这本书适合看过官方文档或其他基础教程的人,讲的多是些具体网络的实现
一、tensorflow基础

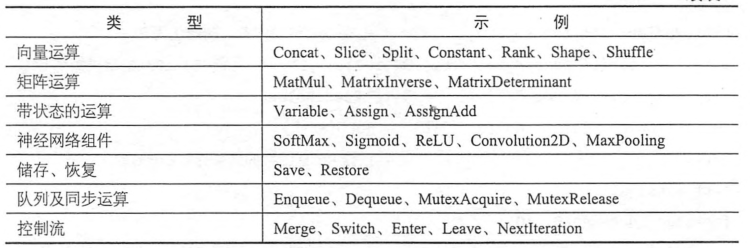
tensorflow的操作流程
1. 自定义节点,自定义有向图,一般是把整个流程图都定义完整

每个需要看输出结果的节点都必须有显式地进行定义,形式如 node=...... 比如2,3,4,5,6行等
对于不需要进行输出的节点可以不进行显示定义,比如Add
2. 通过Session的run方法进行执行计算图
每次run都是指定一个节点计算,比如说: tf.Session.run(ReLU)
我们要计算ReLU的话,同时它依赖的一些节点都会按顺序进行计算,比如说Add,MatMul,
同时我们看到还需要有输入x, 那么我们需要把x作为参数输入到run函数:
tf.Session.run(ReLU,feed_dict={x:input})
其中x是定义的placeholder节点,作为外部输入的节点类型都为tf.placeholder
input是实际的数据(矩阵或者列表)
W,b是定义的变量节点 tf.Variable, 注意V是大写
3. 总结
- 如果创建图之后发现图不够完整还需要添加边或者节点,可以通过Session的Extend方法添加新的节点或者边
- Session的run方法执行计算图时,用户需要给出需要计算的结点,也就是你所想要看到的结果,同时还要提供输入数据,Tensorflow就会自动寻找所有需要计算的节点并按依赖顺序执行它们。通常来说,都是创建一次计算图,然后反复地执行整个计算图或是其中的一部分子图
- 计算图会被执行多次,但是数据(tensor)不会被持续保留,只是在计算图中过一遍,也就是为什么取名叫tensorflow了,数据流过无痕
- 比如说你计算ReLU节点的时候会计算Matmul结点,但是数据不会保留,则是只会输入ReLU结果,所以当你还要看Matmul结果时,你需要重新计算Matmul节点
- 上面所说的是计算的中间结果不会保存,但是Variable作为一种特殊的运算操作,它可以将一些需要保留的tensor存储在内存或显存中,比如神经网络模型中的系数。每一次执行计算图后,Variable中的数据tensor会被保存,同时在计算过程中这些tensor也可以被更新,比如神经网络的每一次mini-batch训练时,神经网络的系数将会被更新并保存
Tensorflow的实现原理(设备管理)
client客户端, 通过Session的接口与master及多个worker相连。其中每一个worker与多个硬件设备相连(CPU/GPU),并负责管理这些硬件
master则负责指导所有worker按流程执行计算图
Tensorflow有单机模式和分布式模式两种实现:
- 单机模式:client,master,worker全部在一台机器上的同一个进程中
- 分布式模式:允许client,master,worker在不同机器的不同进程中,同时由集群调度系统统一管理各项任务
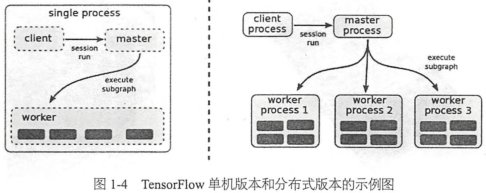
Tensorflow中每一个worker可以管理多个设备,每一个设备的name包含硬件类别、编号、任务号(单机版本中没有),示例如下:
单机模式:/job:localhost/device:cpu:0
分布式模式:/job:worker/task:17/device:gpu:3
在只有一个硬件设备的情况下,计算图会按依赖关系被顺序执行。当一个节点的所有上游依赖都被执行完时(依赖数为0),这个节点就会被加入ready queue以等待执行。同时,它下游所有节点的依赖数减1,实际上这就是标准的计算拓扑序的方式。当有多个设备时,情况就比较复杂了,难点有二:
- 每一个节点该让什么硬件设备执行: tensorflow设计了一套为节点分配设备的策略,有相应的代价模型,会选择一个综合实践最短的设备作为节点的运算设备。以后还会改进
- 如何管理节点间的数据通信:把数据通信的问题转变为发送节点和接收节点的实现问题,用户不需要为不同的硬件环境实现通信方法
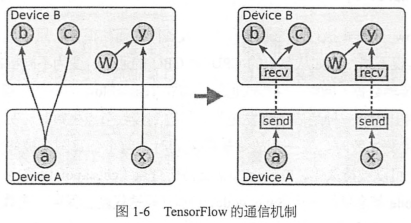
Tensorflow分布式执行时的通信和单机设备间的通信很像,只不过是对发送节点和接收节点的实现不同:比如从单机的CPU到GPU的通信,变为不同机器之间使用TCP或者RDMA传输数据。
Tensorflow扩展功能
tensorflow自动求导
如下图,当tensorflow计算一个tensor C关于tensor I的梯度时,会先寻找从I到C的正向路径,然后从C回溯到I,对这条回溯路径上的每一个节点增加一个对应求解梯度的节点,并根据链式法则计算总的梯度,这就是反向传播算法。这些新增的节点会计算梯度函数比如[db,dW,dx] = tf.gradients(C,[b,W,x])
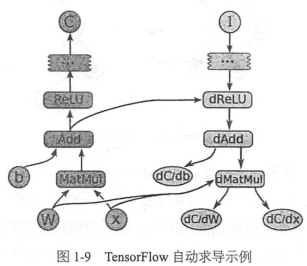
问题:当计算反向传播时,可能需要用到前面图开头的一些tensor,然而这些中间结果tensorflow不会保存,保存tensor会占用太多内存或显存,所以一般不进行保存而选择重新计算,tensorflow仍在持续改进这些问题
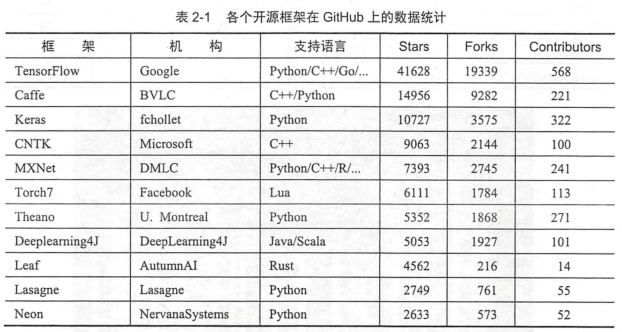
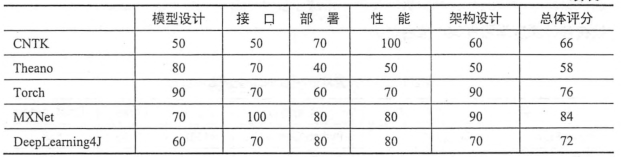
二、Tensorflow和其他深度学习框架的对比
tensorflow优点
设计神经网络结构的代码的简洁度
分布式深度学习算法的执行效率
部署的便利性

