作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程
HDFS 功能 分布式文件系统,用来存储海量数据。
工作原理 文件系统都有最小的处理单元,而HDFS的处理单元是一个块。HDFS保存的文件被分成块进行存储。默认块大小为
64MB。HDFS有两种类型的节点:NameNode和DataNode。
NameNode是管理节点,存放文件元数据。也就是存放着文件和数据块的映射表,数据块和数据节点的映射表。通
过NameNode可以找到文件存放的地方,找到存放的数据。DataNode是工作节点,用来存放数据块,也就是文件实
际存储的地方。
工作过程 当客户端向NameNode发送消息以读取元数据时,NameNode将查询其块映射以找到相应的数据节点。然后客户端可
以在相应的数据节点中找到数据块,并将它们拼接成文件。这是读写的过程。
MapReduce 功能 并行处理框架,实现任务分解和调度。
工作原理 map task
程序会根据InputFormat将输入文件分割成splits,每个split会作为一个map task的输入,每个map task会有一
个内存缓冲区,输入数据经过map阶段处理后的中间结果会写入内存缓冲区,并且决定数据写入到哪个
partitioner,当写入的数据到达内存缓冲区的的阀值(默认是0.8),会启动一个线程将内存中的数据溢写入磁
盘,同时不影响map中间结果继续写入缓冲区。在溢写过程中,MapReduce框架会对key进行排序,如果中间
结果比较大,会形成多个 溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件(最少有一个溢
写文件),如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
reduce task
当所有的map task完成后,每个map task会形成一个最终文件,并且该文件按区划分。reduce任务启动之
前,一个map task完成后,就会启动线程来拉取map结果数据到相应的reduce task,不断地合并数据,为
reduce的数据输入做准备,当所有的map tesk完成后,数据也拉取合并完毕后,reduce task 启动,最终将
输出输出结果存入HDFS上。
工作过程 开发人员编写好MapReduce program,将程序打包运行。JobClient向JobTracker申请可用Job,JobTracker返
回JobClient一个可用Job ID。JobClient得到Job ID后,将运行Job所需要的资源拷贝到共享文件系统HDFS中。
资源准备完备后,JobClient向JobTracker提交Job。JobTracker收到提交的Job后初始化Job。初始化完成后,
JobTracker从HDFS中获取输入splits(作业可以该启动多少Mapper任务)。与此同时,TaskTracker不断地向
JobTracker汇报心跳信息,并且返回要执行的任务。TaskTracker得到JobTracker分配(尽量满足数据本地化)的
任务后,向HDFS获取Job资源(若数据是本地的,不需拷贝数据)。 获取资源后,TaskTracker会开启JVM子进程
运行任务。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
2)编写map函数和reduce函数,在本地运行测试通过

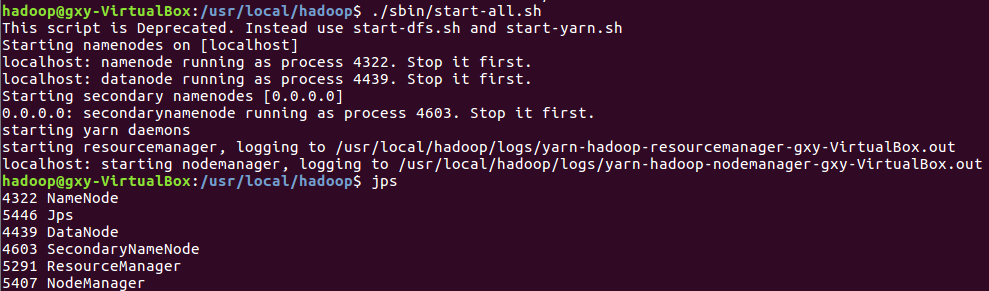
3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
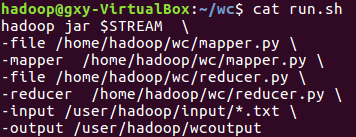
7)source run.sh来执行mapreduce

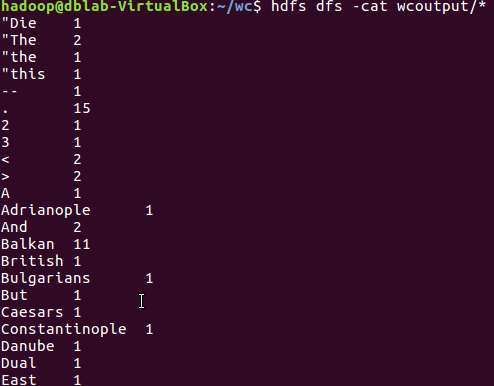
8)查看运行结果