Elasticsearch使用一种叫做倒排索引(inverted index)的结构来做快速的全文搜索。与正向索引不同,倒排索引是面向词(Term)而不是面向文档的,建立的是词(Term)和文档(Document)之间的映射关系。
举个例子,传统的文档和词条之间的关系如图,如果通过关键词去搜索文档,则要遍历所有的文档再找出相关的结果,运算量非常大。
而在倒排索引中,文档内容会被分解成一个个分词(Term),每个分词在列表中是唯一的,记录着词条出现的次数,以及包含词条的文档以及位置。简化版的倒排索引如图:

可以看到,倒排索引是per field的,一个字段由一个自己的倒排索引。每一个分词叫做 term,而Posting list就是一个int的数组,存储了所有符合某个term的文档id。那么什么是term dictionary 和 term index?
假设我们有很多个term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的term一定很慢,因为term没有排序,需要全部过滤一遍才能找出特定的term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的term。这个就是 term dictionary。有了term dictionary之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次random access大概需要10ms的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个term dictionary本身又太大了,无法完整地放到内存里。于是就有了term index。term index有点像一本字典的大的章节表。比如:
A开头的term ……………. Xxx页
C开头的term ……………. Xxx页
E开头的term ……………. Xxx页
如果所有的term都是英文字符的话,可能这个term index就真的是26个英文字符表构成的了。但是实际的情况是,term未必都是英文字符,term可以是任意的byte数组。而且26个英文字符也未必是每一个字符都有均等的term,比如x字符开头的term可能一个都没有,而s开头的term又特别多。实际的term index是一棵trie 树:
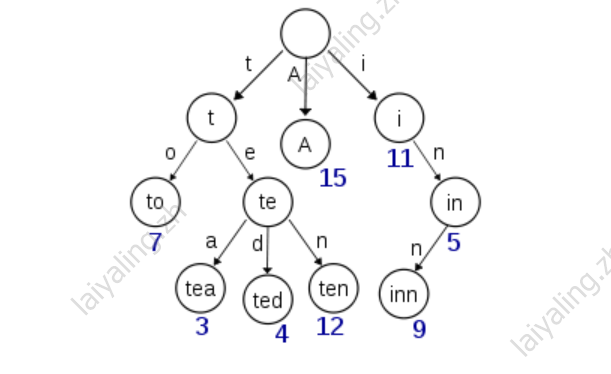
例子是一个包含 "A", "to", "tea", "ted", "ten", "i", "in", 和 "inn" 的 trie 树。这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有term的尺寸的几十分之一,使得用内存缓存整个term index变成可能。整体上来说就是这样的效果。

额外值得一提的两点是:term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary可以比b-tree更节约磁盘空间。