比如Count(*) FROM E_Table WHERE [date] > '2008-1-1' AND istrue = 0
由于操作的数据比较大(400万以上),所以使用了两个数据库,一个用于更新,执行频繁的Insert、Update操作,把索引建在了主键id上,另一个数据库定时复制前一个数据库的数据,用于检索查询,在[date]字段上建立了聚簇索引,在[istrue]字段上建立了非聚簇索引。这样下来,每次Count花费不超过2s的时间。
后来又复制了一份数据库,做了一些字段的调整,其中istrue字段被删除,非聚簇索引也去除了,而[date]字段和聚簇索引没有变动。
结果在执行Count(*) FROM E_Table WHERE [date] > '2008-1-1'的时候,却出现了奇怪的现象,原本以为会更快完成的检索(因为表的条数有减少),反而花费了30+s。
反复检查两个表,没有发现除了非聚簇索引外的不同,又测试在前一个表上执行相同的Count(*) FROM E_Table WHERE [date] > '2008-1-1',花费时间在1s左右。
只好把非聚簇索引和istrue字段加上,结果检索速度立刻回到1s!
一个在检索条件中不出现的字段为什么会影响检索的效率呢?仔细对比两次的Excuting Plan,终于发现了问题所在:
花费30s的检索第一步:
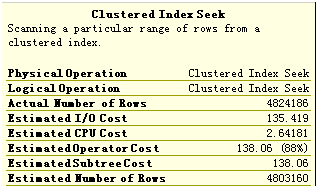
花费1s的检索第一步:

除了两者的操作不同(一般情况下,Clustered Index Seek的速度应该快于Index Scan),CPU Cost是近似的,Number of Rows是一样的,最大的差别在I/O Cost上,前者是后者的5倍!
究其原因,主要是因为SQL Server执行Count操作的策略。当建有索引时,而且Count的参数是*或者Not Null类型的字段时,SQL Server会对所有索引列中体积最小的索引进行Scan。而istrue字段是bit类型的,只占1个字节,[date]字段是smalldatetime类型的,占4个字节。检索前者的I/O自然远远小于检索后者的,在同样的内存条件下,通过前者检索花费的时间也要远小于后者。
当然,如果Count的参数是某个Null类型的字段,SQL Server则只能对该字段进行Scan,因为这时该字段为Null的记录不记录的。所以,一个优化建议是,尽量少用Null类型字段,使用默认值+bit类型的索引字段会提高Count检索的效率。
另外:关于where条件
COUNT时的WHERE
简单说下,就是COUNT的时候,如果没有WHERE限制的话,MySQL直接返回保存有总的行数
而在有WHERE限制的情况下,总是需要对MySQL进行全表遍历。
优化总结:
1.任何情况下SELECT COUNT(*) FROM tablename是最优选择;
2.尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种查询;
3.杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现。