一、JDK 8 版本下 JVM 对象的分配、布局、访问(简单了解下)
1、对象的创建过程
(1)前言
Java 是一门面向对象的编程语言,程序运行过程中在任意时刻都可能有对象被创建。开发中常用 new 关键字、反射等方式创建对象, JVM 底层是如何处理的呢?
(2)对象的创建的几种常见方式?
Type1:使用 new 关键字创建(常见比如:单例模式、工厂模式等创建)。
Type2:反射机制创建(调用 class 的 newInstance() 方法)。
Type3:克隆创建(实现 Cloneable 接口,并重写 clone() 方法)。
Type4:反序列化创建。
(3)对象创建步骤
Step1:判断对象对应的类 是否已经被 加载、解析、初始化过。
虚拟机执行 new 指令时,先去检查该指令的参数 能否在 方法区(元空间)的运行时常量池中 定位到 某个类的符号引用,并检查这个符号引用代表的 类是否 被加载、解析、初始化过。如果没有,则在双亲委派模式下,查找相应的类 并加载。
Step2:为对象分配内存空间。
类加载完成后,即可确定对象所需的内存大小,在堆中根据适当算法划分内存空间给对象。
划分算法:
划分算法根据 Java 堆中内存是否 规整进行可划分为:指针碰撞、空闲列表。
堆内存规整时,采用指针碰撞方式分配内存空间,由于内存规整,即指针只需移动 所需对象内存 大小即可。
堆内存不规整时,采用空闲列表方式分配内存空间,存在内存碎片,需要维护一个列表用于记录哪些内存块可用,在列表中找到足够大的内存空间分配给对象。
堆内存是否规整:
堆内存是否规整由 垃圾回收器算法决定。
使用 Serial、ParNew 等带有 Compact(压缩)过程的垃圾回收器时,堆内存规整,即指针碰撞。
使用 CMS 等带有 Mark-Sweep(标记清除)算法的垃圾回收器时,堆内存不规整,即空闲列表。
Step3:处理并发安全问题。
分配内存空间时,指针修改可能会碰到并发问题(比如 对象 A 分配内存后,但指针还没修改,此时 对象 B 仍使用原来指针 进行内存分配,那么 A 与 B 就会出现冲突)。
解决方式一:
对分配内存空间的动作进行同步处理(CAS 加上失败重试 保证更新操作的原子性)。
解决方式二:
将分配内存空间的动作按照线程划分到不同空间中执行(Thread Local Allocation Buffer,TLAB,每个线程在堆中预先分配一小块内存空间,哪个线程需要分配内存,就在哪个 TLAB 上进行分配)。
Step4:初始化属性值。
将内存空间中的属性 赋 零值(默认值)。
Step5:设置对象的 对象头。
将对象所属 类的元数据信息、对象的哈希值、对象 GC 分代年龄 等信息存储在对象的对象头。
Step6:执行 <init> 方法进行初始化。
执行 <init> 方法,加载 非静态代码块、非静态变量、构造器,且执行顺序为从上到下执行,但构造器最后执行。并将堆内对象的 首地址 赋值给 引用变量。
2、对象内存布局
(1)对象内存布局
对象在内存中存储布局可以分为:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。
(2)对象头(Header)
对象头用于存储 运行时元数据 以及 类型指针。
运行时元数据:
对象的哈希值、GC 分代年龄、锁状态标志、偏向时间戳等。
类型指针:
即对象指向 类元数据的 指针(通过该指针确定该对象属于哪个类)。
