工作之余在学习python,笔者主流语言是php,初学抓取了近来一个星期的脉脉职言区的帖子,现将过程记录如下。
脉脉是一款职场社交软件,大家会在职言区,也就是之前的匿名区去吐槽,但是帖子是登录之后才能看,所以第一步需要python模拟登录
模拟登录
首先在网页上登录,打开开发者工具,会看到一个gossip_list连接,这个就是列表的接口了,参数需要如下

是的,右边的参数就是我们获取数据的时候需要的参数了,cookie信息放在header头里模拟浏览器登录信息,把参数拼接好,去访问,能正常返回数据,如下图:
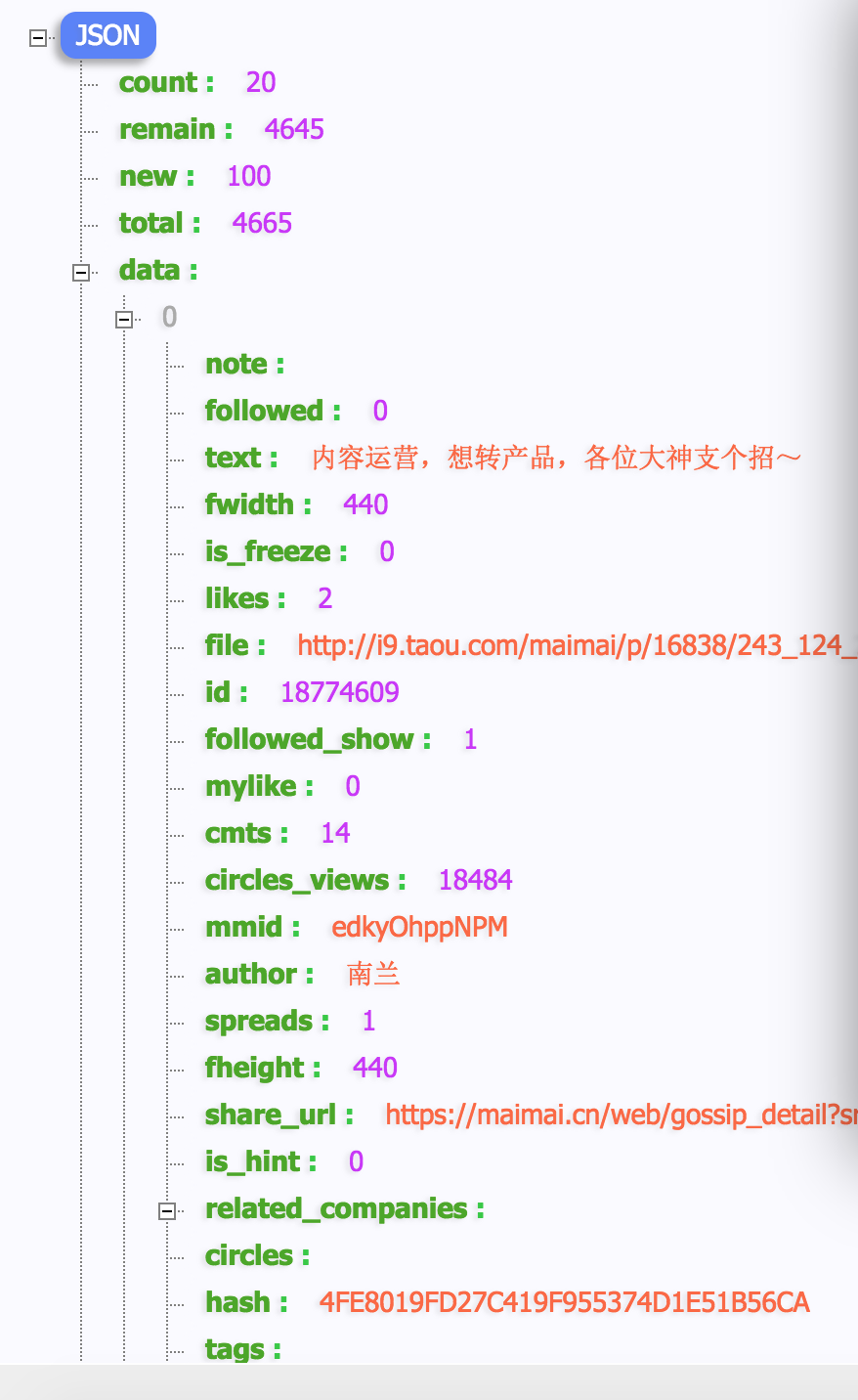
这样就拿到了数据结构了,然后写获取URL的方法,拼接URL,代码如下
def geturl(page): url = 'https://maimai.cn/sdk/web/gossip_list?' params = { 'u':'****', 'channel':'www', 'version':'4.0.0', '_csrf':'*****', 'access_token':'*****', 'uid':'*****', 'token':'*****', 'page':page, 'jsononly':'1' } for item in params: url = url + item + '='+ params[item] + "&" url = url[:-1] return url;
获取了URL之后,根据已经拿到的cookie去拿取数据,代码如下:
def getGossipList(): headers={ 'Accept':'text/html,application/shtml+xml,application/xml', 'Accept-Encoding':'gzip, deflate, br', 'Accept-language':'zh-CN,zh;q=0.9', 'Connection':"keep-alive", 'Host':'maimai.cn', 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36', 'cookie':'******, 'referer':'https://maimai.cn/gossip_list' } i = 0 while (i<200): url = geturl(str(i)); r = requests.get(url,timeout=10,headers=headers) if r=='': return data=r.json()['data'] for item in data: saveData(item) i = i+1
存取数据
把拿到的数据存入sqlite,一般Mac或者Linux都自带,存取下来供后续分析,代码如下:
def saveData(item): related_tags = '' conn = sqlite3.connect('/Users/kumufengchun/maimai.db') cursor = conn.cursor() for tag in related_tags: print(tag) sys.exit() related_tags += tag['name'] + ',' ins = "insert into gossip values(null,?,?,?,?,?,?)" v=(item['text'] if(item.has_key('text')) else '', item['author'] if(item.has_key('author')) else '', item['name'] if(item.has_key('name')) else '', item['avatar'] if(item.has_key('avatar')) else '', related_tags, item['time'] if(item.has_key('time')) else '') cursor.execute(ins, v) conn.commit() conn.close()
数据分析
数据存取下来了,就可以分析了,每个岗位发贴数量,用tableau简单的作图表如下图:

