笔者想进行数据库查询优化探索,但是前提是需要一个很大的表,因此得先导入大量数据至一张表中。
准备工作
准备一张表,id为主键且自增:

方案一
首先我想到的方案就是通过for循环插入
xml文件:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.zy.route.mapper.BigBiaoMapper"> <resultMap id="BaseResultMap" type="com.zy.route.DO.BigBiao"> <id column="id" property="id"/> <result column="menu" property="menu"/> <result column="operation" property="operation"/> <result column="uri" property="uri"/> <result column="msg" property="msg"/> <result column="creator" property="creator"/> </resultMap> <sql id="tableName"> bigbiao </sql> <sql id="BaseColumn"> `id`, `menu`, `operation`, `uri`, `msg`,`creator` </sql> <sql id="set"> <if test="id != null"> `id` = #{id}, </if> <if test="menu != null"> `menu` = #{menu}, </if> <if test="operation != null"> `operation` = #{operation}, </if> <if test="uri != null"> `uri` = #{uri}, </if> <if test="msg != null"> `msg` = #{msg}, </if> <if test="creator != null"> `creator` = #{creator}, </if> </sql> <insert id="insertIntoBiao" parameterType="com.zy.route.DO.BigBiao"> insert <include refid="tableName"/> <set> <include refid="set"/> </set> </insert> </mapper>
这里我就直接使用SpringBoot的测试类进行插入操作