(3)实例数据(Instance Data)
其为对象 存储的真实有效信息,即程序中 各类型字段的内容。
(4)对齐填充(Padding)
不是必然存在的,起着占位符的作用。比如 HotSpot 中对象大小为 8 字节的整数倍,当对象实例数据不是 8 字节的整数倍时,通过对齐填充补全。
3、对象访问定位(句柄访问、直接指针)
(1)问题
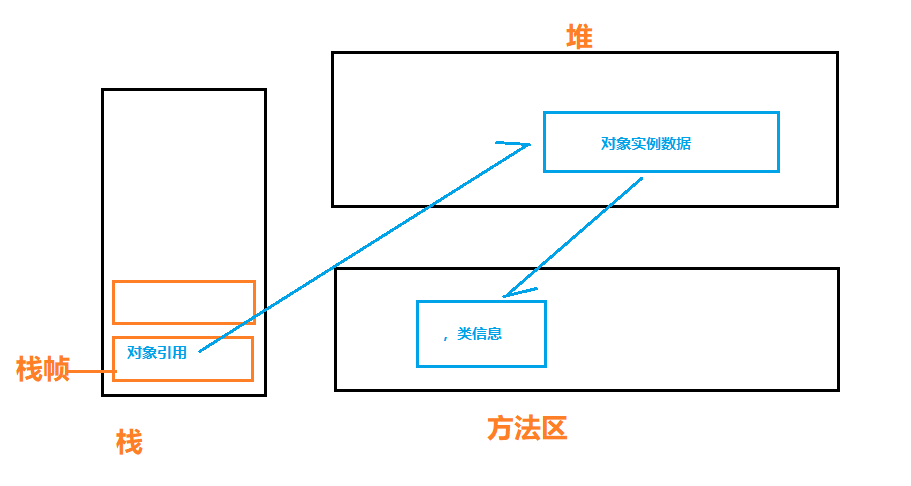
对象 存于堆中,而对象的引用 存放在栈帧中,如何根据 栈帧存放的引用 定位 堆中存储的对象,即为对象访问定位问题。取决于 JVM 的具体实现,常见方式:句柄访问、直接指针。
(2)句柄访问
在堆中划分出一块内存作为 句柄池,用于保存对象的句柄地址(指针),而栈帧中存放的即为 句柄地址。
当对象被移动(垃圾回收)时,只需要改变 句柄池中 指向对象实例数据的指针 即可,不需要修改栈帧中的数据。

(3)直接访问(HotSpot 使用)
栈帧中直接存放 对象实例数据的地址,对象移动时,需要修改栈帧中的数据。
相较于 句柄访问,减少了一次 指针定位的时间开销(积少成多还是很可观的)。
二、JDK8 中的 String(可以深入研究一下,有不对的地方还望不吝赐教)
1、String 基本概念(JDK9 稍作改变)
(1)基本概念
String 指的是字符串,一般使用双引号括起来 "" 表示(比如: "hello")。
使用 final 类型修饰 String 类,表示不可被继承。
String 类实现了 Serializable 接口,表示字符串支持序列化。
String 类实现了 Comparable 接口,表示可以比较大小。
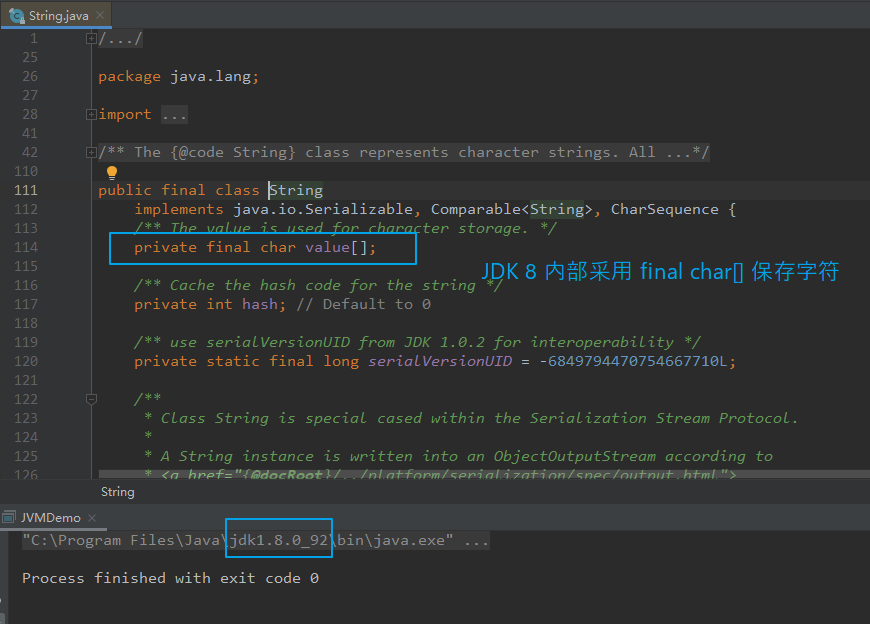
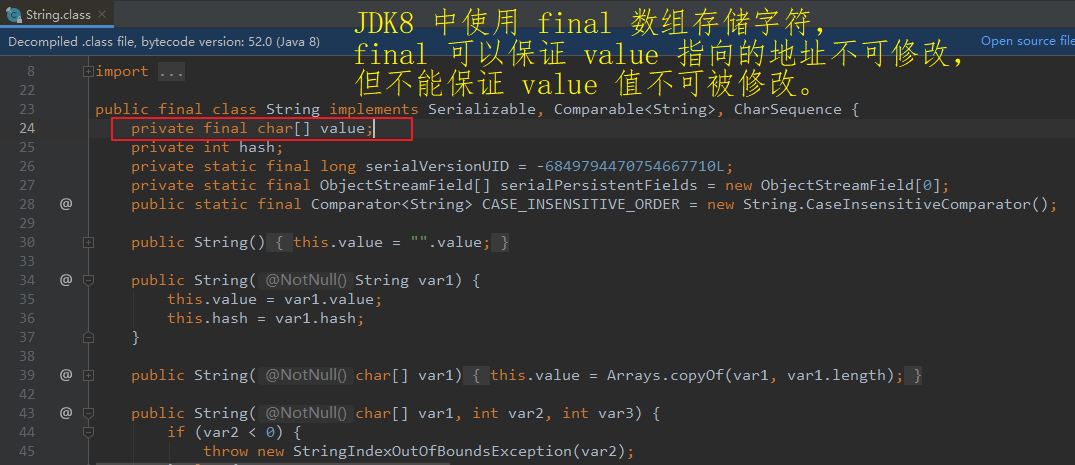
String 类内部使用 final 修饰的数组存储字符。
注:
JDK8 及以前 内部使用 final char[] value 用于存储字符串数据,
JDK9 时改为 final byte[] 存储数据(内部将 每个字符 与 0xFF 比较,当有一个比 0xFF 大时,使用 2 个字节存储,否则使用 1 个字节存储)。
【JDK 8:】
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; }
(2)赋值方式
String 赋值一般分为:字面量直接赋值、使用 new 关键字通过构造器赋值。
【字面量直接赋值:(值会存放于 字符串常量池 中)】 String a = "hello"; 【new + 构造器赋值:(值可能会存放于 字符串常量池 中,且 new 关键字会在堆中创建一个对象)】 String a = new String("hello"); 注: 值不一定会存放于 字符串常量池中,可以调用 String 的 intern() 方法将值放于字符串常量池中。 intern() 方法在不同 JDK 版本中实现不同,后面会举例,此处大概有个印象即可。
2、字符串常量池(String Pool)、String 不可变性
(1)字符串常量池(String Pool)
JVM 内部维护一个 字符串常量池(String Pool),当 String 以字面量形式赋值时,此时字符串会声明在字符串常量池中(比如:String a = "hello" 赋值时,会生成一个 "hello" 字符串存于 常量池中)。
