Kubernetes 多集群使用场景
随着容器的普及和 Kubernetes 的日渐成熟,企业内部运行多个 Kubernetes 集群已变得颇为常见。概括起来,多个集群的使用场景主要有以下几种。
多集群使用场景
高可用
可以将业务负载分布在多个集群上,使用一个全局的 VIP 或者 DNS 域名将请求发送到对应的后端集群,当一个集群发生故障无法处理请求时,将 VIP 或者DNS记录切换健康的集群。
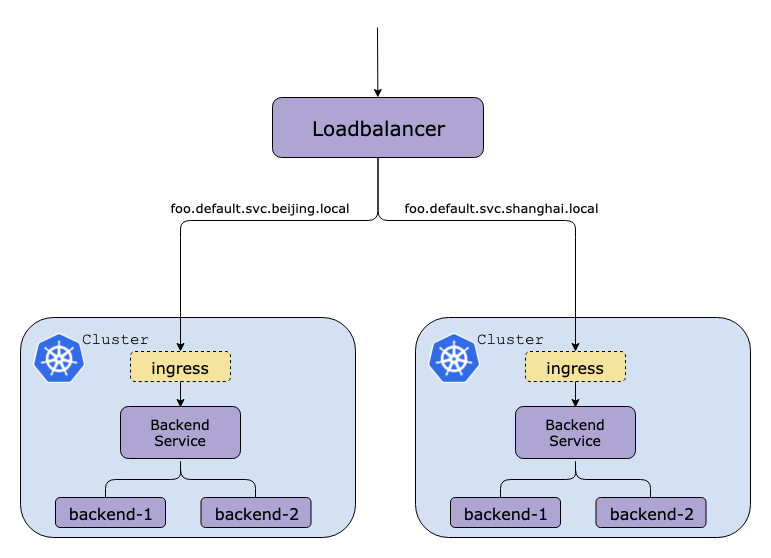
低延迟
在多个区域部署集群,将用户请求转向距离最近的集群处理,以此来最大限度减少网络带来的延迟。举个例子,假如在北京,上海,广州三地部署了三个 Kubernetes 集群,对于广东的用户就将请求转发到所在广州的集群处理,这样可以减少地理距离带来的网络延迟,最大限度地实现各地一致的用户体验。
故障隔离
通常来说,多个小规模的集群比一个大规模的集群更容易隔离故障。当集群发生诸如断电、网络故障、资源不足引起的连锁反应等问题时,使用多个集群可以将故障隔离在特定的集群,不会向其他集群传播。
业务隔离
虽然 Kubernetes 里提供了 namespace 来做应用的隔离,但是这只是逻辑上的隔离,不同 namespace 之间网络互通,而且还是存在资源抢占的问题。要想实现更进一步的隔离需要额外设置诸如网络隔离策略,资源限额等。多集群可以在物理上实现彻底隔离,安全性和可靠性相比使用 namespace 隔离更高。例如企业内部不同部门部署各自独立的集群、使用多个集群来分别部署开发/测试/生成环境等。
避免单一厂商锁定
Kubernetes 已经成容器编排领域的事实标准,在不同云服务商上部署集群避免将鸡蛋都放在一个篮子里,可以随时迁移业务,在不同集群间伸缩。缺点是成本增加,考虑到不同厂商提供的 Kubernetes 服务对应的存储、网络接口有差异,业务迁移也不是轻而易举。
