python爬虫的简单实现
开发环境配置
python环境的安装
python环境使用的是3.0以上版本
为了便于安装这里使用的是anaconda
下载链接是anaconda
选择下载64位即可

编辑器的安装
这里使用pycharm作为python开发的编辑器,下载网址 pycharm
下载Community社区版即可
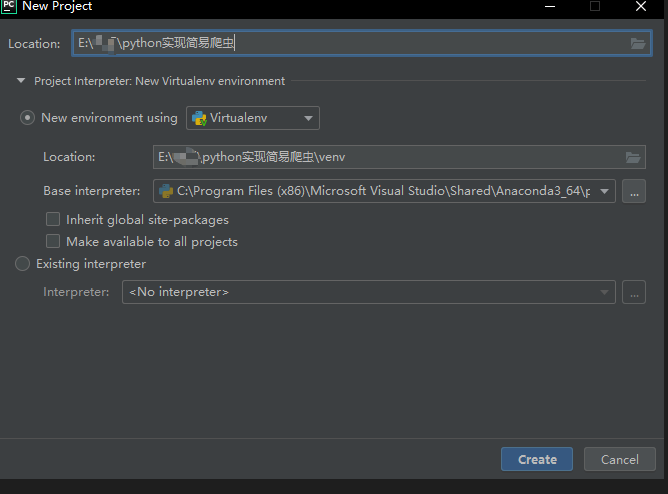
在打开pycharm创建新项目的时候如下图所示,那么就代表了环境已经安装好了
爬虫的实现
包的安装
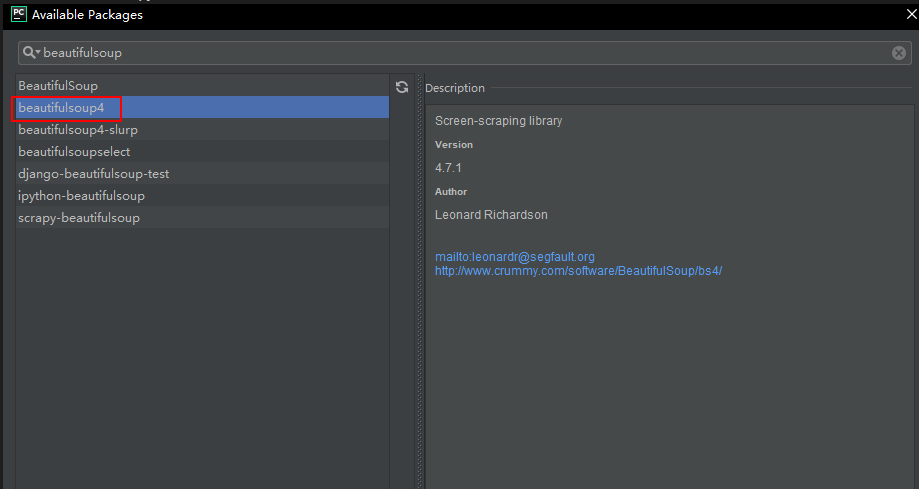
我们这里使用的爬虫插件是beautifulsoup不属于python的基础库,所以我们需要另行添加插件,在pycharm添加插件也是非常简单的,只需要在file->settings->project->project interpreter添加对应的插件即可

点击+号即可选择需要的python包进行安装
简单爬虫的初步实现
接下来就要开始真正的写爬虫了
#首先需要引入包 from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("https://www.cnblogs.com/ladyzhu/p/9617567.html")#括号内的是需要爬取的网址地址 bsObj = BeautifulSoup(html.read()) print(bsObj.title)
将数据写入到数据库
简单的数据清洗
前面我们已经爬取到到了一个简单的网页的信息,但是这些信息是杂乱无章的,接下我们已爬取研招网的院校库为例,爬取每个院校的校名、所在地、院校隶属,学习一下如何进行一个简单的数据处理与爬取。
我们可以看到整个界面是十分复杂的,但是我们可以进行一个分析,我们所需要的数据仅仅是最下面的表格内的数据
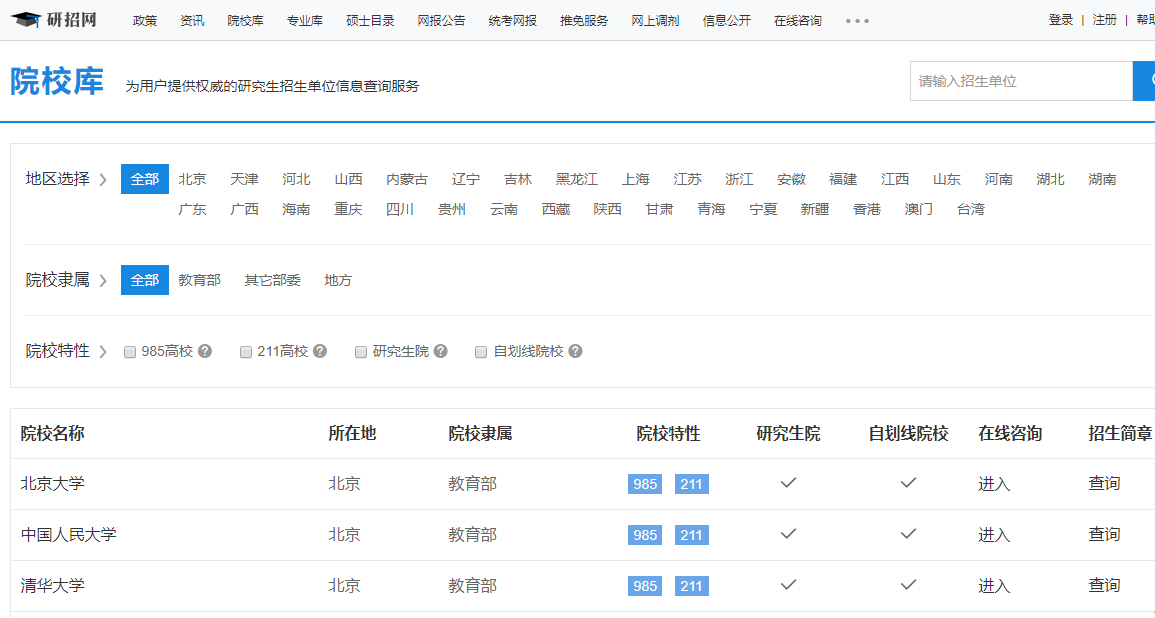
通过查看网页源码可以发现,所有的院校信息确实是保存在下面的一个table之中的
<table class="ch-table"> <thead> <tr> <th>院校名称</th> <th width="100">所在地</th> <th width="150">院校隶属</th> <th width="100" class="ch-table-center">院校特性</th> <th width="100" class="ch-table-center">研究生院</th> <th width="100" class="ch-table-center">自划线院校</th> <th width="90">在线咨询</th> <th width="90">招生简章</th> </tr> </thead> <tbody> <tr> <td> <a href="/sch/schoolInfo--schId-367878.dhtml" target="_blank">北京大学</a> </td> <td>北京</td> <td>教育部</td> <td class="ch-table-center"> <span class="ch-table-tag">985</span> <span class="ch-table-tag">211</span> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td> <a href="/zxdy/forum--type-sch,forumid-455559,method-listDefault,start-0,year-2014.dhtml"target="_blank">进入</a> </td> <td class="text_center"> <a href="/sch/listZszc--schId-367878,categoryId-10460768,mindex-13,start-0.dhtml" target="_blank">查询</a> </td> </tr> <tr> <td> <a