消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题
实现高性能,高可用,可伸缩和最终一致性架构
使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
消息队列应用场景
以下介绍消息队列在实际应用中常用的使用场景。异步处理,应用解耦,流量削锋和消息通讯四个场景
异步处理
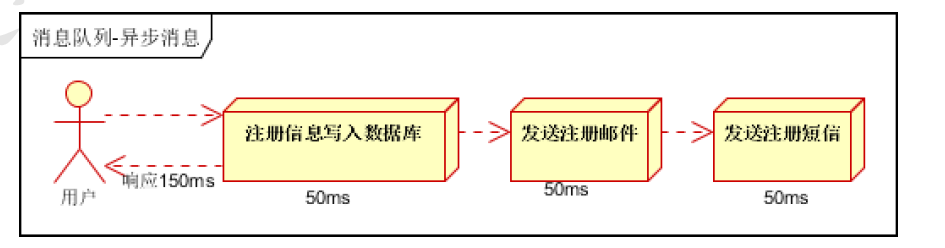
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
(2)并行方式:将注册信息写入数据库成功后,发送注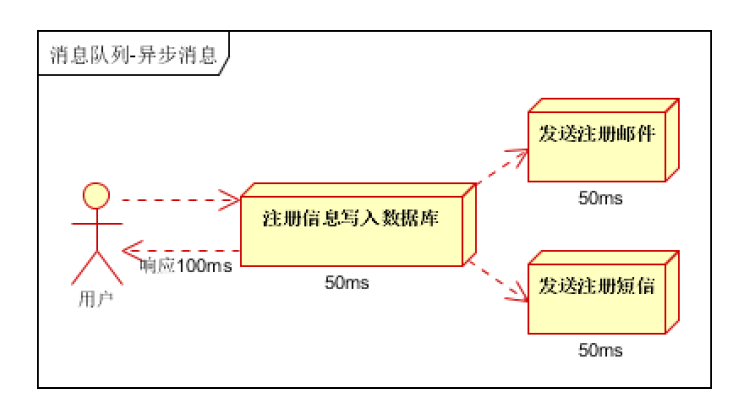
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请 求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100
小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
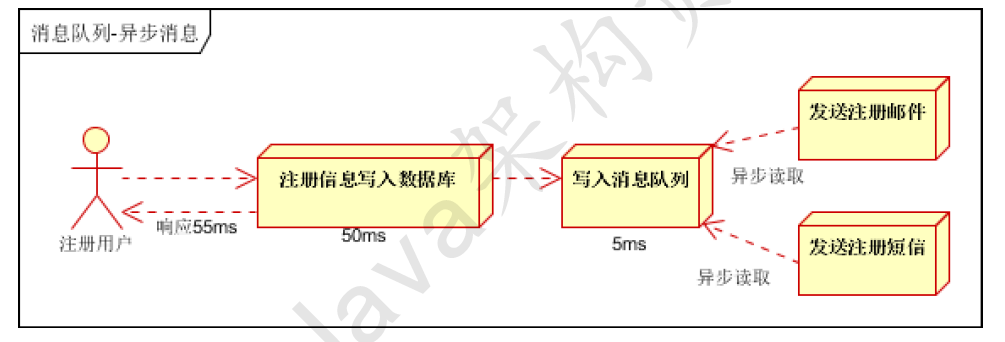
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,
基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍
应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图
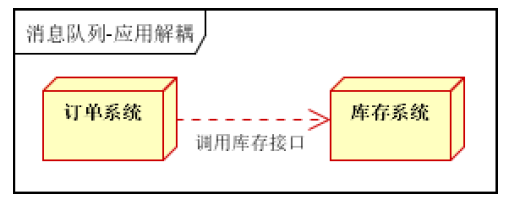
传统模式的缺点:
- 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败
- 订单系统与库存系统耦合
如何解决以上问题呢?引入应用消息队列后的方案,如下图: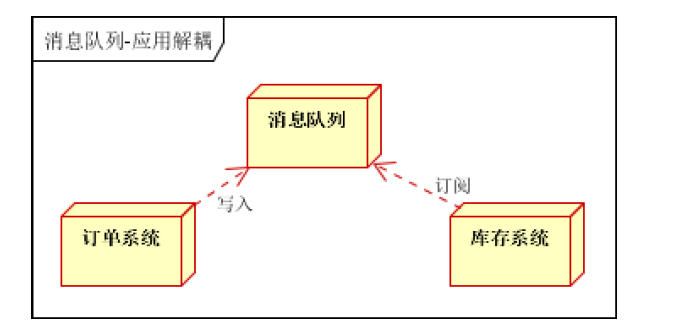
- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关
心其他的后续操作了。实现订单系统与库存系统的应用解耦
流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
- 可以控制活动的人数
- 可以缓解短时间内高流量压垮应用
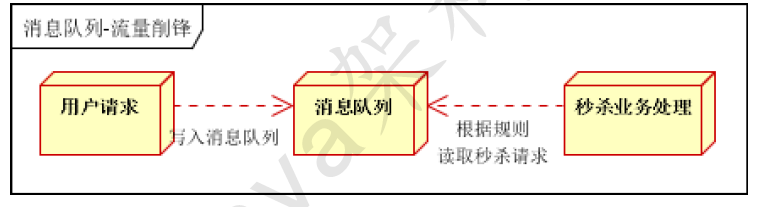