多集群部署
上面说到了多集群的主要使用场景,多集群可以解决很多问题,但是它本身带来的一个问题就是运维复杂性。对于单个集群来说,部署、更新应用都非常简单直白,直接更新集群上的yaml即可。多个集群下,虽然可以挨个集群更新,但如何保证不同集群的应用负载状态一致?如何在不同集群间做服务发现?如何做集群间的负载均衡?社区给出的答案是联邦集群(Federation)。
Federation v1

Federation 方案经历了两个版本,最早的 v1 版本已经废弃。在 v1 版本中,整体架构与 Kubernetes 自身的架构非常相似,在管理的各个集群之前引入了 Federated APIServer 用来接收创建多集群部署的请求,在控制平面的 Federation Controller Manager 负责将对应的负载创建到各个集群上。
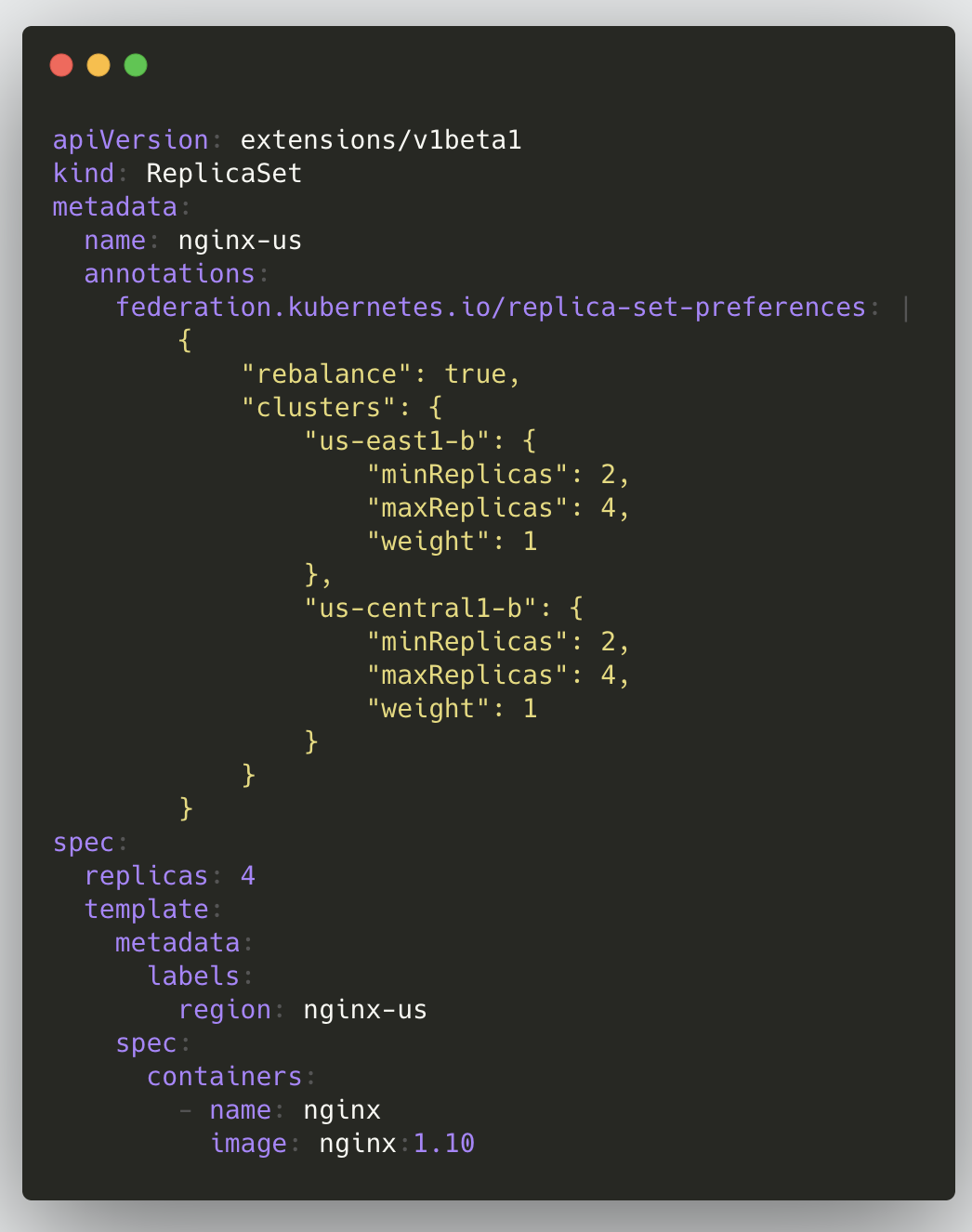
在 API 层面上,联邦资源的调度通过 annotation 实现,最大程度地保持与原有 Kubernetes API 的兼容,这样的好处是可以复用现有的代码,用户已有的部署文件也不需要做太大改动即可迁移过来。但这也是制约 Federation 进一步的发展,无法很好地对 API 进行演进,同时对于每一种联邦资源,需要有对应的 Controller 来实现多集群的调度,早期的 Federation 只支持有限的几种资源类型。
Federation v2
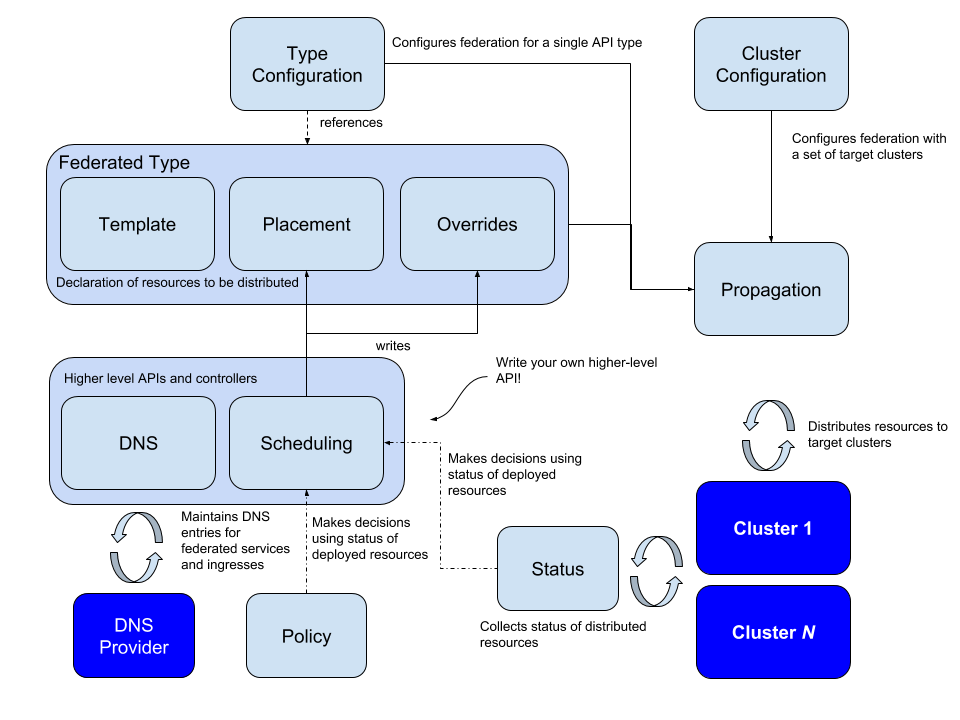