@SpringBootTest @RunWith(SpringRunner.class) public class BigBiaoMapperTest { @Autowired private BigBiaoMapper bigBiaoMapper; @Test public void insert() { BigBiao bigBiao = new BigBiao() .setMenu("项目资料") .setOperation("查询项目目录") .setUri("/project/big/biao") .setMsg("{"method":"Get"",""costTime:95"",""ip:255.255.255.0"}") .setCreator("LonZyuan"); long start = System.currentTimeMillis(); for (int i = 0; i < 1000; i++) { bigBiaoMapper.insertIntoBiao(bigBiao); } long end = System.currentTimeMillis(); System.out.println("执行时间:" + (end - start) + "ms"); } }
执行,查看执行时间:

可以发现,就单单1000条数据,就花了29s多
原因分析(参考MySQL45讲)
首先我们需要了解一条SQL更新语句是如何执行的:
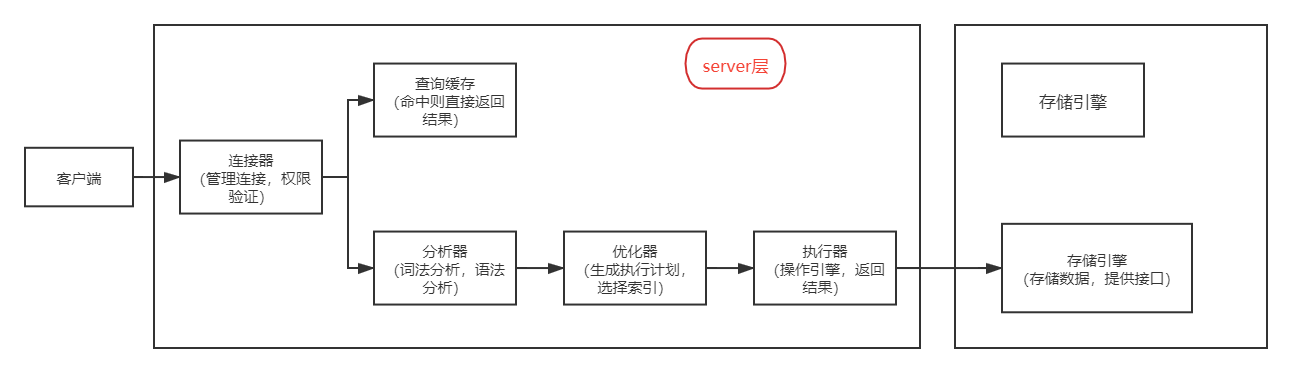
而我方案一中的操作就是,通过for循环,进行了1000次的客户端与数据库的开闭连接,然后每次就写入一条数据,
并且由于表更新后,与该表相关的查询缓存会失效,查询缓存也没用,因此低效是必然的。
方案二
既然一条条插入很慢,那我通过List一次性插入多个不就行了。
xml语句:
<insert id="batchInsert"> insert into bigbiao (`menu`, `operation`, `uri`, `msg`,`creator`) values <foreach collection="list" item="item" separator=","> (#{item.menu},#{item.operation},#{item.uri},#{item.msg},#{item.creator}) </foreach> </insert>
测试类:
@SpringBootTest @RunWith(SpringRunner.class) public class BigBiaoMapperTest { @Autowired private BigBiaoMapper bigBiaoMapper; @Test public void batchInsert() { BigBiao bigBiao = new