- 用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面
- 秒杀业务根据消息队列中的请求信息,再做后续处理
日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下
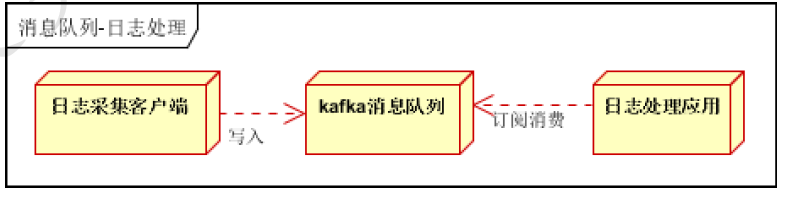
- 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列
- Kafka消息队列,负责日志数据的接收,存储和转发
- 日志处理应用:订阅并消费kafka队列中的日志数据
以下是新浪kafka日志处理应用案例:转自(http://cloud.51cto.com/art/201507/484338.htm)
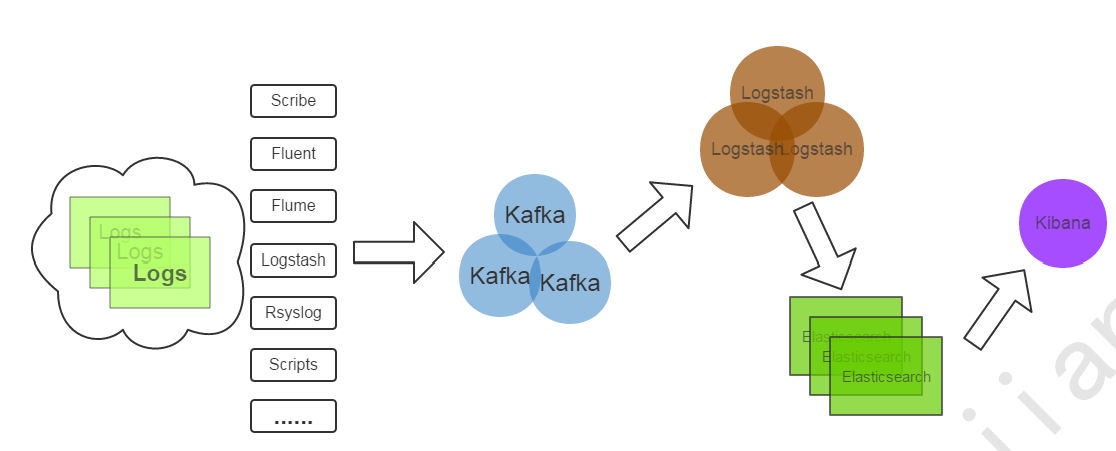
(1)Kafka:接收用户日志的消息队列
(2)Logstash:做日志解析,统一成JSON输出给Elasticsearch
(3)Elasticsearch:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因
消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等
点对点通讯:
客户端A和客户端B使用同一队列,进行消息通讯。
聊天室通讯:
客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
以上实际是消息队列的两种消息模式,点对点或发布订阅模式。模型为示意图,供参考。
消息中间件示例
电商系统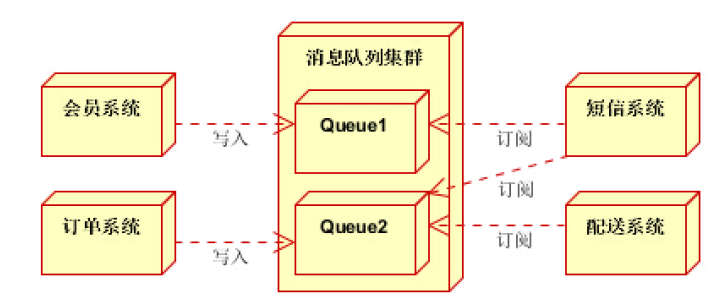
消息队列采用高可用,可持久化的消息中间件。比如Active MQ,Rabbit MQ,Rocket Mq。
(1)应用将主干逻辑处理完成后,写入消息队列。消息发送是否成功可以开启消息的确认模式。(消息队列返回消息接收成功状态后,应用再返回,这样保障消息的完整性)
(2)扩展流程(发短信,配送处理)订阅队列消息。采用推或拉的方式获取消息并处理。
(3)消息将应用解耦的同时,带来了数据一致性问题,可以采用最终一致性方式解决。比如主数据写入数据库,
扩展应用根据消息队列,并结合数据库方式实现基于消息队列的后续处理。
日志收集系统
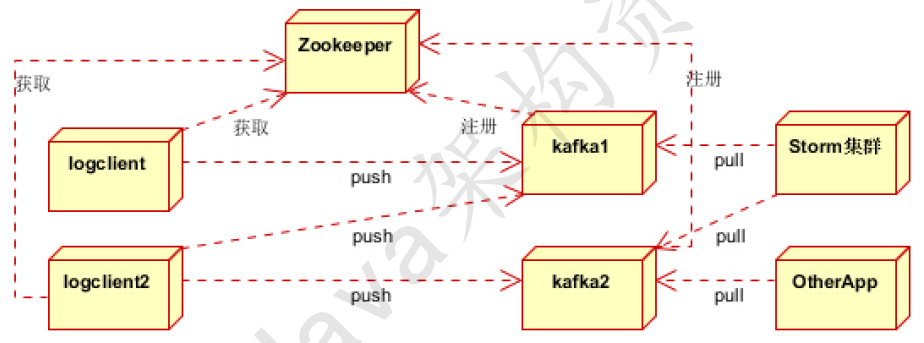
分为Zookeeper注册中心,日志收集客户端,Kafka集群和Storm集群(OtherApp)四部分组成。
