TPU的目标--快速运行神经网络的推理环节
运行受过训练的神经网络以使用标签对数据进行分类或估计某些缺失值或将来值的过程称为推理。TPU的目标是加速神经网络的推理环节。为了进行推理,神经网络中的每个神经元都进行以下计算:
1、将输入数据(x)乘以权重(w)以表示信号强度
2、添加结果汇总神经元的状态为单精度值
3、应用激活函数(f)(例如ReLU,Sigmoid,tanh或其他)来调节人工神经元的活动。
TPU指令集和编程
TPU指令集
TPU选择了复杂指令集计算机(CISC)样式作为TPU指令集的基础,CISC设计着重于执行高级指令。
TPU定义了十二个专门为神经网络推理设计的高级指令,来控制矩阵乘法器单元(MXU),统一缓冲区(UB)和激活单元(AU)如何进行操作。
| TPU指令 | 功能 |
|---|---|
| Read_Host_Memory | 从内存中读取数据 |
| Read_Weights | 从内存读取权重 |
| MatrixMultiply/Convolve | 将数据和权重相乘或卷积,累加结果 |
| Activate | 应用激活功能 |
| Write_Host_Memory | 将结果写入内存 |
TPU编程
TPU设计封装了神经网络计算的本质,并且可以针对各种神经网络模型进行编程。
为了对其进行编程,TPU创建了一个编译器和软件堆栈,该堆栈将TensorFlow图中的API调用转换为TPU指令。
