idea 下使用 Scalc 实现 wordCount
- idea -> 进入
plugins安装Scala插件需重新启动 idea - 进入
project structure-> 下载Scala SDK(速度很慢很慢,耐心等待,下载不全会导致后面编译运行程序出bug)如下图点击加号下载即可,我的Scala版本是2.12.16、spark版本是3.0.1,版本依赖可以参考下图,更多信息点击链接查看其实就是maven仓库
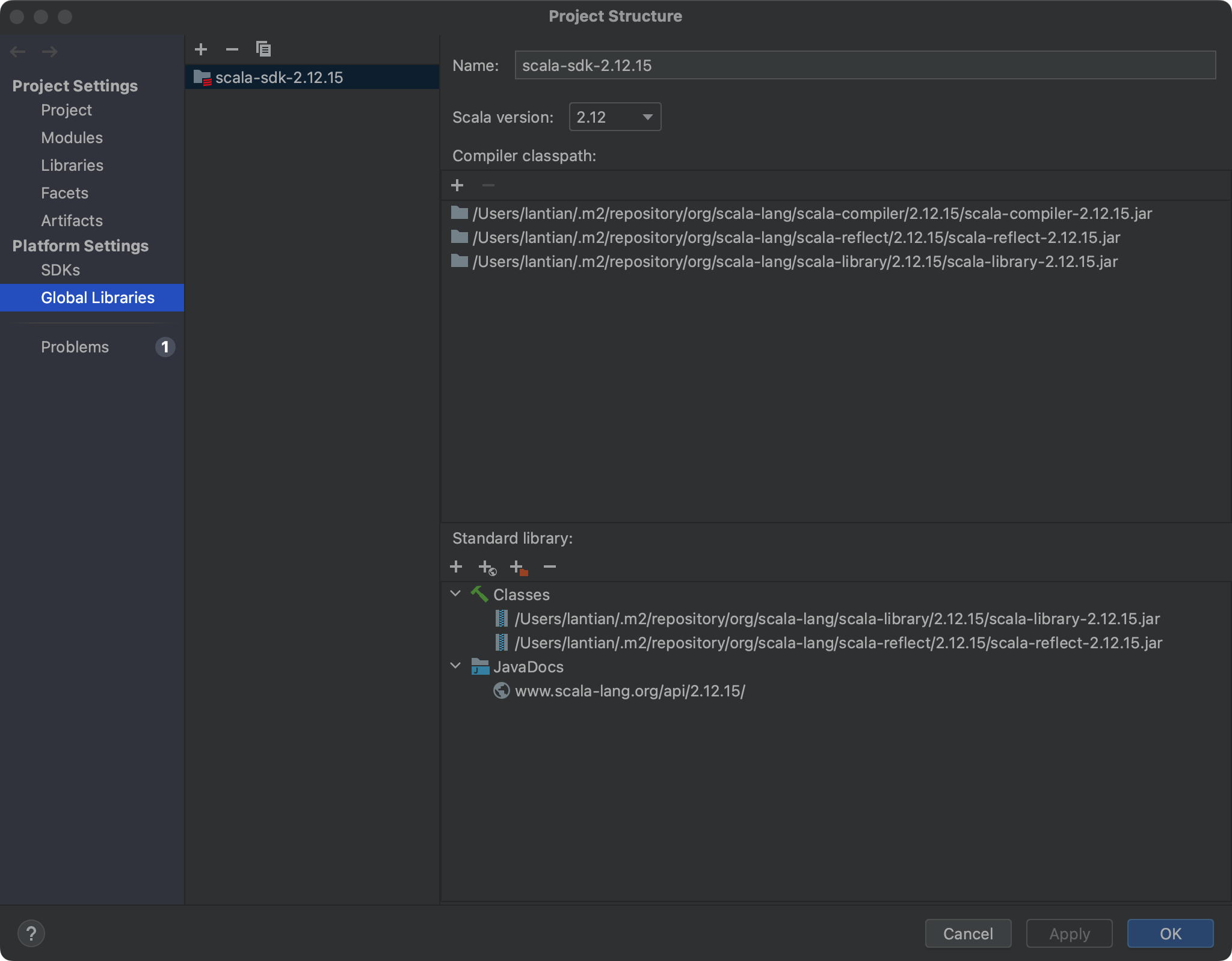
- 安装完这个之后就可以创建 springboot 项目,创建好之后,依旧是打开
project structure选择你刚才下载好的Scala即可 - pom依赖可以参考我的
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>sparkTest</artifactId> <version>1.0-SNAPSHOT</version> <parent> <groupId>org.springframework.boot</groupId> <version>2.2.7.RELEASE</version> <artifactId>spring-boot-starter-parent</artifactId> </parent> <properties> <scala.version>2.12</scala.version> <spark.version>3.0.1</spark.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>2.2.7.RELEASE</version> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> <exclusion> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.10--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <!-- 因为我们需要使用Scala代码,所以我们还需要加入scala-library依赖--> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.12.9</version> </dependency> <!-- https://mvnrepository.com/artifact/com.databricks/spark-xml --> <dependency> <groupId>com.databricks</groupId> <artifactId>spark-xml_2.11</artifactId> <version>0.11.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.6</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> <mainClass>lambert.fun.bean.Main</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>2.10</version> <executions> <execution> <id>copy-dependencies</id> <phase>package</phase> <goals> <goal>copy-dependencies</goal> </goals> <configuration> <outputDirectory>${project.build.directory}/lib</outputDirectory> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <id>scala-compile-first</id> <goals> <goal>compile</goal> </goals> <configuration> <includes> <include>**/*.scala</include> </includes> </configuration> </execution> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <jvmArgs> <!-- 需要的配置 --> <jvmArg>-Xss8m</jvmArg> </jvmArgs> </configuration> </execution> <execution> <id>scala-test-compile</id> <goals> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> <scalaVersion>2.12.11</scalaVersion> </configuration> </plugin> </plugins> </build> </project> - 创建