- Zookeeper注册中心,提出负载均衡和地址查找服务
- 日志收集客户端,用于采集应用系统的日志,并将数据推送到kafka队列
- Kafka集群:接收,路由,存储,转发等消息处理
Storm集群:与OtherApp处于同一级别,采用拉的方式消费队列中的数据
JMS消息服务
讲消息队列就不得不提JMS 。JMS(JAVA Message Service,java消息服务)API是一个消息服务的标准/规范,允许
应用程序组件基于JavaEE平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及
异步性。
在EJB架构中,有消息bean可以无缝的与JM消息服务集成。在J2EE架构模式中,有消息服务者模式,用于实现消息
与应用直接的解耦。
消息模型
在JMS标准中,有两种消息模型P2P(Point to Point),Publish/Subscribe(Pub/Sub)。
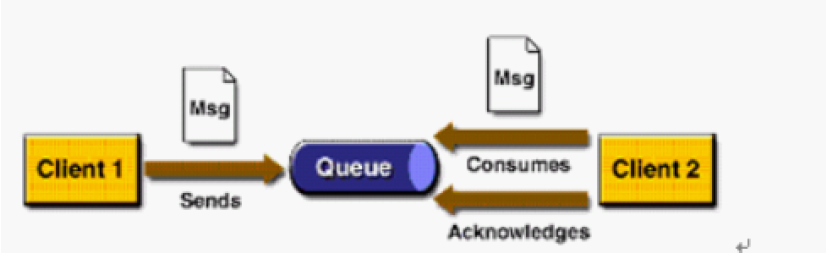
P2P模式包含三个角色:消息队列(Queue),发送者(Sender),接收者(Receiver)。每个消息都被发送到一个特
定的队列,接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时。
P2P的特点
- 每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行,它不会影响到消息被发送到队列
- 接收者在成功接收消息之后需向队列应答成功
如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式。
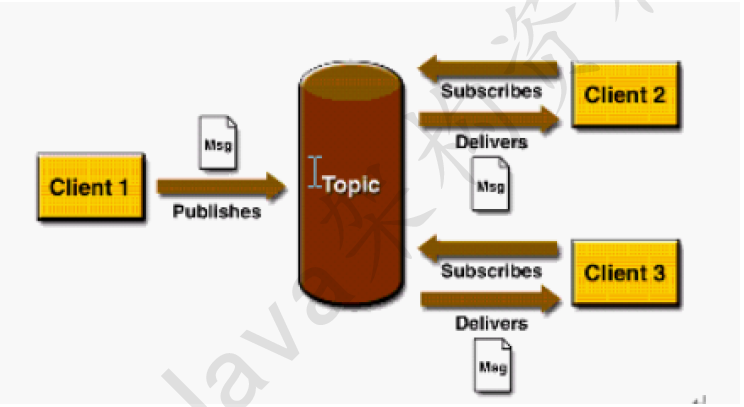
Pub/sub模式包含三个角色主题(Topic),发布者(Publisher),订阅者(Subscriber) 多个发布者将消息发送
到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点
- 每个消息可以有多个消费者
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息
- 为了消费消息,订阅者必须保持运行的状态
为了缓和这样严格的时间相关性,JMS允许订阅者创建一个可持久化的订阅。这样,即使订阅者没有被激活(运
行),它也能接收到发布者的消息。
如果希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以