社区在 v1 的基础上发展出了 Federation v2,即 Kubefed。Kubefed 使用 Kubernetes 已经相对成熟的 CRD 定义一套自己的 API 规范,抛弃了之前使用的 annotation 方式。架构上也较之前有很大改变,放弃了之前需要独立部署的 Federated APIServer/etcd,Kubefed 的控制平面采用了流行的 CRD + Controller 的实现方式,可以直接安装在现有的 Kubernetes 集群上,无需额外的部署。
v2定义的资源类型主要包含4种:
Cluster Configuration:定义了 Member Cluster 加入到控制平面时所需要用到的注册信息,包含集群的名称, APIServer 地址以及创建部署时需要用到的凭证。
Type Configuration:定义了 Federation 可以处理的资源对象。每个 Type Configuration 即是一个 CRD 对象,包含下面三个配置项:
- Template Template 包含了要处理的资源对象,如果处理的对象在即将部署的集群上没有相应的定义,则会创建失败。下面例子中的 FederatedDeployment,template 包含了创建 Deployment 对象所需要的全部信息。
- Placement 定义了该资源对象将要创建到的集群名称,可以使用 clusters 和 clusterSelector 两种方式。
- Override 顾名思义,Override 可以根据不同集群覆盖 Template 中的内容,做个性化配置。下面例子中,模板定义的副本数为 1,Override 里覆盖了 gondor 集群的副本数,当部署到 gondor 集群时不再时模板中的 1 副本,而是 4 副本。Override 实现了 jsonpatch 的一个子集,理论上 template 里的所有内容都可以被覆盖。