字符串常量池中不会存储相同内容的字符串,其内部实现是一个固定大小的 Hashtable,如果常量池中存储 String 过多,将会造成 hash 冲突,从而造成性能下降,可以通过 -XX:StringTableSize 设置 StringTable 大小(比如:-XX:StringTableSize=2000)。
注:
常量池类似于 缓存,使程序运行更快、节省内存。
JDK 6 及以前,字符串常量池存放于 永久代中,StringTable 默认长度为 1009。
JDK 7 及之后,字符串常量池存放于 堆中,StringTable 默认长度为 60013,其最小值为 1009。
【常用 JVM 参数:】 -XX:StringTableSize 配置字符串常量池中的 StringTable 大小,JDK 8 默认:60013。 -XX:+PrintStringTableStatistics 在JVM 进程退出时,打印出 StringTable 相关统计信息。
(2)String 不可变性:
String 一旦在内存中创建,其值将是不可变的(反射场景除外)。当值改变时,改变的是指向内存的引用,而非直接修改内存中的值。
JDK 8 String 不可变:
JDK8 采用 final 修饰 String 类,表示该类不可被继承。
String 类内部采用 private final char value[] 存储字符串,使用 private 修饰数组且不对外提供 setter 方法,即 外部不可修改字符串。使用 final 修饰数组,表示 内部不可修改字符串(引用地址不变,内容可变,使用反射可能会改变字符串)。且 String 提供的相关方法中,并没有去修改原有字符串中的值,而是返回一个新的引用指向内存中新的 String 值(比如 replace() 方法返回一个 new String() 对象)。
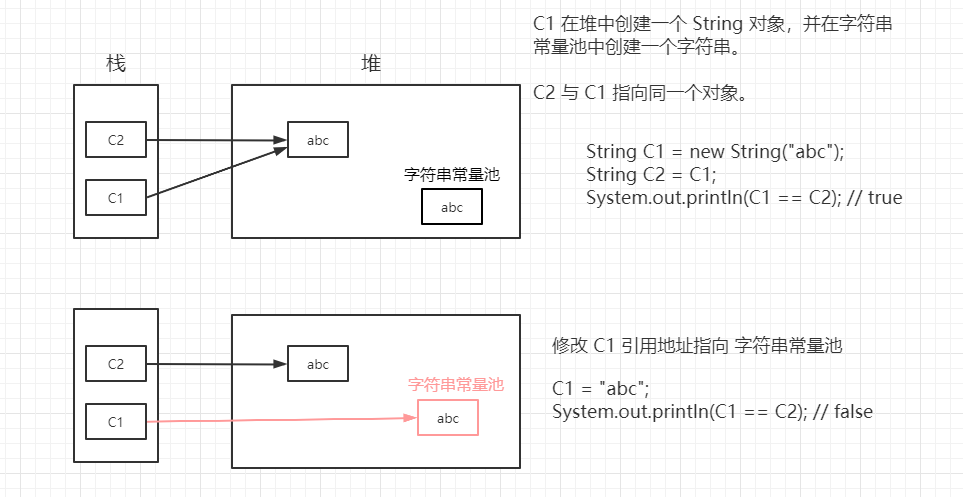
(3)常见场景(修改引用地址)
对现有字符串重新赋值时。
对现有字符串进行连接操作时。
使用字符串的 replace() 方法修改指定字符串时。
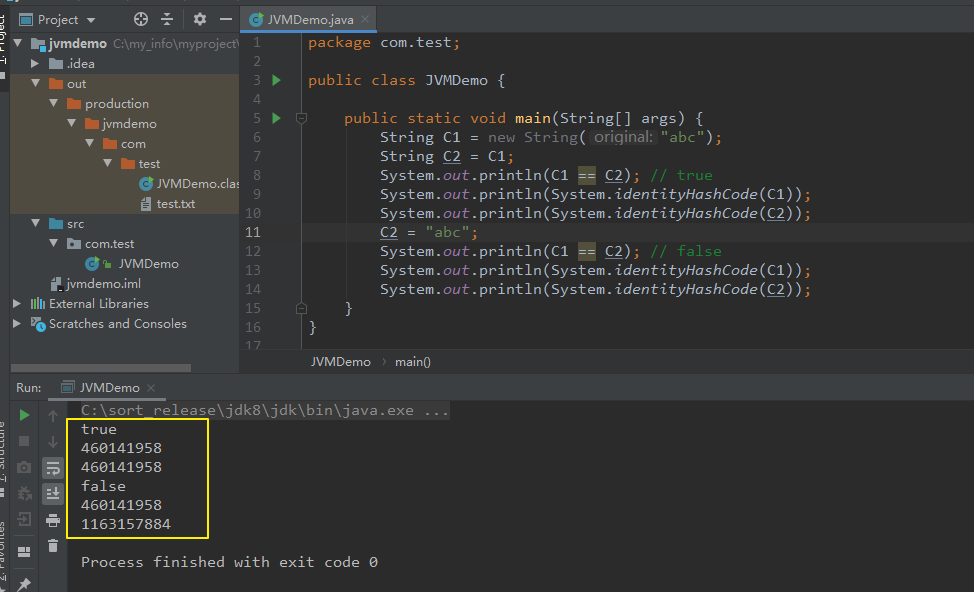
【举例:(给现有字符串重新赋值)】 package com.test; public class JVMDemo { public static void main(String[] args) { String C1 = new String("abc"); String C2 = C1; System.out.println(C1 == C2); // true System.out.println(System.identityHashCode(C1)); System.out.println(System.identityHashCode(C2)); C2 = "abc"; System.out.println(C1 == C2); // false System.out.println(System.identityHashCode(C1)); System.out.println(System.identityHashCode(C2)); } }