Caffe
caffe优点:
- 容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络
- 训练速度快,能够训练state-of-the-art 的模型和大规模的数据
- 组件模块化,可以方便地拓展到新的模型和学习任务上
- 拥有大量的训练好的经典模型,收藏在 Model Zoo
caffe缺点:
- 实现新layer时,需要将正向和反向两种计算过程的函数都实现,这部分计算需要用户自己写C++或CUDA(当需要运行在GPU上)代码,对普通用户来说非常难上手
- Caffe最初设计时的目标只针对图像,没有考虑文本语音等时间序列数据,所以caffe对CNN支持非常好, 但是对RNN支持不充分
- caffe的配置文件不能用编程的方式调整超参,不方便进行交叉验证,超参数的Grid Search等
Theano
theano优点:
- 集成Numpy,可以直接使用Numpy的ndarray,API接口学习成本低
- 计算稳定性好,比如可以精准地计算输出值很小的函数(像log(1+x))
- 动态地生成C或者CUDA代码,用以编译成高效的机器代码
- theano自动求导
- theano派生出了大量基于它的深度学习库,比如Keras,Lasagne
- Keras比较适合在探索阶段快速地尝试各种网络结构,组件都是可插拔的模块,只需要将一个个组件(比如卷积层、激活函数等)连接起来,但是设计新模块或者新的Layer就不太方便
- 学术界喜爱的Lasagne,对神经网络内的每一层的定义都非常严谨
theano缺点:
- 更多作为一个研究工具而不是产品
- 没有底层C++接口,所以模型部署非常不方便,依赖于各种python库,不支持各种移动设备,所以几乎没有在工业生产环境的应用
- Theano在调试时输出的错误信息非常难看懂,debug很痛苦
Torch
用lua语言编程
MXNet
- 各个框架中率先支持多GPU和分布式的
- MXNet的核心是一个动态的依赖调度器,支持自动将计算任务并行化到多个GPU或分布式集群
- 支持非常多的语言封装
CNTK
- 在语音识别领域中使用广泛
- 支持自动求解梯度