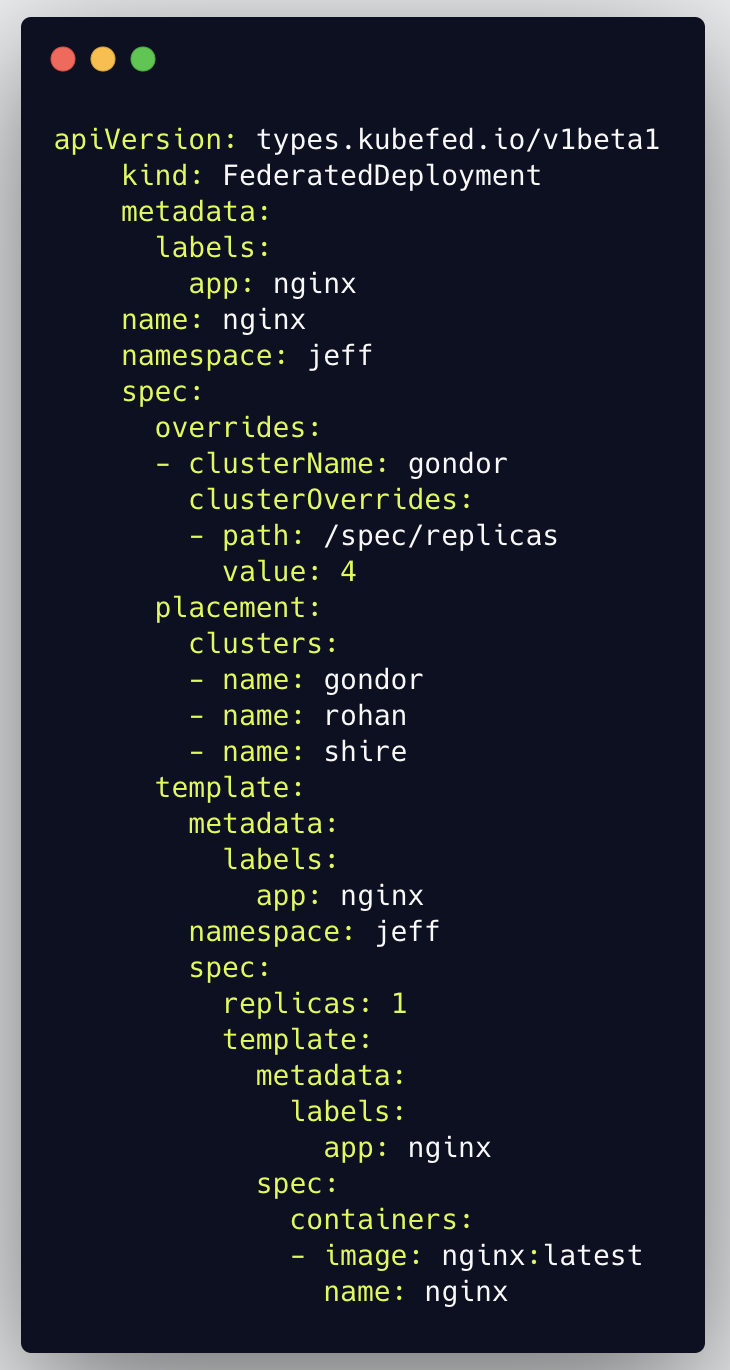
Schedule:主要定义应用在集群间的分布,目前主要涉及到 ReplicaSet 和Deployment。可以通过 Schedule 定义负载在集群中的最大副本和最小副本数,这部分是将之前 v1 中通过 annotation 调度的方式独立出来。
MultiClusterDNS:MultiClusterDNS 实现了多个集群间的服务发现。多集群下的服务发现相比单个集群下要复杂许多,kubefed 里使用了 ServiceDNSRecord、IngressDNSRecord、DNSEndpoint 对象来处理多集群的服务发现,需要配合 DNS 使用。
总体来说,Kubefed 解决了 v1 存在的许多问题,使用 CRD 的方式很大程度地保证了联邦资源的可扩展性,基本上 Kubernetes 所有的资源都可以实现多集群部署,包含用户自定义的 CRD 资源。
Kubefed 目前也存在一些值得关注的问题:
-
单点问题:Kubefed 的控制平面即是 CRD + Controller 的实现方式,虽然 controller 本身可以实现高可用,但如果其运行所在的 Kubernetes 无法使用,则整个控制平面即会失效。这点上在社区中也有讨论,Kubefed 目前使用的是一种 Push reconcile 的方式,当联邦资源创建时,由控制平面上对应的 Controller 将资源对象的发送对应的集群上,至于资源之后怎么处理那是 Member Cluster 自己的事情了,和控制平面无关。所以当 Kubefed 控制平面不可用时,不影响已经存在的应用负载。
-
成熟度:Kubefed 社区不如 Kubernetes 社区活跃,版本迭代的周期较长,目前很多功能仍处在 beta 阶段。