从TensorFlow到TPU的软件堆栈如下图:

神经网络中的量化
神经网络预测通常不需要使用32位甚至16位数字的浮点计算精度。稍作努力,便可以使用8位整数来计算神经网络预测,并且仍然保持适当的准确性。
量化是一种优化技术,它使用8位整数代替32位甚至16位数字的浮点数 来近似介于预设的最小值和最大值之间的任意值。
Tensorflow中的量化如下图:
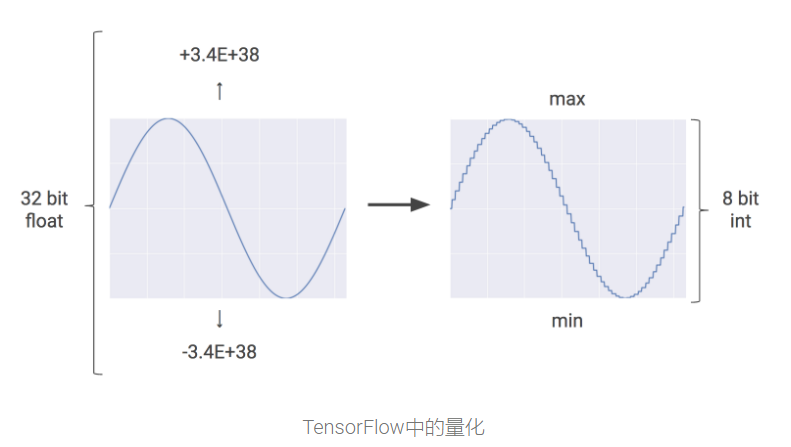
量化是减少神经网络预测成本的强大工具,并且相应减少内存使用也很重要,尤其是对于移动和嵌入式部署。
能够使用整数而不是浮点运算,可以大大减少TPU的硬件占用空间和能耗。一个TPU包含65,536个8位整数乘法器。
TPU的心脏:脉动阵列
矩阵乘法器单元上的并行处理————对于TPU,Google将其矩阵乘法器单元(MXU)设计为矩阵处理器,可以在一个时钟周期内处理数十万次运算(即矩阵运算)。
(CPU为标量处理器,GPU为向量处理器,TPU为矩阵处理器)
为了实现这种大型矩阵处理器,MXU具有与典型的CPU和GPU截然不同的架构,称为脉动阵列。
CPU和GPU经常花费精力来每次操作访问多个寄存器。脉动阵列将多个ALU链接在一起,从而重用读取单个寄存器的结果。
一个输入矩阵乘以权重矩阵的例子如下:
