1、概述
最近邻算法(KNN),是一种基本的分类与回归方法,是数据挖掘技术中最简单的技术之一。
所谓最近邻,就是首先选取一个阈值为K,对在阈值范围内离测试样本最近的点进行投票,票数多的类别就是这个测试样本的类别,这是分类问题。那么回归问题也同理,对在阈值范围内离测试样本最近的点取均值,那么这个值就是这个样本点的预测值。
它没有训练的过程,它的学习阶段仅仅是把样本保存起来,等收到测试集之后再进行处理,属于“懒惰学习”。所以它本质上是衡量样本之间的相似度。
2、KNN 算法三要素
1、K值的选择
- K值的确定与样本最终的判定结果有很大的关系;K 值太小会使得 KNN 算法容易过拟合。反之,太大则会欠拟合。因此,一般采用交叉验证的方式选取 K 值。
2、距离的度量
- 通过什么样的距离理论确定最近邻的样本数据。一般使用欧氏距离(欧几里得距离);
- 闵可夫斯基距离本身不是一种距离,而是一类距离的定义。对于n维空间中的两个点x(x1,x2,…,xn)和y(y1,y2,…,yn),x和y之间的闵可夫斯基距离可以表示为:
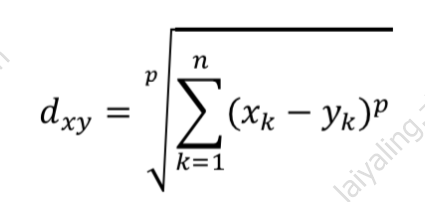 其中,p是一个可变参数:
其中,p是一个可变参数:
当p=1时,被称为曼哈顿距离;
当p=2时,被称为欧氏距离;
当p=infty时,被称为切比雪夫距离。
3、决策规则:以什么样的决策规则来确定最终的输出结果。
- 在分类预测时,一般采用“多数表决法”或“加权多数表决法”;
- 在回归预测时,一般采用“平均值法”或“加权平均值法”,这也是KNN做分类与回归最主要的区别。这里所说的加权一般情况下采用权重和距离成反比的方式来计算。
3、算法步骤
- 算距离:给定测试对象,计算它与训练集中的每个对象的距离
- 找邻居:对训练集的每个对象根据距离排序,选取最近的K个
- 做分类:根据这k个近邻归属的主要类别进行投票,以确定测试对象的分类
4、代码示例
# -*- coding: utf-8 -*-
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 导入knn算法
from sklearn import neighbors
# 加载数据
iris = load_iris()
# 提取数据
trainX = iris.data
trainY = iris.target
# 建立模型
clf = neighbors.KNeighborsClassifier(n_neighbors=6,
weights='uniform', algorithm='auto', metric='minkowski', metric_params=None, n_jobs=1)
'''
@param n_neighbors: 指定kNN的k值
@param weights:
'uniform': 本节点的所有邻居节点的投票权重都相等
'distance': 本节点的所有邻居节点的投票权重与距离成反比
@param algorithm:
'ball_tree': BallTree算法
'kd_tree': kd树算法
'brute': 暴力搜索算法
'auto': 自动决定适合的算法
@param leaf_size: 指定ball_tree或kd_tree的叶节点规模。他影响树的构建和查询速度
@param p: p=1:曼哈顿距离; p=2:欧式距离
@param metric: 指定距离度量,默认为'minkowski'距离
@param n_jobs: 任务并行时指定使用的CPU数,-1表示使用所有可用的CPU
@method fit(X,y): 训练模型
@method predict(X): 预测
@method score(X,y): 计算在(X,y)上的预测的准确率
@method predict_proba(X): 返回X预测为各类别的概率
@method kneighbors(X, n_neighbors, return_distance): 返回样本点的k近邻点。如果return_distance=True,则也会返回这些点的距离
@method kneighbors_graph(X, n_neighbors, mode): 返回样本点的连接图
'''
# 训练模型
clf.fit(trainX, trainY)
# 打印准确率
print("训练准确率:" + str(clf.score(trainX, trainY)))
print("测试准确率:" + str(clf.score(trainX, trainY)))
训练准确率:0.9733333333333334
测试准确率:0.9733333333333334
4、算法优缺点
1、优点
- 简单,易于理解,易于实现,无需估计参数,无需训练
- 适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
2、缺点
- 懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
- 可解释性较差,无法给出决策树那样的规则。