【题目来源】
https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/
【题目内容】

【解题思路】
思路一:遍历(超出时间限制)
- 将数组中的每一个数字和后面的所有数字进行比较,当发现相等时,即为结果。
int findRepeatNumber(int* nums, int numsSize){
// 遍历
for (int i = 0; i < numsSize - 1; i++) {
for (int j = i + 1; j < numsSize; j++) {
if (nums[i] == nums[j]) {
return nums[i];
}
}
}
return 0;
}
思路二:排序 + 遍历(执行用时:92 ms 内存消耗:10.8 MB)
- 排序后能保证重复的数字连续分布,这样遍历时只需要比较当前数字和下一个数字是否相同即可。
int compareNums(const void *a, const void *b)
{
int a1 = *(int*)a;
int b1 = *(int*)b;
return a1 - b1;
}
int findRepeatNumber(int* nums, int numsSize){
// 排序
qsort(nums, numsSize, sizeof(int), compareNums);
// 遍历
for (int i = 0; i < numsSize - 1; i++) {
if (nums[i] == nums[i + 1]) {
return nums[i];
}
}
return 0;
}
思路三:哈希查找(执行用时:40 ms 内存消耗:10.2 MB)
- 创建哈希数组(key:数字,value:出现次数),遍历时先检查当前索引对应的数字是否已经出现,出现则返回结果,否则更新该数字出现次数。
#define NUMS_SIZE 100000
int findRepeatNumber(int* nums, int numsSize){
// 哈希
int numsHash[NUMS_SIZE] = {0};
for (int i = 0; i < numsSize; i++) {
if (numsHash[nums[i]] > 0) {
return nums[i];
}
numsHash[nums[i]]++;
}
return 0;
}
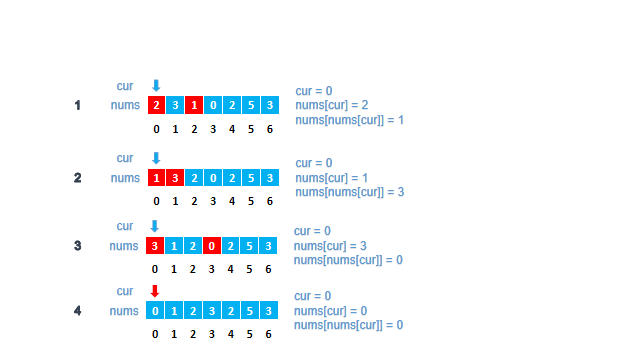
思路四:原地排序(执行用时:36 ms 内存消耗:10.4 MB)
- 借用输入数组,将当前索引对应的数字,替换到对应的数字索引下,保证索引和数字相等。如果出现替换时,索引和数字已经相等时,说明该数字重复,返回结果。相比于思路三的优点是不需要申请额外的空间存放Hash表。执行过程如下图。

int findRepeatNumber(int* nums, int numsSize){
// 原地排序
int cur = 0;
int tmp = 0;
while (cur < numsSize) {
if (nums[nums[cur]] != nums[cur]) {
tmp = nums[cur];
nums[cur] = nums[tmp];
nums[tmp] = tmp;
continue;
}
if (cur == nums[cur]) {
cur++;
continue;
}
return nums[cur];
}
return 0;
}
思路五:二分法(解答错误)
- 根据题目发现答案在[0, n-1]中, left = 0, right = n - 1, mid = (left + right) / 2,先计算整个数组中[left, mid]范围内的数的数量,如果大于(mid - left),说明左侧有重复数字,right = mid,否则,left = mid,继续基于新的left, right二分。该种思路无法解决场景[0, 1, 2, 0, 4, 5, 6, 7, 8, 9]。
int Count(int* nums, int numsSize, int a, int b)
{
int cnt = 0;
int cur = 0;
while (cur < numsSize) {
if (nums[cur] >= a && nums[cur] <= b) {
cnt++;
}
cur++;
}
return cnt;
}
int findRepeatNumber(int* nums, int numsSize){
// 二分法 无法解决场景:[0, 1, 2, 0, 4, 5, 6, 7, 8, 9]
int left = 0;
int right = numsSize - 1;
int mid, count;
while (left < right - 1) {
mid = (left + right) / 2;
count = Count(nums, numsSize, left, mid);
if (count > mid + 1 - left) {
right = mid;
continue;
}
left = mid;
}
if (Count(nums, numsSize, left, left) > 1) {
return left;
}
return right;
}
【学习小结】
数组比Hash性能更好
相比于HashSet,使用数组绝对会有性能的提高,主要表现在如下的两个方面:
哈希表 (HashSet) 底层是使用数组 + 链表或者红黑树组成的,而且它的数组也是用不满的,有加载因子的。所以使用数组来代替哈希表,能节省空间
哈希表在判重的时候需要经过哈希计算,还可能存在哈希冲突的情况,而使用数组则可以直接计算得到 index 的内存位置,所以使用数组访问性能更好。
链接:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/solution/duo-chong-jie-fa-xun-xu-jian-jin-yi-zhi-dao-zui-yo/
调整执行顺序,性能提升
判断场景先执行nums[nums[cur]],再执行nums[cur],触发预取,提高性能。
将满足条件概率更大的条件放到前面,可以避免大量无效判断,提高性能。