BigBiao() .setMenu("批量添加2号") .setOperation("batchAdd") .setUri("/begin/batch/add/big/biao") .setMsg("{"method:Insert","costTime:88","ip:0.0.0.255","添加一堆东西"}") .setCreator("LonZyuan"); List<BigBiao> bigBiaos = new ArrayList<>(); long start = System.currentTimeMillis(); for (int i = 0; i < 1000; i++) { bigBiaos.add(bigBiao); } bigBiaoMapper.batchInsert(bigBiaos); long end = System.currentTimeMillis(); System.out.println("执行时间:" + (end - start) + "ms"); } }
运行,查看执行时间:

速度很快,那我现在插10w条进去:
@Test public void batchInsert() { BigBiao bigBiao = new BigBiao() .setMenu("批量添加2号") .setOperation("batchAdd") .setUri("/begin/batch/add/big/biao") .setMsg("{"method:Insert","costTime:88","ip:0.0.0.255","添加一堆东西"}") .setCreator("LonZyuan"); List<BigBiao> bigBiaos = new ArrayList<>(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { bigBiaos.add(bigBiao); } bigBiaoMapper.batchInsert(bigBiaos); long end = System.currentTimeMillis(); System.out.println("执行时间:" + (end - start) + "ms"); }
但是又翻车了:

查一下Packet for query is too large,原来MySQL会根据配置文件,限制Server接受数据包的大小,
图中(16500100 > 4194304)就是具体问题点,4194304 B = 4MB,所以是这个值小了。
解决:
这个参数为 max_allowed_packet ,在 ini 配置文件中设置一下:
max_allowed_packet = 20M
重启MySQL,然后再次运行:
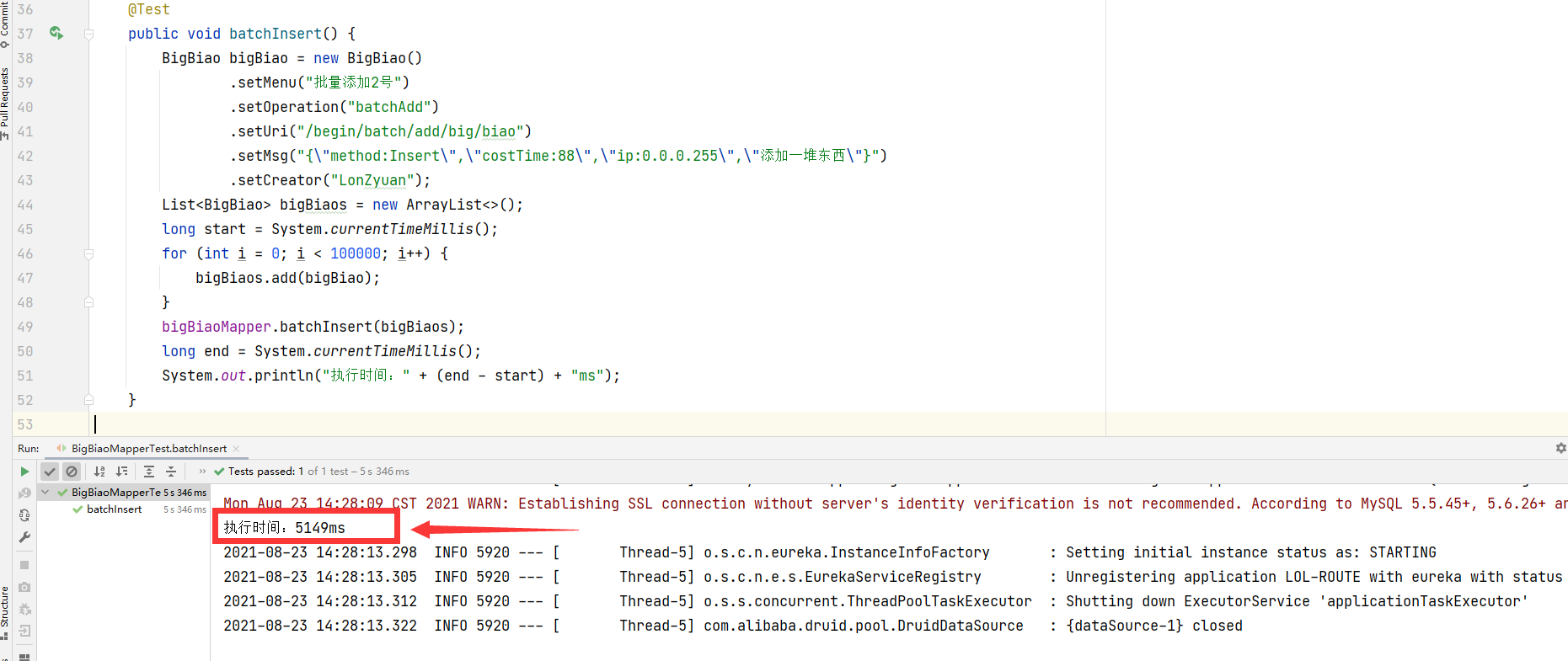
10w条数据插入成功了
这里可能有小伙伴想问那我直接插1000w条进去,那就会发生OOM问题:
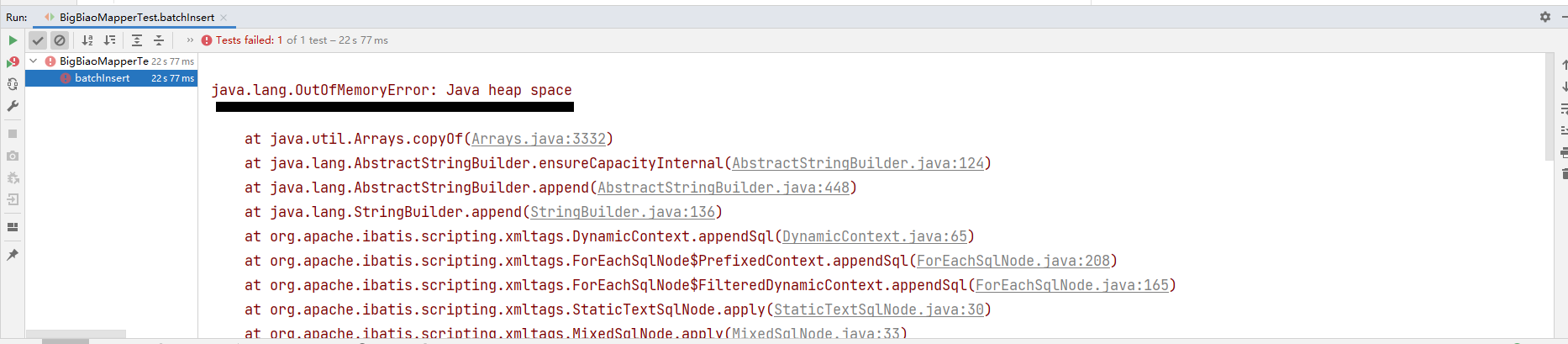
这个问题后续在做探讨。