3、String 拼接操作 -- 笔试题
(1)拼接操作可能存在的情况:
常量与常量(字面量或者 final 修饰的变量)的拼接结果会存放于常量池中,由编译期优化导致。
拼接数据中若有一个是变量,则拼接结果 会存放于 堆中。由 StringBuilder 拼接。
如果拼接结果调用 intern() 方法,且常量池中不存在该字符串对象,则将拼接结果 存放于 常量池中。
(2)常量(字面量)拼接 -- 拼接结果存于常量池
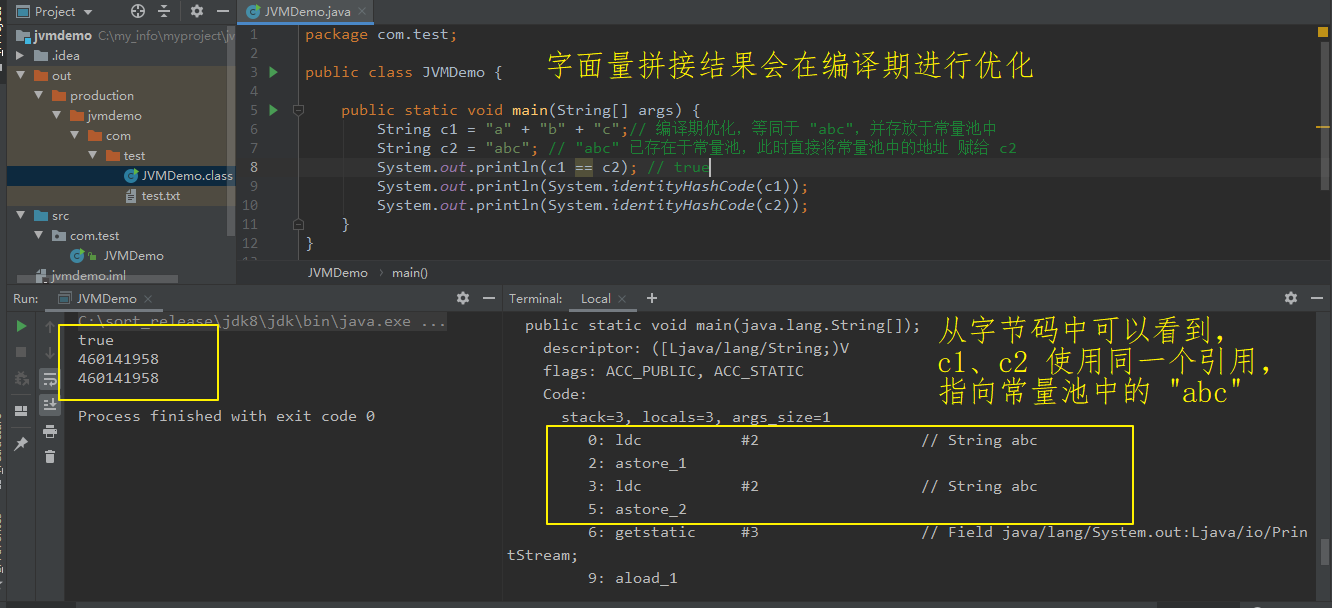
对于两个及以上字面量拼接操作,在编译时会进行优化,若该拼接结果不存在于常量池中,则直接将其拼接结果存于常量池,并返回其引用地址。否则,返回常量池中该结果所在的引用地址。
【举例:】 package com.test; public class JVMDemo { public static void main(String[] args) { String c1 = "a" + "b" + "c";// 编译期优化,等同于 "abc",并存放于常量池中 String c2 = "abc"; // "abc" 已存在于常量池,此时直接将常量池中的地址 赋给 c2 System.out.println(c1 == c2); // true System.out.println(System.identityHashCode(c1)); System.out.println(System.identityHashCode(c2)); } }
(3)final 修饰的变量拼接(可以理解为常量) -- 拼接结果存于常量池
由于 final 修饰的变量不可被修改,在编译期优化等同于 常量进行拼接操作,所以结果存放于常量池中。
【举例:】 package com.test; public class JVMDemo { public static void main(String[] args) { final String c1 = "hello"; final String c2 = "world"; String c3 = "helloworld"; // "helloworld" 存放于常量池中 String c4 = c1 + c2; // 等价于 "hello" + "world" 常量进行拼接操作 System.out.println(c3 == c4); // true System.out.println(System.identityHashCode(c3)); System.out.println(System.identityHashCode(c4)); } }
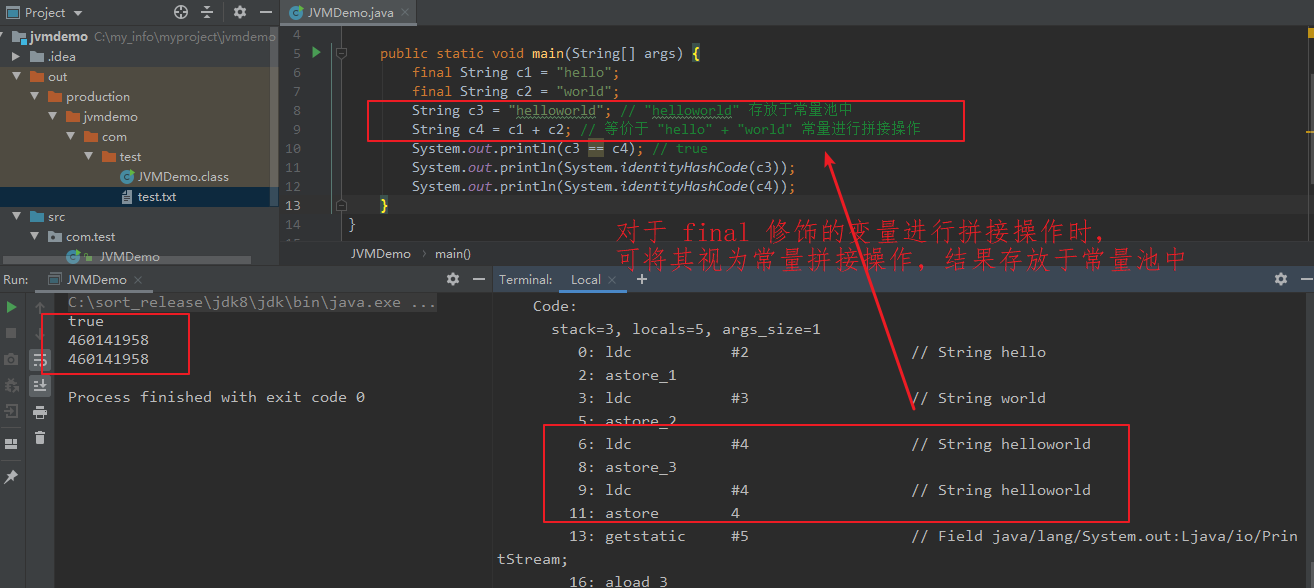
(4)一般变量拼接 -- 拼接结果存于 堆
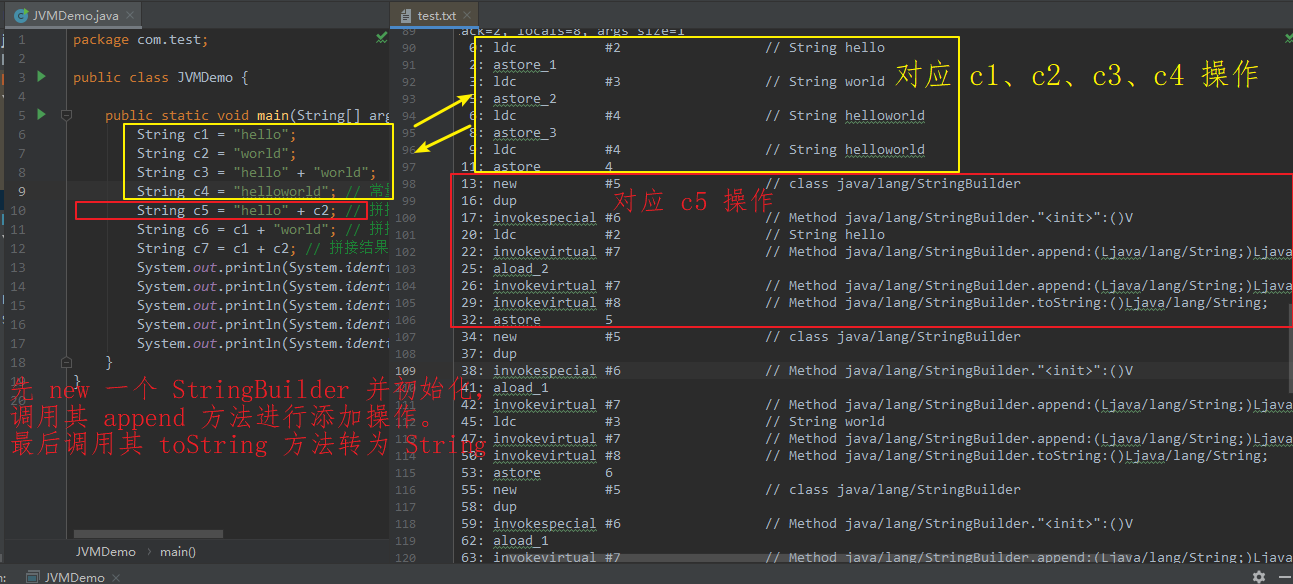
拼接操作中出现变量时,会触发 new StringBuilder 操作,并使用 StringBuilder 的 append 方法进行字符串拼接,最终调用其 toString 方法转为字符串,并返回引用地址。
注:
StringBuilder 的 toString 方法内部调用 new String(),其最终拼接结果存放于 堆 中(不会将拼接结果存放于常量池,可以手动调用 intern() 方法将结果放入常量池,后面介绍,往下看)。
