1. hash表:
又称散列表,以key-value的形式存储数据,能够由key快速定位到其指定的value,而不经过查找。它采用了函数式的映射思想,将记录的存储位置与关键词相关联,从而快速定位进行查找,复杂度为O(1)。
2. hash函数:
- key和value的映射关系称为HASH函数,通过该函数可以计算key所对应的存储位置(表中存储位置,不是实际物理地址),即HASH地址。
- 构造HASH地址的方法有:
(1)直接定址法:取关键词或关键词的某个线性函数为hash地址。
(2)平方取中法:关键词的平方取中间某几个数构成hash地址。
(3)折叠法:将关键词拆分成几部分,然后以特定方式组合构成hash地址。
- 避免hash地址发生冲突的解决办法:
(1)开放定址法:当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。
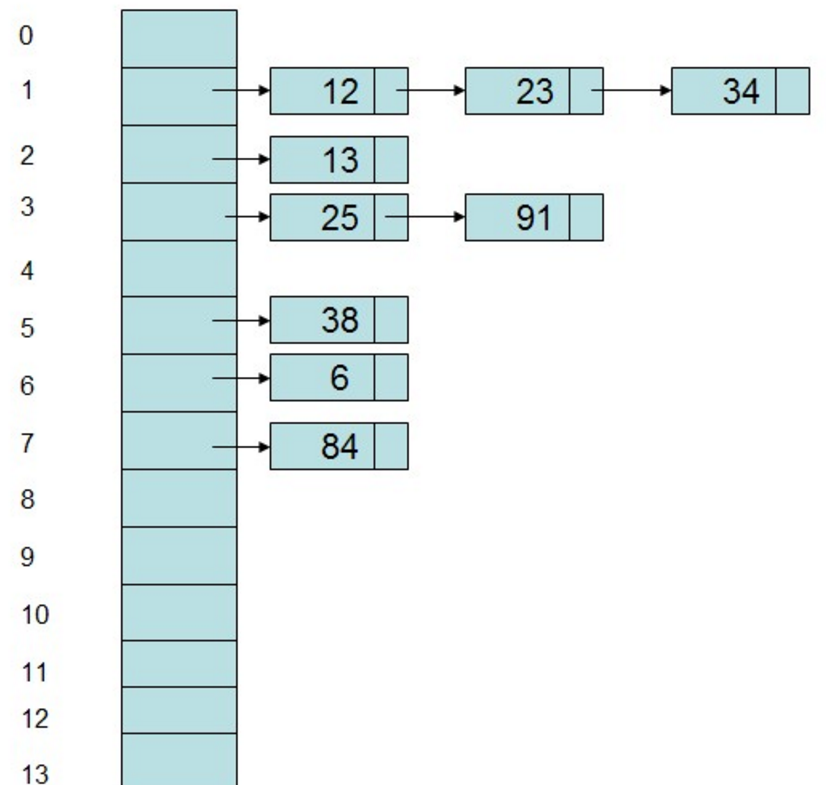
(2)链地址法:采用数组和链表相结合的办法,将Hash地址相同的记录存储在一张线性表中,而每张表的表头的序号即为计算得到的Hash地址。
3. HASH表的优缺点:
优点:O(1)时间复杂度进行查找,删除和插入操作容易。
缺点:不能排序,占用空间大,记录的关键词不能重复。
4.常用hash函数:
/* 除余法哈希函数( 不适用于表很大的情况 ) */ int hash(const std::string & key,int tablesize) { int hashvalue = 0; for(unsigned int i=0;i<key.length();++i) hashvalue += key[i]; return hashvalue % tablesize; } /* RS哈希函数 */ int RSHash(const std::string & str) { int b = 378551; int a = 63689; int hash = 0; for(unsigned int i = 0; i < str.length(); i++) { hash = hash * a + str[i]; a = a * b; } return hash; }