href="/sch/schoolInfo--schId-367879.dhtml" target="_blank">中国人民大学</a> </td> <td>北京</td> <td>教育部</td> <td class="ch-table-center"> <span class="ch-table-tag">985</span> <span class="ch-table-tag">211</span> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td> <a href="/zxdy/forum--type-sch,forumid-441209,method-listDefault,start-0,year-2014.dhtml" target="_blank">进入</a> </td> <a href="/sch/listZszc--schId-367879,categoryId-10460770,mindex-13,start-0.dhtml" target="_blank">查询</a> </td> </tr> <tr> <td> <a href="/sch/schoolInfo--schId-367880.dhtml" target="_blank"> 清华大学 </a> </td> <td>北京</td> <td>教育部</td> <td class="ch-table-center"> <span class="ch-table-tag">985</span> <span class="ch-table-tag">211</span> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td> <a href="/zxdy/forum--type-sch,forumid-441314,method-listDefault,start-0,year-2014.dhtml" target="_blank">进入</a> </td> <td class="text_center"> <a href="/sch/listZszc--schId-367880,categoryId-10460772,mindex-13,start-0.dhtml" target="_blank">查询</a> </td> </tr> <tr> <td> <a href="/sch/schoolInfo--schId-367881.dhtml" target="_blank"> 北京交通大学 </a> </td> <td>北京</td> <td>教育部</td> <td class="ch-table-center"> <span class="ch-table-tag ch-table-tag-empty"></span> <span class="ch-table-tag">211</span> </td> <td class="ch-table-center"> <i class="iconfont ch-table-tick">�</i> </td> <td class="ch-table-center"> </td> <td> <a href="/zxdy/forum--type-sch,forumid-455567,method-listDefault,start-0,year-2014.dhtml" target="_blank">进入</a> </td> <td class="text_center"> <a href="/sch/listZszc--schId-367881,categoryId-10460774,mindex-13,start-0.dhtml" target="_blank">查询</a> </td> </tr> <tr> <td> <a href="/sch/schoolInfo--schId-367882.dhtml" target="_blank"> 北京工业大学 </a> </td> <td>北京</td> <td>北京市</td> <td