本文参考《OpenMP中的任务调度》博文,主要讲的是OpenMP中的schedule子句用法。
一、应用需求
在OpenMP并行计算中,任务调度主要用于并行的for循环。当for循环中每次迭代的计算量相差较大时,如果简单的为每次迭代分配相同的线程,就会导致线程任务不均衡,CPU资源没有被充分利用,影响程序执行性能。例如下面这种情况:
int i, j; int a[100][100] = {0}; for ( i = 0; i < 100; ++i ) { for( j = i; j < 100; ++j ) { a[i][j] = i*j; } }
很显然,如果对外层for循环做并行计算的话,那么i=0与i=99的计算量将相差100倍。为了解决这样的负载严重不均衡的情况,OpenMP提供了几种对for循环并行化的任务调度方案,schedule子句就是负责这样的任务的。
二、Schedule子句用法
schedule子句的使用格式为:
schedule ( type [,size] )
其中,type表示调度类型,可以有四种选择:dynamic、guided、runtime、static,其实runtime是根据环境变量来选择其他三种中的某一种类型;size是可选的,表示连续循环迭代的次数,必须为整数,当type为runtime时候不需要size参数。
2.1 静态调度(Static)
当parallel for编译指导语句没有带schedule子句时,大部分系统中默认采用static调度方式,这种调度方式非常简单。假设有n次循环迭代,t个线程,那么给每个线程静态分配大约n/t次迭代计算。这里为什么说大约分配n/t次呢?因为n/t不一定是整数,因此实际分配的迭代次数可能存在差1的情况,如果指定了size参数的话,那么可能相差一个size。静态调度时可以不使用size参数,也可以使用size参数。
举个例子来说:
#pragma omp parallel for schedule(static) for (int i=0; i<10; ++i) { printf("i=%d, thread_id=%d ", i, omp_get_thread_num()); }
在我的四核笔记本上运行的结果如下(平均每个核心2.5次,结果显示最多相差1):
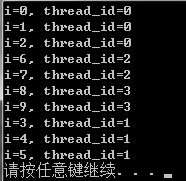
如果添加一个size参数,就指定了连续迭代次数,比如这里指定size为2,将上面的语句修改为:#pragma omp parallel for schedule(static, 2),那么结果很快就变成了:
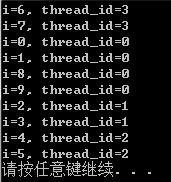
2.2 动态调度(dynamic)
动态调度是动态地将迭代分配到各个线程,动态调度可以使用size参数也可以不使用size参数。不使用size参数时是将迭代逐个地分配到各个线程,使用size参数时,每次分配给线程的迭代次数为指定的size次。
举个例子来看看四核CPU环境下的运行情况,将上面的语句修改为:#pragma omp parallel for schedule(dynamic),结果为:
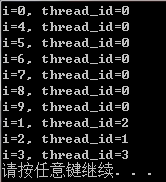
可以看出,这个调度是逐个将任务分配到每一个核心,然后哪个执行完了就接着分配。如果指定size为2,就会每一次为每一个核心连续分配两个任务,结果为:
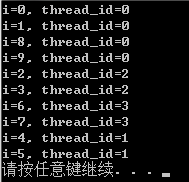
2.3 guided调度(guided)
guided调度是一种采用指导性的启发式自调度方法。开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减。迭代块的大小会按指数级下降到指定的size大小,如果没有指定size参数,那么迭代块大小最小会降到1。
将上面的语句修改为:#pragma omp parallel for schedule(guided),结果为:
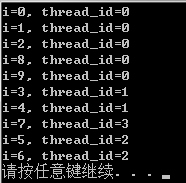
可以看出,采用这种调度方式时,第0、1、2次任务一次性分配给线程0,第3、4次任务分配给线程1,第5、6次任务分配给线程2,第7次任务分配给线程3(分配数衰减为1了),第8、9次任务分配给线程0(这里不是连续两次,而是因为线程0计算较快,重新分配了两个“一次任务”)。
2.4 runtime调度(runtime)
runtime调度不是一种真正意义的调度方式,而是在运行时根据环境变量OMP_SCHEDULE来确定调度类型,最终使用的调度类型仍然是上述三种调度方式中的某种。