标数据库和目标表;num_layers 写入时线程数(默认16);三处极值的参数,触发条件有二:1、三组极值都满足最小值 2、某组极值满足最大值
3. 日志类型:不支持并发读写,写时不能查。适用于少写多查。
u TinyLog: 日志家族中性能最低的,不支持分区,不支持并行读取,适用于简单场景
u StripeLog: 所有列用一个文件保存,支持并行查询
u Log:数据按列存,便于压缩,支持并行查询,是日志家族中性能最高的
4. 接口类型 : 不存储数据,类似视图
u Merge 合并多个查询的结果集
u Dictionary 让用书通过数据表查询字典 会加载到内存中
u Distribute 作为分布式表的代理,自动开展数据写入分发、查询路由
5. 其他类型
u Live View 类似事件监听器 可将一条SQL的查询结果作为监控目标,当目标变化时 可及时发出相应 P314
u NULL: 与Unix系统的空设备类似,向NULL表写数据 系统会正确返回且忽略数据,发起查询也会返回空表。 使用物化视图若不想保留源表数据,则可将原表引擎设为NULL
u URL: 这个表引擎等价于HTTP客户端,当用SQL进行SELECT查询时,底层会使用GET请求从远程查询数据并返回;当SQL用INSERT 插入时,底层会将其转换成对应的POST请求 P317
7. 数据查询
1. 数据查询性能优化:
u 遵循左大 右小的原则:数据量小的放在右侧,因为JOIN查询时 右边都会全部加载到内存与左表进行比较
u JOIN查询没有缓存支持:即使相同的SQL,每次也会生成全新的执行计划。若大量使用 可考虑上层应用侧缓存 或 JOIN表引擎 来改善性能
u ClickHouse实现的PREWHERE 性能优于WHERE,将optimize_move_to_prewhere 设置为1 ,系统可自动优化SQL语句。PREWHERE原理是先只读取PREWHERE 指定的列字段,用数据过滤条件进行判断,判断后再读取SELECT查找的其他字段。
2. 查询性能分析
u 未提供EXPLAIN功能 但可以通过将其服务日志设置到 DEBUG 或TRACE级别 可变相实现EXPLAIN功能 P362
u Clickhouse-client –h ch5.nauu.com –send_logs_leve=trace<<<”SQL语句”
8. f