class="ch-table-center"> <span class="ch-table-tag ch-table-tag-empty"></span> <span class="ch-table-tag">211</span> </td> <td class="ch-table-center"> </td> <td class="ch-table-center"> </td> <td> <a href="/zxdy/forum--type-sch,forumid-441418,method-listDefault,start-0,year-2014.dhtml" target="_blank">进入</a> </td> <td class="text_center"> <a href="/sch/listZszc--schId-367882,categoryId-10460776,mindex-13,start-0.dhtml" target="_blank">查询</a> </td> </tr> <tr> <td> <a href="/sch/schoolInfo--schId-367883.dhtml" target="_blank">北京航空航天大学 </a> </td> <td>北京</td> <td>工业与信息化部</td> <td class="ch-table-center"> <span class="ch-table-tag">985</span> <span class="ch-table-tag">211</span> </td> </tbody> </table>
我们可以发现数据是有规律的,每个tr的首个td是学校的名称,第二个td是院校所在地,第三个td是院校的隶属,我们需要的信息都有了,应该如何对这些复杂的信息进行一个简单的清洗呢?
1 #爬取院校信息方法 2 from urllib.request import urlopen 3 import pymysql 4 from urllib.error import HTTPError,URLError 5 from bs4 import BeautifulSoup 6 import re 7 8 #爬取院校信息方法 9 def findSchoolInfo(url): 10 try: 11 html = urlopen(url) 12 except HTTPError as e: 13 return None 14 try: 15 bsObj = BeautifulSoup(html.read(),'lxml') 16 shcoolInfo = bsObj.findAll("table",{"class":"ch-table"}) 17 except AttributeError as e: 18 return None 19 return shcoolInfo 20 21 #处理信息为需要的信息 22 def handleSchoolInfo(info): 23 if info == None: 24 print("没有院校信息") 25 else: 26 school_list = [] 27 for item in info: 28 list = item.findAll("tr") 29 for x in list: 30 school = x.findAll("td") 31 if len(school) 32 school_list.append(school[0:3]) 33 else: 34 continue 35 for item in school_list: 36 school_name = item[0].get_text().strip() 37 school_shengfen = item[1].get_text() 38 shcool_belong = item[2].get_text() 39 40 shcoolInfo = findSchoolInfo("https://yz.chsi.com.cn/sch/search.do?start=0" 41 handleSchoolInfo(shcoolInfo) 42 print("爬取完成")