Scalcopject类,单词统计代码如下package lambert.fun.spark import org.apache.log4j.{Level, Logger} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.SparkSession /** * * * @author Lambert * date 2022-08-17 * explain */ object Test { def main(args: Array[String]): Unit = { // 过滤无效日志 Logger.getLogger("org").setLevel(Level.ERROR) // Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) // val spark = SparkSession // .builder // .appName("calc") // .config("spark.master", "spark://192.168.1.247:7077") // .getOrCreate() // spark.sparkContext.textFile("datas") // spark.sparkContext.setLogLevel("ERROR") // 建立spark 与框架的连接 val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparkConf) // sc.setLogLevel("ERROR") // 执行的操作 // 读取文档 val lines: RDD[String] = sc.textFile("datas") // 以空格分割线 val words: RDD[String] = lines.flatMap(_.split(" ")) // // // 方法1 单纯用scala实现 // // // 将数据进行分组方便统计 // // val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word) // // // 对分组后的数据进行转换 // // val wordToCount = wordGroup.map { // // case (word, list) => { // // (word, list.size) // // } // // } // // 方法2 用spark提供的api reduceByKey实现 val wordToOne = words.map( word => (word, 1) ) var wordToCount = wordToOne.reduceByKey(_ + _) // 将数据转换为集合 val array: Array[(String, Int)] = wordToCount.collect() array.foreach(println) // 关闭连接 sc.stop() } } - 运行程序后输出可能有有很多,这时就需要对
log4j信息进行选择性输出,另外我在pom里已经将Spring Boot 的log给去了log4j.properties创建该文件,创建好后,运行程序可能还会输出一大堆信息,此时需要将该文件拷贝进target目录即可log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to WARN. When running the spark-shell, the # log level for this class is used to overwrite the root logger's log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=WARN # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=WARN log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR- 第二种办法在
application.yml里加入spark: rpc: message: maxSize: 1024 - 第三种办法在
object代码里加入以下代码:// 过滤无效日志,这个是我最终使用的方式 Logger.getLogger("org").setLevel(Level.ERROR) // Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) // 代码里写这个也可以都可以生效 spark.sparkContext.setLogLevel("ERROR")