使用 StringBuilder 进行字符串拼接操作效率要远高于使用 String 进行字符串拼接操作。
使用 String 直接进行拼接操作时,若出现变量,则会先创建 StringBuilder 对象,最终输出结果还得转为 String 对象,即使用 String 进行字符串拼接过程中 可能出现多个 StringBuilder 和 String 对象(比如在 循环中 进行字符串拼接操作),且创建对象过多会占用更多的内存。
而使用 StringBuilder 进行拼接操作时,只需要创建一个 StringBuilder 对象即可,可以节省内存空间以及提高效率执行。
【举例:】 package com.test; public class JVMDemo { public static void main(String[] args) { String c1 = "hello"; String c2 = "world"; String c3 = "hello" + "world"; // 等价于 "helloworld",存于常量池 String c4 = "helloworld"; // 常量池中已存在,直接赋值常量池引用 String c5 = "hello" + c2; // 拼接结果存于 堆 String c6 = c1 + "world"; // 拼接结果存于 堆 String c7 = c1 + c2; // 拼接结果存于 堆 System.out.println(System.identityHashCode(c3)); System.out.println(System.identityHashCode(c4)); System.out.println(System.identityHashCode(c5)); System.out.println(System.identityHashCode(c6)); System.out.println(System.identityHashCode(c7)); } }
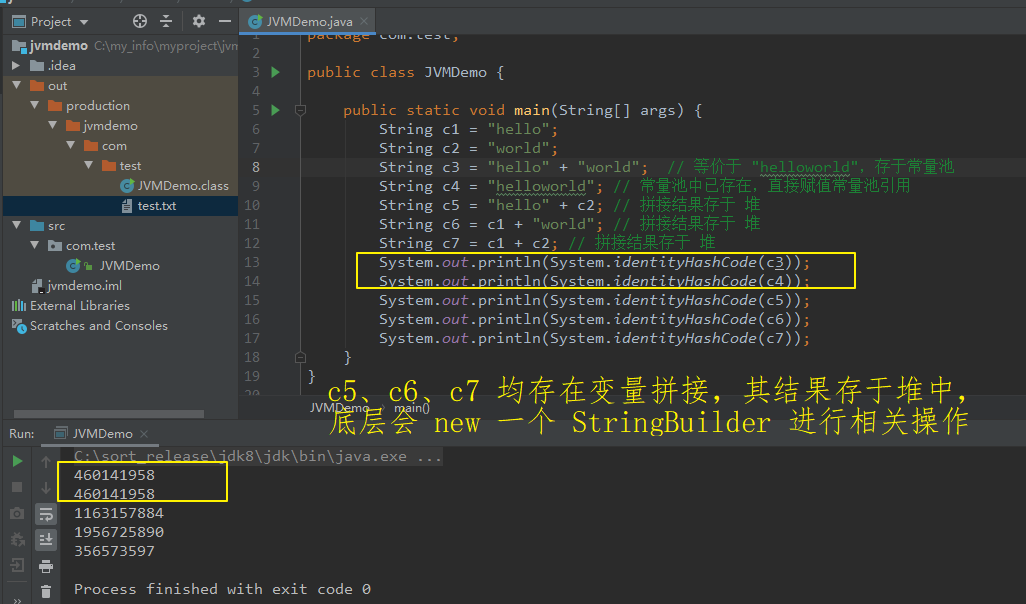
(5)拼接结果调用 intern 方法 -- 结果存放于常量池
由于不同版本 JDK 的 intern() 方法执行结果不同,此处暂时略过,接着往下看。
4、String 使用 new 关键字创建对象问题 -- 笔试题
(1)new String("hello") 会创建几个对象?
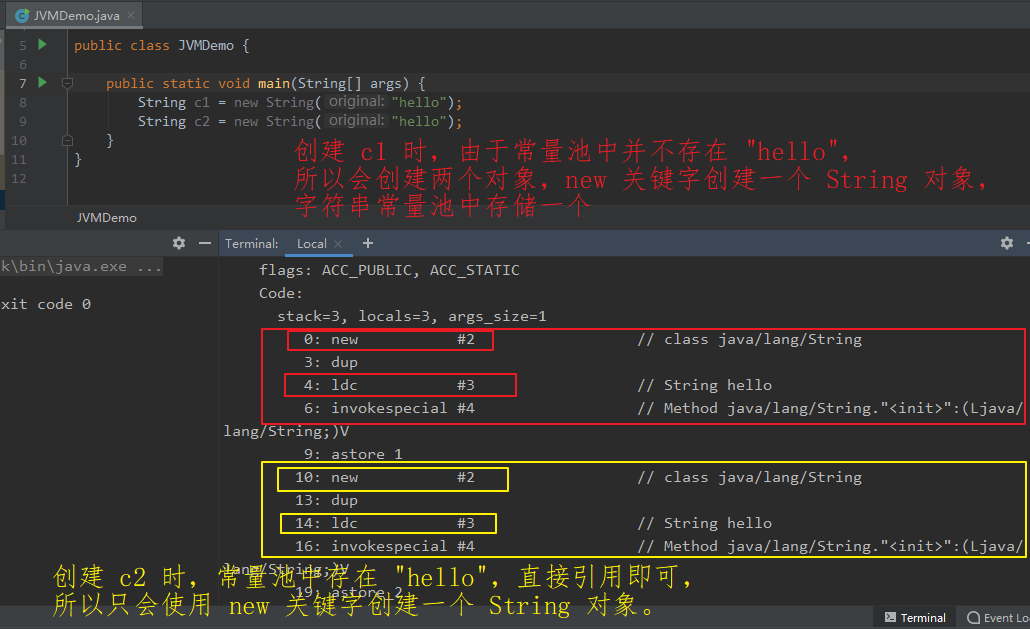
可能会创建 1 个或 2 个对象。
new 关键字会在堆中创建一个对象,而当字符串常量池中不存在 "hello" 时,会创建一个对象存入字符串常量池。若常量池中存在对象,则不会创建、会直接引用。
【举例:】 public class JVMDemo { public static void main(String[] args) { String c1 = new String("hello"); String c2 = new String("hello"); } }
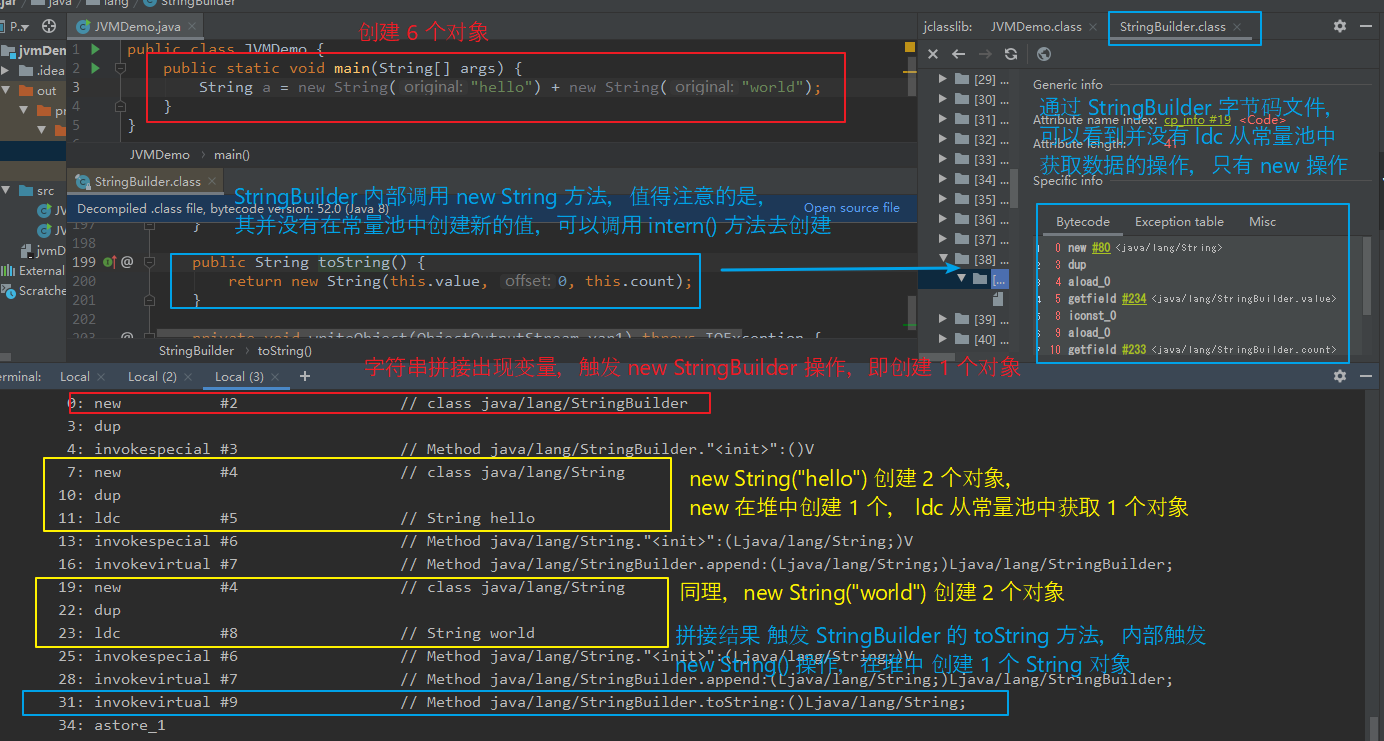
(2)new String("hello") + new String("world") 创建了几个对象?
