Mining时代进化:
CPU挖矿 -> GPU挖矿 -> FPGA挖矿 -> ASIC挖矿
CPU挖矿时代:SENGENERATE
GPU挖矿时代:GETWORK
Miner:
挖矿的程序或者机器统称矿工
挖矿本质:
执行Hash函数的过程,而Hash函数是一个单输入单输出函数,输入数据就是一个区块头
区块头分为六个字段:
nVersion 版本号(固定)
hashPrewBlock 前一个区块hash(固定)
hashMerkleRoot 交易Merkle根(理论上提供2^256种可能)
nTime 时间戳(一般矿工直接使用机器当前时间戳)
nBits 难度(固定)
nNonce 随机数(如BTC提供2^32种可能取值)
挖矿逻辑
打包交易。检索待确认交易内存池,选择包含区块的交易
构造Coinbase。
构造hashMerkleRoot。
填充其他字段,获得完整区块头。
Hash运算,对区块头进行SHA256D运算。
验证结果,如果符合难度,则广播到全网,挖下一个块;不符合难度则根据一定策略改变以上某个字段后再进行Hash运算并验证。
GETWORK
getwork协议代表了GPU挖矿时代,需求主要源于挖矿程序与节点客户端分离,区块链数据与挖矿部件分离。

getwork核心设计思路是:
由节点客户端构造区块,然后将区块头数据交给外部挖矿程序,挖矿程序遍历nNonce进行挖矿,验证合格后交付回给节点客户端,节点客户端验证合格后广播到全网。
合格的区块条件如下:
SHA256D(Blockherder)"挖矿结果"<F(nBits)“难度对应目标值”
都是256位
STRATUM
矿池通过getblocktemplate协议与网络节点交互,以获得区块链的最新信息,通过stratum协议与矿工交互。
为了让之前用getwork协议挖矿的软件也可以连接到矿池挖矿,矿池一般也支持getwork协议,通过阶层挖矿代理机制实现(Stratum mining proxy)。
在矿池刚出现时,显卡挖矿还是主力,getwork用起来非常方便,另外早期的FPGA矿机有些是用getwork实现的,stratum与矿池采用TCP方式通信,数据使用JSON封装格式。
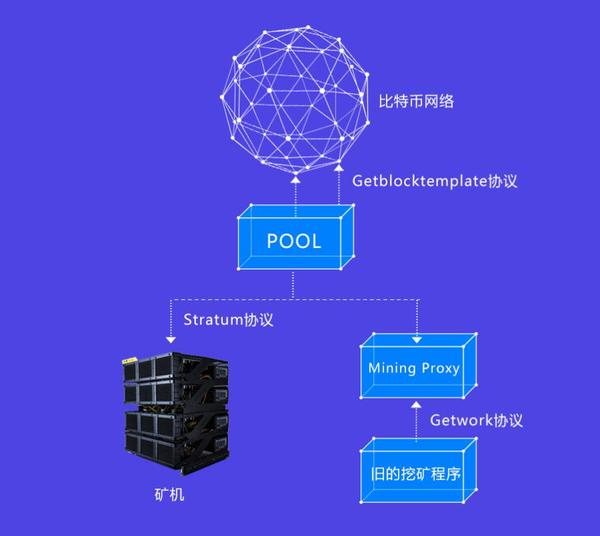
一句话简单的总结:
挖矿实际上就是矿池作为与链上节点交互的一个角色,将new block的json数据格式的Header给到矿工,矿工聚集算力给矿池算出new block需要的正确的Nonce,最后验证通过后矿池拿到出块奖励分发给矿工。
至于多年前diff低的时候的不需要pool的solo mining就不提了....
笔记参考:深度解析挖矿的逻辑与技术实现