在findSchoolInfo方法中我们初步对数据进行了一个处理,使用了findAll来进行了数据的首次爬取,可以看到所需要的表格已经被爬取到了

在handleSchoolInfo方法中同样使用到了findAll("tr")来对数据进行一个清洗,通过tr的筛选之后,table标签已经没有了
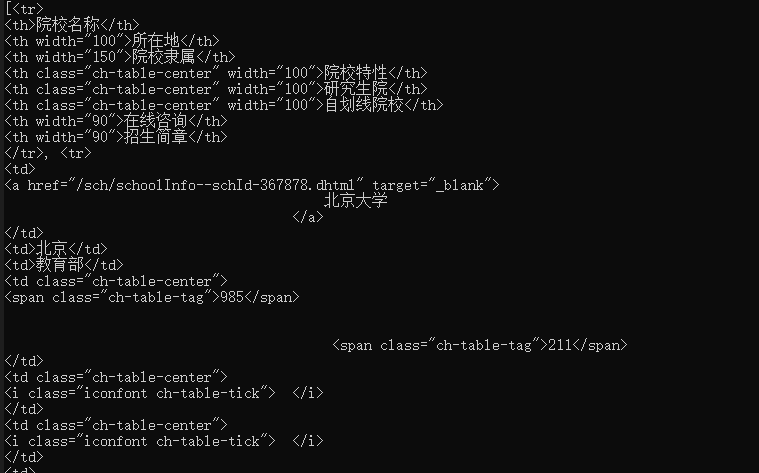
同理我们使用findAll("td")来进行td的筛选,同时可以发现一个数据是为空的,因为通过前面tr的筛选的首行信息里面是th而不是td的

接下来由于只需要每个数据的前三行,所以只需要将前三个数据保存即可,然后将保存的数据进行一个有效数据的剥离
1 school_list.append(school[0:3]) 2 for item in school_list: 3 school_name = item[0].get_text().strip() 4 school_shengfen = item[1].get_text() 5 shcool_belong = item[2].get_text()
但是此时爬取到的数据也仅仅是当前页的数据,通过分析研招网的链接不难得知,每一页之间的差距仅仅是在最后的参数不同,那么在爬虫的URL进行修改即可
https://yz.chsi.com.cn/sch/?start=0
https://yz.chsi.com.cn/sch/?start=20
1 index = 0 2 while index < 44: 3 shcoolInfo = findSchoolInfo("https://yz.chsi.com.cn/sch/search.do?start="+str(index*20)) 4 handleSchoolInfo(shcoolInfo) 5 index+=1
数据库的连接
使用的数据库是SQL Server 2012,首先需要的是进行包的安装与引入使用的是
import pyodbc
安装参考包的安装
pyodbc模块是用于odbc数据库(一种数据库通用接口标准)的连接,不仅限于SQL server,还包括Oracle,MySQL,Access,Excel等
连接字符串的编写
conn = pyodbc.connect(r'DRIVER={SQL Server Native Client 11.0};SERVER=数据库的IP地址;DATABASE=需要连接的数据库名称;UID=用户名;PWD=密码')
连接对象的建立
在完成连接字符串之后,我们需要建立连接对象
cursor = conn.cursor()
数据库连接就已经完成了,接下来就是数据库的基本操作了
数据写入到数据库
上面我们已经找到了需要的数据同时也建立了数据库的连接,接下来就是将数据插入到数据库了
1 def insertDB(school_name,school_shengfen,shcool_belong): 2 sql = "INSERT INTO tb_school(school_name,school_shengfen,school_belong) 3 VALUES ('%s', '%s', '%s')" % 4 (school_name,school_shengfen,shcool_belong) 5 try: 6 cursor.execute(sql) 7 conn.commit() 8 print(school_shengfen+" "+school_name+"添加成功") 9 except: 10 print("插入出错") 11 conn.rollback()
我们可以看到数据库内确实已经有数据了
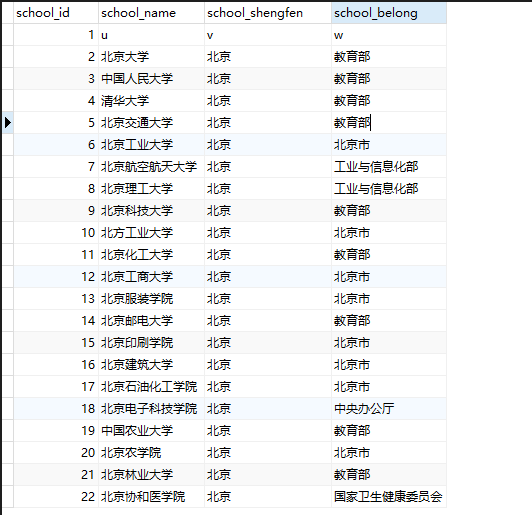
最后关闭数据库的连接
conn.close()
参考引用:
[1] Ryan Mitchell. Web Scraping with Python[M]. O'Reilly Media ,2015.
[2] Python连接SQL Server入门