创建了 6 个对象(不考虑常量池是否存在数据)。
对象创建:
由于涉及到变量的拼接,所以会触发 new StringBuilder() 操作。此处创建 1 个对象。
new String("hello") 通过上例分析,可以知道会创建 2 个对象(堆 1 个,字符串常量池 1 个)。
同理 new String("world") 也会创建 2 个对象。
最终拼接结果 会触发 StringBuilder 的 toString() 方法,内部调用 new String() 在堆中创建一个对象(此处不会在字符串常量池中创建对象)。
注:
StringBuilder 的 toString() 内部的 new String() 并不会在 字符串常量池 中创建对象。
String str = new String("hello"); 这种形式创建的字符串 可以在字符串常量池中创建对象。
此处我是根据 字节码文件 中是否有 ldc 指令来判断的(后续根据 intern() 方法同样也可以证明这点),有不对的地方,还望不吝赐教。
【举例:】 public class JVMDemo { public static void main(String[] args) { String a = new String("hello") + new String("world"); } }
5、String 中的 intern() 相关问题 -- 笔试题
(1)intern() 作用
对于非字面量直接声明的 String 对象(通过 new 创建的对象),可以使用 String 提供的 intern 方法获取字符串常量池中的数据。
该方法作用:
从字符串常量池中查询当前字符串是否存在(通过 equals 方法比较),如果不存在,则会将当前字符串放入常量池中并返回该引用地址(此处不同版本的 JDK 有不同的实现)。若存在则直接返回引用地址。
【JDK 8 注释】 /** * Returns a canonical representation for the string object. * <p> * A pool of strings, initially empty, is maintained privately by the * class {@code String}. * <p> * When the intern method is invoked, if the pool already contains a * string equal to this {@code String} object as determined by * the {@link #equals(Object)} method, then the string from the pool is * returned. Otherwise, this {@code String} object is added to the * pool and a reference to this {@code String} object is returned. * <p> * It follows that for any two strings {@code s} and {@code t}, * {@code s.intern() == t.intern()} is {@code true} * if and only if {@code s.equals(t)} is {@code true}. * <p> * All literal strings and string-valued constant expressions are * interned. String literals are defined in section 3.10.5 of the * <cite>The Java™ Language Specification</cite>. * * @return a string that has the same contents as this string, but is * guaranteed to be from a pool of unique strings. */ public native String intern();
(2)不同 JDK 版本中 intern() 使用的区别
JDK 6:尝试将该字符串对象 放入 字符串常量池中(字符串常量池位于 方法区中),
若字符串常量池中已经存在 该对象,则返回字符串常量池 当前对象的引用地址。
若没有该对象,则将 当前对象值 复制一份放入字符串常量池,并返回此时对象的引用地址。
JDK 7 之后:尝试将该字符串对象 放入 字符串常量池中(字符串常量池位于 堆中),
若字符串常量池中已经存在 该对象,则返回字符串常量池 当前对象的引用地址。