采用Pub/Sub模型。
消息消费
在JMS中,消息的产生和消费都是异步的。对于消费来说,JMS的消息者可以通过两种方式来消费消息。
(1)同步
订阅者或接收者通过receive方法来接收消息,receive方法在接收到消息之前(或超时之前)将一直阻塞;
(2)异步
订阅者或接收者可以注册为一个消息监听器。当消息到达之后,系统自动调用监听器的onMessage方法。
防止消息丢失
由于网络问题,我们很难保证生产者发送的消息能100%到达消息队列服务器,也就是说有消息丢失的可能性,因
此,生产者就必须具有消息丢失检测和重发机制,也就是我们常说的消息队列的事物机制
不能把可靠性的保证全部交给TCP,TCP只保证了传输层的可靠传输,但是无法保证与应用层的交互是否出错
TCP无法给应用层任何反馈,因此必须在应用层处理差错
同步的事务——停止等待
所谓停止等待协议就是没发送完一组数据后,等待对方确认并且收到确认后,再发送下一组数据。
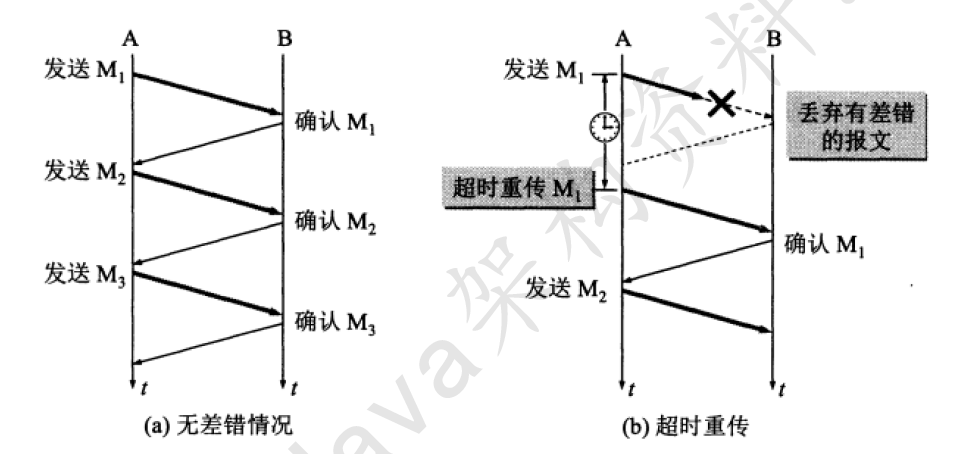
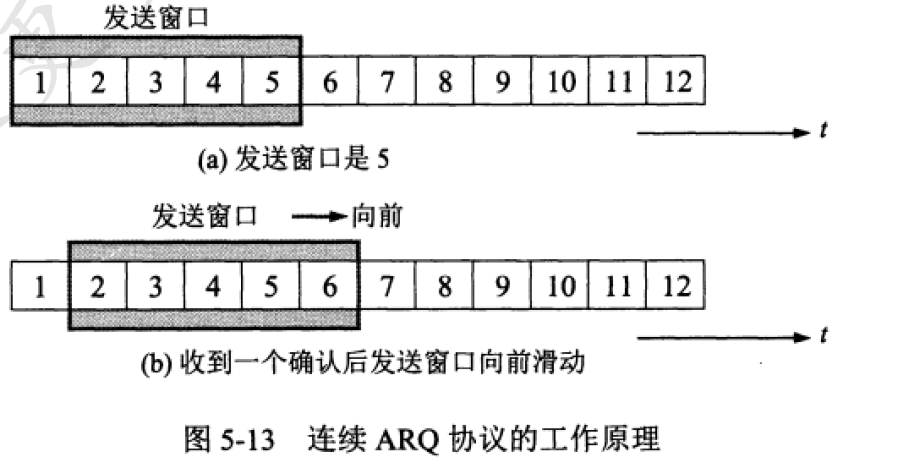
同步的事务——连续ARQ
类似于TCP的滑动窗口模型
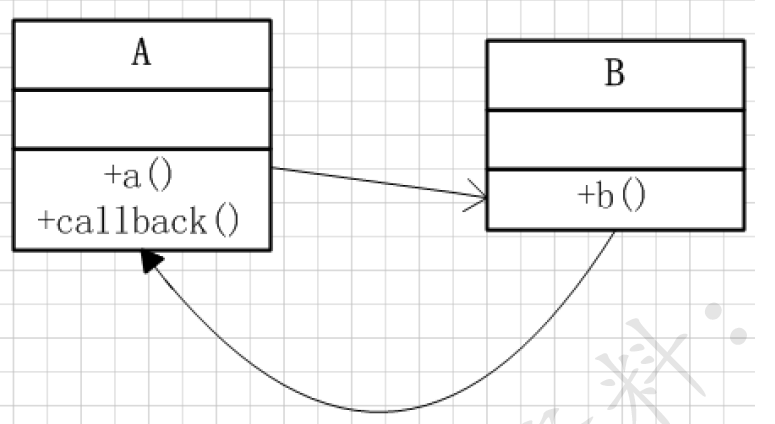
异步的事务——回调机制
生产者在发送消息的时候,注册一个回调函数,这样生产者便不用停下来等待确认了,而是可以一直持续发送消
息,当消息到达消息队列服务器的时候,服务器便会调用生产者注册的回调函数,告知生产者消息发送成功了还是
失败了,进而做进一步的处理,从而提高了并发量。
消息的幂等处理
由于网络原因,生产者可能会重复发送消息,因此消费者方必须做消息的幂等处理,常用的解决方案有:
1. 查询操作:查询一次和查询多次,在数据不变的情况下,查询结果是一样的。select是天然的幂等操作;
2. 删除操作:删除操作也是幂等的,删除一次和多次删除都是把数据删除。(注意可能返回结果不一样,删除的数据不存在,返回0,删除的数据多条,返回结果多个) ;
3. 唯一索引,防止新增脏数据。比如:支付宝的资金账户,支付宝也有用户账户,每个用户只能有一个资金账户,怎么防止给用户创建资金账户多个,那么给资金账户表中的用户ID加唯一索引,所以一个用户新增成功
一个资金账户记录。要点:唯一索引或唯一组合索引来防止新增数据存在脏数据(当表存在唯一索引,并发时新增报错时,再查询一次就可以了,数据应该已经存在了,返回结果即可);