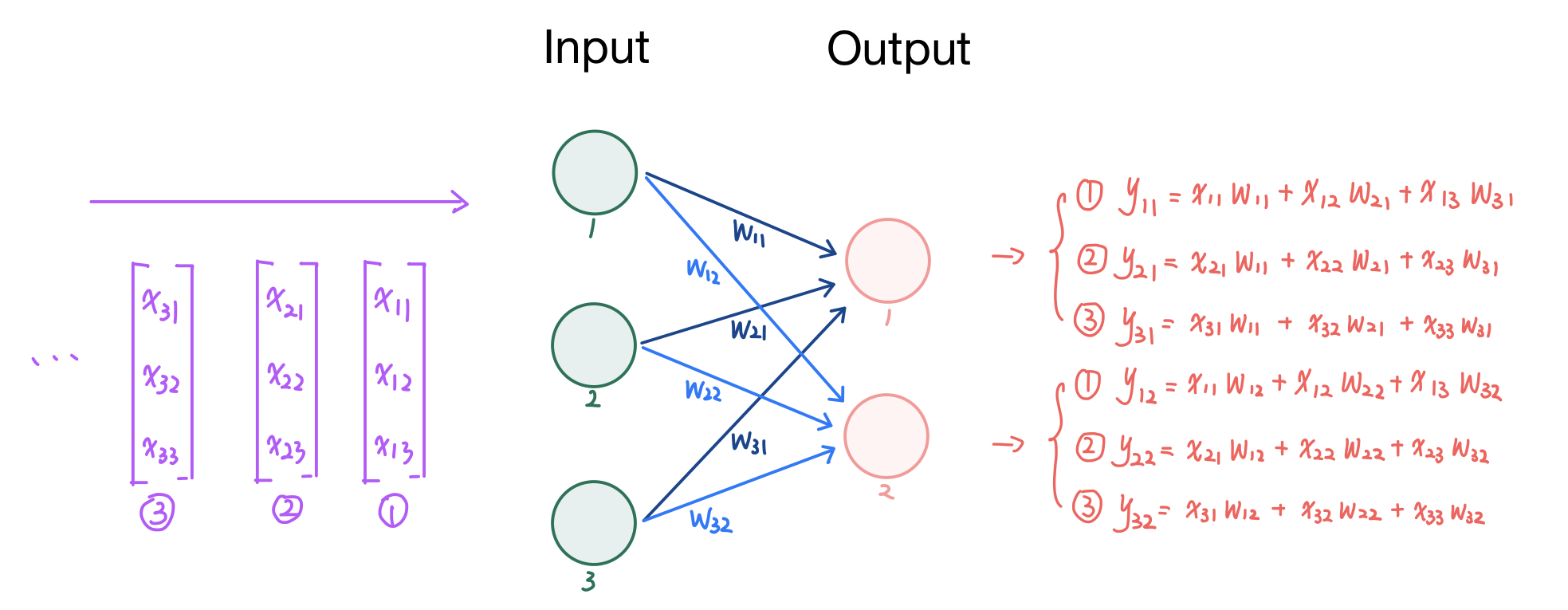
把权重矩阵存在脉动矩阵中,则输入矩阵乘以脉动矩阵的权重矩阵的过程如下:
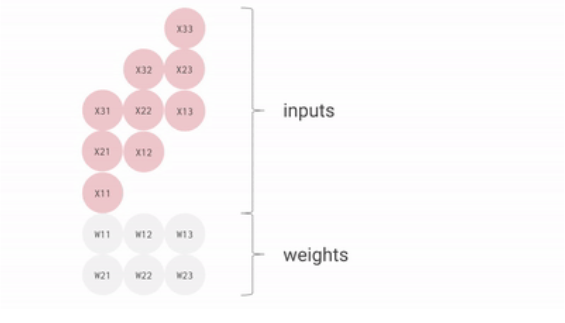
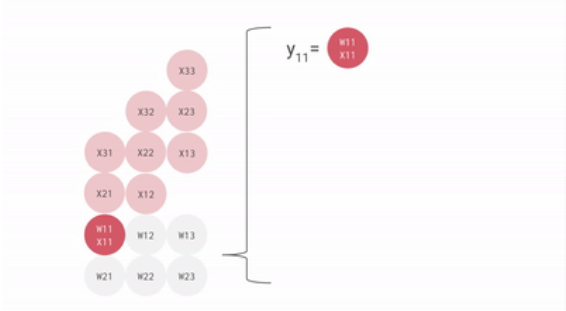
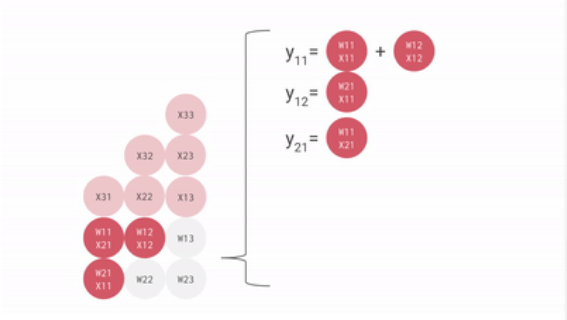
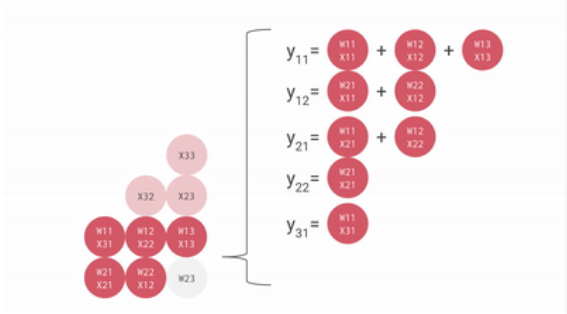
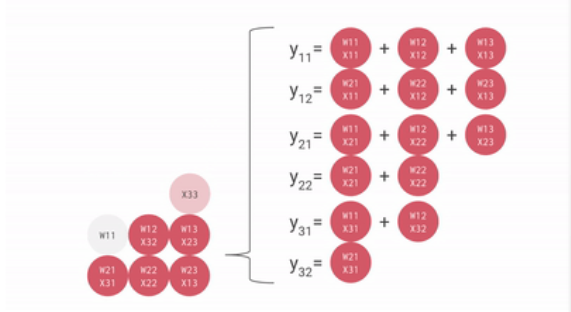
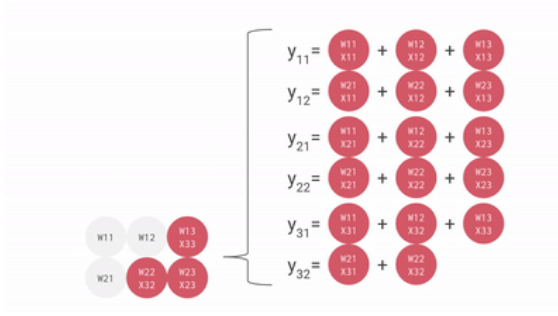
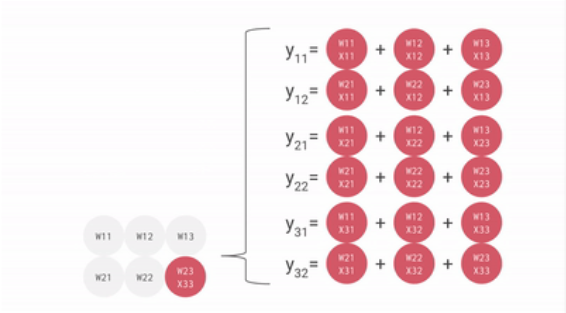
可见,从内存或寄存器中读取的数据,以及ALU计算结果,直接在ALU之间传递,数据纵向传递,计算结果横向传递并进行累加,从而避免了存入以及读取内存的过程。
ALU接收纵向传递来的数据,与权重相乘,相乘结果与横向传递来的数据相加,相乘相加的结果继续横向传递,而纵向数据使用完后继续纵向传递。
实际上,TPU的矩阵乘法单元如下图:
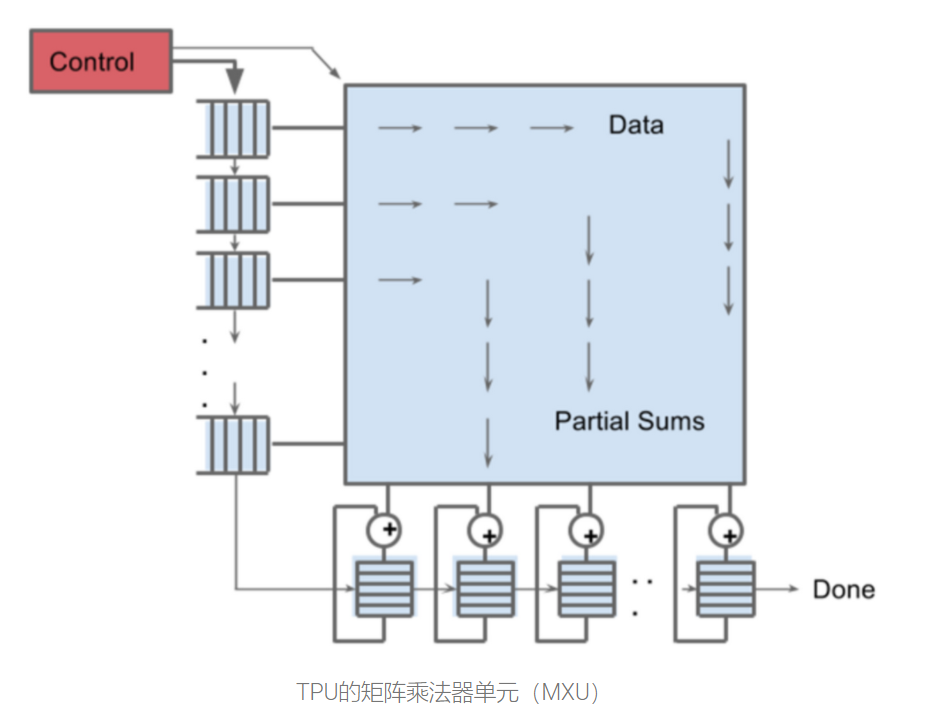
可见,在该矩阵乘法单元中,数据横向从左到右传递,乘法和纵向从上到下传递