制作云图
想了解大家都在聊啥,用jieba分词先把帖子内容分词,然后在用wordcloud作云图,代码如下:
def makeYuntu(): conn = sqlite3.connect('/Users/kumufengchun/maimai.db') c = conn.cursor() cursor = c.execute("select text from gossip") f = '' for row in cursor: text = jieba.cut(row[0], cut_all=False) f +=" ".join(text) wordcloud = WordCloud( font_path="Deng.ttf", background_color="white", width=1920, height=1080, margin=2).generate_from_text(f); plt.imshow(wordcloud) plt.axis("off") plt.show() wordcloud.to_file('maimai.png') conn.close()
制作的云图如下所示

好了,第一次抓取数据的尝试就到这了。
关于模拟浏览器登录的有很多方法参考文档:https://www.cnblogs.com/chenxiaohan/p/7654667.html
关于sqlite的学习使用:http://www.runoob.com/sqlite/sqlite-python.html
关于python的使用:http://www.runoob.com/python3/python3-if-example.html
关于wordcloud的学习:https://blog.csdn.net/cy776719526/article/details/80171790
https://www.cnblogs.com/jlutiger/p/9176517.html
关于jieba的学习:https://blog.csdn.net/linzch3/article/details/71253541
参考爱奇艺的爬取数据:https://blog.csdn.net/csdnnews/article/details/84781953