4. token机制,防止页面重复提交。业务要求: 页面的数据只能被点击提交一次;发生原因: 由于重复点击或者网络重发,或者nginx重发等情况会导致数据被重复提交;解决办法: 集群环境采用token加redis(redis单
线程的,处理需要排队);单JVM环境:采用token加redis或token加jvm内存。
处理流程:
1. 数据提交前要向服务的申请token,token放到redis或jvm内存,token有效时间;
2. 提交后后台校验token,同时删除token,生成新的token返回。token特点:要申请,一次有效性,可以限流。注意:redis要用删除操作来判断token,删除成功代表token校验通过,如果用select+delete来校验token,存在并发问题,不建议使用;
5. 悲观锁——获取数据的时候加锁获取。select * from table_xxx where id='xxx' for update; 注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用;
6. 乐观锁——乐观锁只是在更新数据那一刻锁表,其他时间不锁表,所以相对于悲观锁,效率更高。乐观锁的实现方式多种多样可以通过version或者其他状态条件:
1. 通过版本号实现
update table_xxx set name=#name#,version=version+1 where version=#version#如下图(来自网上);
2. 通过条件限制
update table_xxx set avai_amount=avai_amount-#subAmount# where avai_amount-#subAmount# >= 0 要求:quality-#subQuality# >=,这个情景适合不用版本号,只更新是做数据安全校验,适合库存模型,扣份额和回滚份额,性能更高;

7.分布式锁——还是拿插入数据的例子,如果是分布是系统,构建全局唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统(redis或zookeeper),在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,
这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路。要点:某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行
后,释放分布式锁(分布式锁要第三方系统提供);