若没有该对象,则将 当前对象的 引用地址 复制一份放入字符串常量池,并返回引用地址。
(3)使用 JDK8 演示 intern()
此处使用 JDK8 演示 intern() 方法,有兴趣可以自行研究 JDK6 的操作。
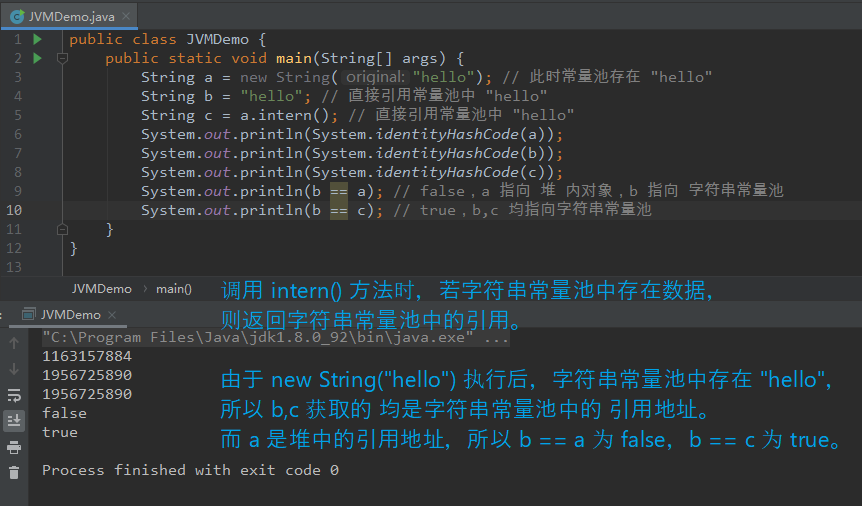
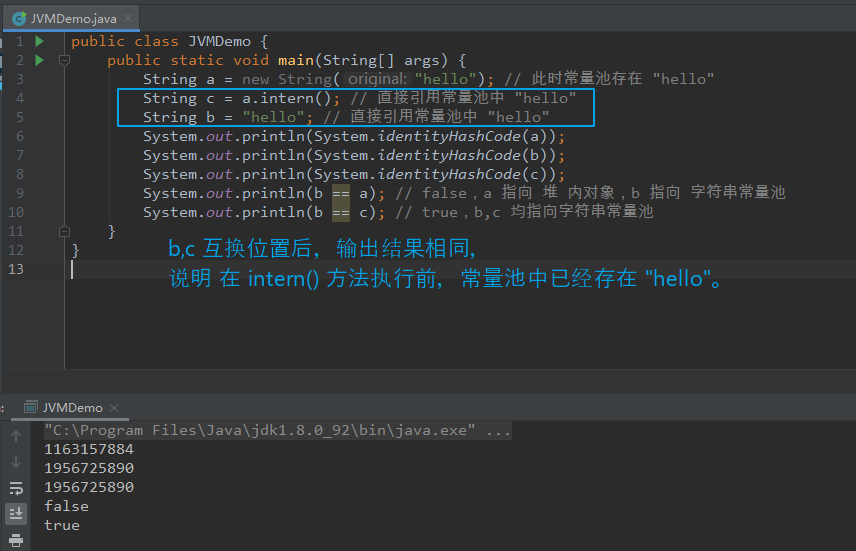
【例一:】 public class JVMDemo { public static void main(String[] args) { String a = new String("hello"); // 此时常量池存在 "hello" String b = "hello"; // 直接引用常量池中 "hello" String c = a.intern(); // 直接引用常量池中 "hello" System.out.println(System.identityHashCode(a)); System.out.println(System.identityHashCode(b)); System.out.println(System.identityHashCode(c)); System.out.println(b == a); // false,a 指向 堆 内对象,b 指向 字符串常量池 System.out.println(b == c); // true,b,c 均指向字符串常量池 } } 【例二:(b,c 互换位置)】 public class JVMDemo { public static void main(String[] args) { String a = new String("hello"); // 此时常量池存在 "hello" String c = a.intern(); // 直接引用常量池中 "hello" String b = "hello"; // 直接引用常量池中 "hello" System.out.println(System.identityHashCode(a)); System.out.println(System.identityHashCode(b)); System.out.println(System.identityHashCode(c)); System.out.println(b == a); // false,a 指向 堆 内对象,b 指向 字符串常量池 System.out.println(b == c); // true,b,c 均指向字符串常量池 } } 【分析:】 例一 与 例二 的区别在于 intern() 执行时机不同,且两者输出结果相同。 JDK 8 中 intern() 执行时,若字符串常量池中 equals 未比较出相同数据,则将当前对象的引用地址 复制一份并放入常量池。 若存在数据,则返回常量池中数据的引用地址。 即 new String() 操作后,若常量池中不存在 数据,则调用 intern() 后,会复制 堆的地址 并存入 常量池中。后续获得的均为 堆的地址。也即上述 例一、例二 中 a、b、c 操作后,均相同且指向 堆。 若常量池存在数据,则调用 intern() 后,返回常量池引用,后续获得的均为 常量池引用。也即上述 例一、例二 中 a 为指向堆 的引用地址,b,c 均为指向常量池的引用地址。 通过输出结果可以看到,上述 例一、例二 中 a、b、c 操作后,b, c 相同且不同于 a(即 b、c 指向常量池),从侧面也反映出 new String("hello") 执行后 常量池中存在 "hello"。
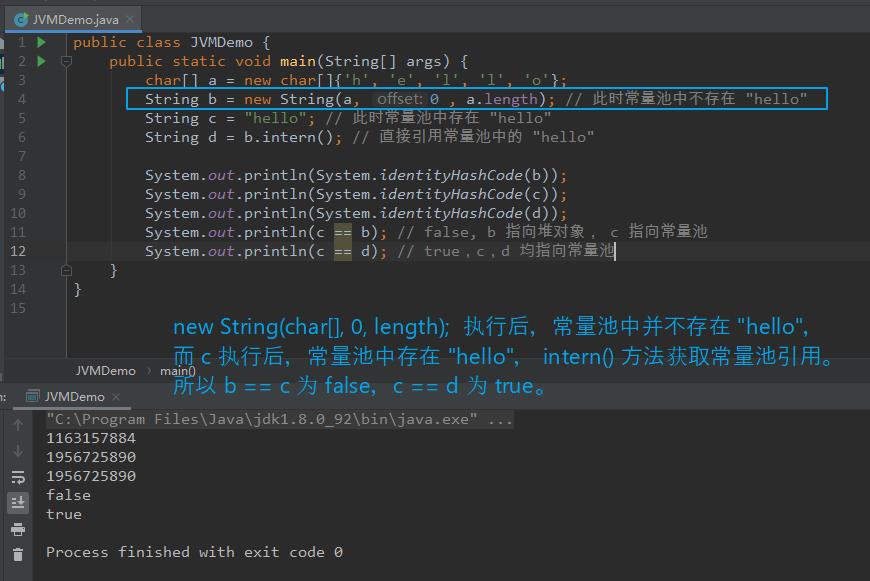
【例四:】 public class JVMDemo { public static void main(String[] args) { char[] a = new char[]{'h', 'e', 'l', 'l', 'o'}; String b = new String(a, 0 , a.length); // 此时常量池中不存在 "hello" String c = "hello"; // 此时常量池中存在 "hello" String d = b.intern(); // 直接引用常量池中的 "hello" System.out.println(System.identityHashCode(b)); System.out.println(System.identityHashCode(c)); System.out.println(System.identityHashCode(d)); System.out.println(c == b); // false, b 指向堆对象, c 指向常量池 System.out.println(c == d); // true,c,d 均指向常量池 } } 【例五:】 public class JVMDemo { public static void main(String[] args) { char[] a = new char[]{'h', 'e', 'l', 'l', 'o'}; String b = new String(a, 0 , a.length); // 此时常量池中不存在 "hello" String d = b.intern(); // 常量池不存在 "hello",复制 b 的引用到常量池中(指向堆的引用) String c = "hello"; // 直接获取常量池中的引用(指向堆的引用) System.out.println(System.identityHashCode(b)); System.out.println(System.identityHashCode(c)); System.out.println(System.identityHashCode(d)); System.out.println(c == b); // true, c, b 均指向堆 System.out.println(c == d); // true, c, d 均指向堆 } } 【分析:】 例四 与 例五 的区别在于 intern() 执行时机不同,且两者输出结果相同。 JDK 8 中 intern() 执行时,若字符串常量池中 equals 未比较出相同数据,则将当前对象的引用地址 复制一份并放入常量池。 若存在数据,则返回常量池中数据的引用地址。 例四中,new String() 执行后,常量池中不存在 "hello", 但 String c = "hello" 执行后,常量池中存在 "hello",从而 intern() 获取的是常量池中的引用地址。 也即 b 为指向 堆的引用,c,d 均为指向常量池的引用。 例五中,new String() 执行后,常量池中不存在 "hello", intern() 执行后会将当前对象地址(指向堆的引用)复制并放入常量池,从而 String c = "hello" 获取的是常量池的引用地址。 也即 b,c,d 获取的均是指向 堆 的引用。
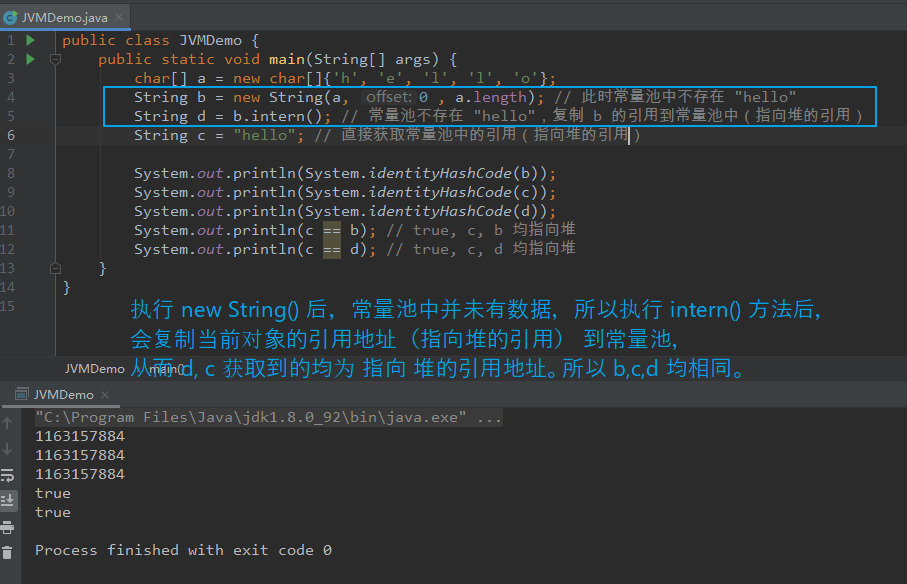
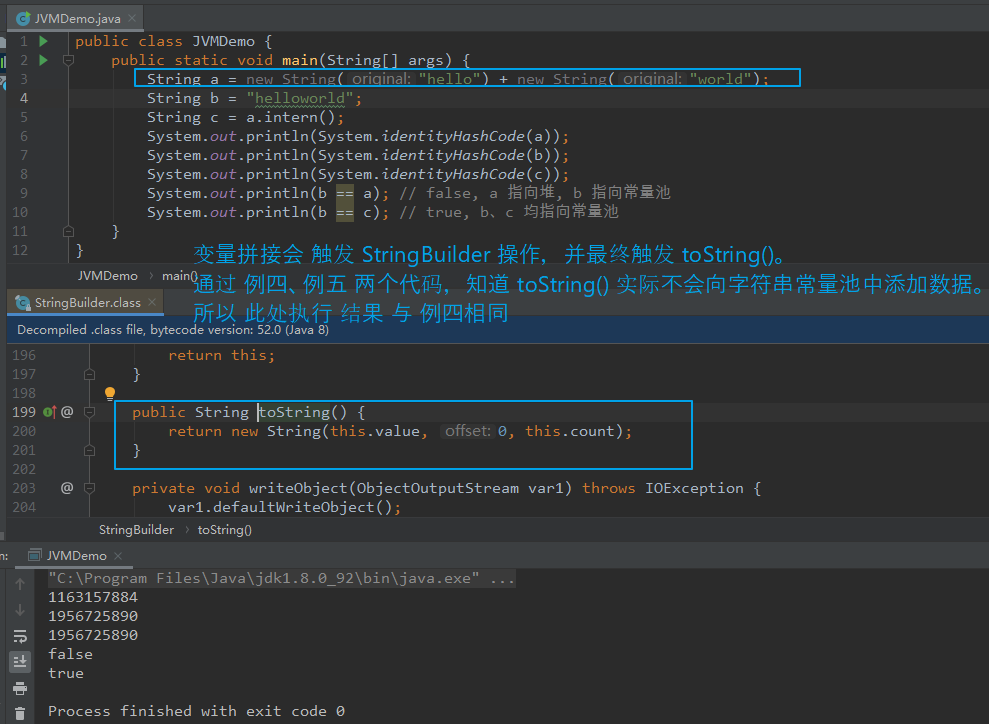
对例四、例五进行一下延伸。
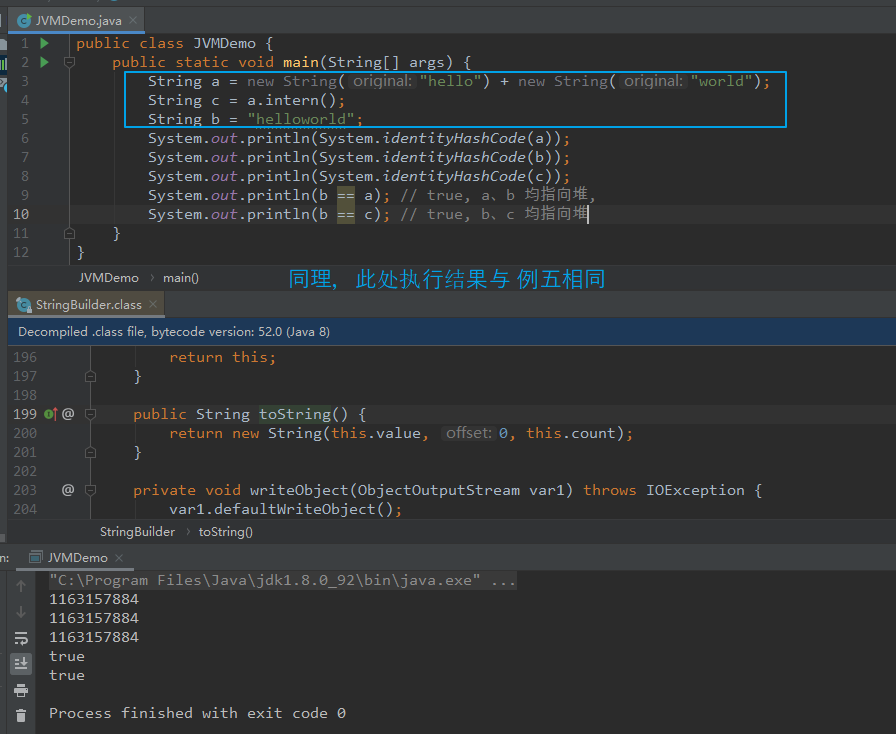
【例六:】 public class JVMDemo { public static void main(String[] args) { String a = new String("hello") + new String("world"); String b = "helloworld"; String c = a.intern(); System.out.println(System.identityHashCode(a)); System.out.println(System.identityHashCode(b)); System.out.println(System.identityHashCode(c)); System.out.println(b == a); // false, a 指向堆, b 指向常量池 System.out.println(b == c); // true, b、c 均指向常量池 } } 【例七:】 public class JVMDemo { public static void main(String[] args) { String a = new String("hello") + new String("world"); String c = a.intern(); String b = "helloworld"; System.out.println(System.identityHashCode(a)); System.out.println(System.identityHashCode(b)); System.out.println(System.identityHashCode(c)); System.out.println(b == a); // true, a、b 均指向堆, System.out.println(b == c); // true, b、c 均指向堆 } } 【分析:】 涉及到变量字符串拼接,会触发 StringBuilder 进行相关操作。 最终触发 toString() 转为 String,其内部调用的是 String(char value[], int offset, int count) 构造方法, 此方法在堆中创建 字符串 但不会向常量池中添加数据(与 例四、例五 是同样的场景)。