8.select + insert——并发不高的后台系统,或者一些任务JOB,为了支持幂等,支持重复执行,简单的处理方法是,先查询下一些关键数据,判断是否已经执行过,在进行业务处理,就可以了。注意:核心高并发流程不要用这种方法;
消息的按序处理
同上,消息的按序也不能完全依靠于TCP
在说到消息中间件的时候,我们通常都会谈到一个特性:消息的顺序消费问题。这个问题看起来很简单:
Producer发送消息1, 2, 3。。。 Consumer按1, 2, 3。。。顺序消费。
但实际情况却是:无论RocketMQ,还是Kafka,缺省都不保证消息的严格有序消费!
这个特性看起来很简单,但为什么缺省他们都不保证呢?
“严格的顺序消费”有多么困难
下面就从3个方面来分析一下,对于一个消息中间件来说,”严格的顺序消费”有多么困难,或者说不可能。
发送端
发送端不能异步发送,异步发送在发送失败的情况下,就没办法保证消息顺序。比如你连续发了1,2,3。 过了一会,返回结果1失败,2, 3成功。你把1再重新发送1遍,这个时候顺序就乱掉了。
存储端
对于存储端,要保证消息顺序,会有以下几个问题:
(1)消息不能分区。也就是1个topic,只能有1个队列。在Kafka中,它叫做partition;在RocketMQ中,它叫做queue。 如果你有多个队列,那同1个topic的消息,会分散到多个分区里面,自然不能保证顺序。
(2)即使只有1个队列的情况下,会有第2个问题。该机器挂了之后,能否切换到其他机器?也就是高可用问题。比如你当前的机器挂了,上面还有消息没有消费完。此时切换到其他机器,可用性保证了。但消息顺序就乱掉了。要想保证,一方面要同步复制,不能异步复制;另1方面得保证,切机器之前,挂掉的机器上面,所有消息必须消费完了,不能有残留。很明显,这个很难!!!
接收端
对于接收端,不能并行消费,也即不能开多线程或者多个客户端消费同1个队列。
总结
从上面的分析可以看出,要保证消息的严格有序,有多么困难!
发送端和接收端的问题,还好解决一点,限制异步发送,限制并行消费。但对于存储端,机器挂了之后,切换的问题,就很难解决了。
你切换了,可能消息就会乱;你不切换,那就暂时不可用。这2者之间,就需要权衡了。
业务需要全局有序吗?
通过上面分析可以看出,要保证一个topic内部,消息严格的有序,是很困难的,或者说条件是很苛刻的。
那怎么办呢?我们一定要使出所有力气、用尽所有办法,来保证消息的严格有序吗?
这里就需要从另外一个角度去考虑这个问题:业务角度。正如在下面这篇博客中所说的:
http://www.jianshu.com/p/453c6e7ff81c
实际情况中: (1)不关注顺序的业务大量存在; (2) 队列无序不代表消息无序。