-
过于抽象:Kubefed 使用 Type Configuration 来定义需要管理的资源,不同的 Type Configuration 仅是 Template 不同,好处是对应处理逻辑可以统一,便于快速实现,Kubefed 里 Type Configuration 资源对应的 Controller 都是模板化的。但是缺点也很明显,不能针对特殊的 Type 实现个性化的功能。例如 FederatedDeployment 对象,对于 Kubefed 来说仅需要根据 Template 和 Override 生成对应的 Deployment 对象,然后创建到 Placement 指定的集群,至于 Deployment 在集群上是否生成了对应的 Pod,状态是否正常则不能反映到 FederatedDeployment 上,只能去对应的集群上查看。社区目前也意识到这点,正在积极的解决,已经有对应的提案。
KubeSphere 多集群
上面提到的 Federation 是社区提出的解决多集群部署问题的方案,可以通过将资源联邦化来实现多集群的部署。对于很多企业用户来说,多集群的联合部署其实并不是刚需,更需要的在一处能够同时管理多个集群的资源即可。
我们开源的 KubeSphere v3.0 支持了多集群管理的功能,实现了资源独立管理和联邦部署的功能,支持对集群与应用等不同维度的资源实现监控、日志、事件与审计的查询,以及多渠道的告警通知,以及可以结合 CI/CD 流水线部署应用至多个集群中。
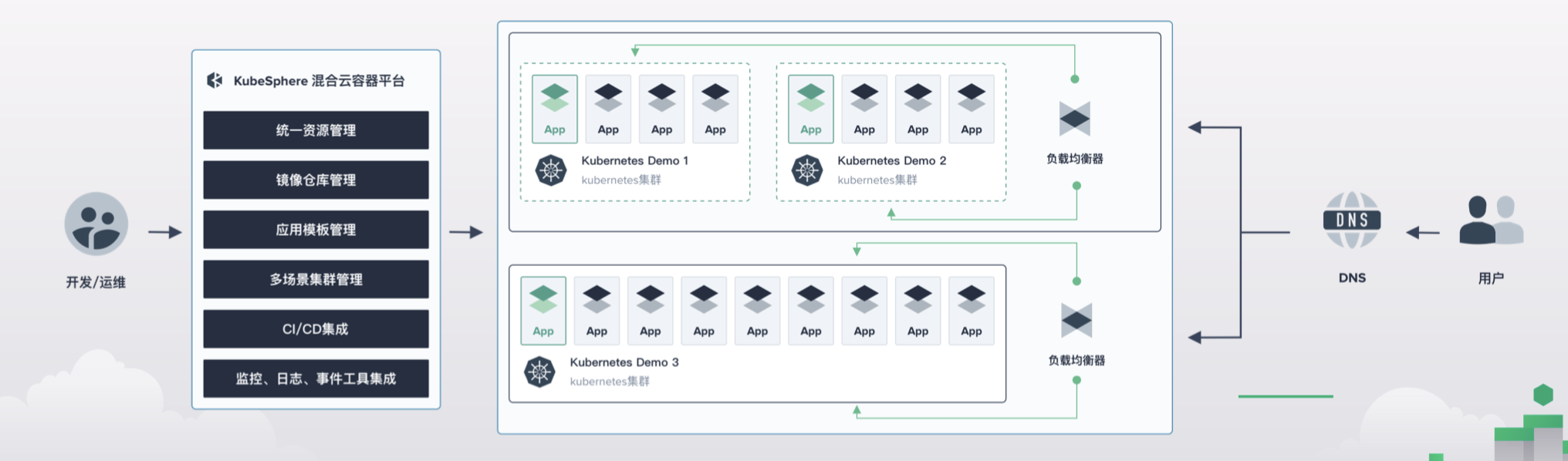
权限管理基于 Kubefed、RBAC 和 Open Policy Agent,多租户的设计主要是为了方便业务部门、开发人员与运维人员在一个统一的管理面板中对资源进行隔离与按需管理。
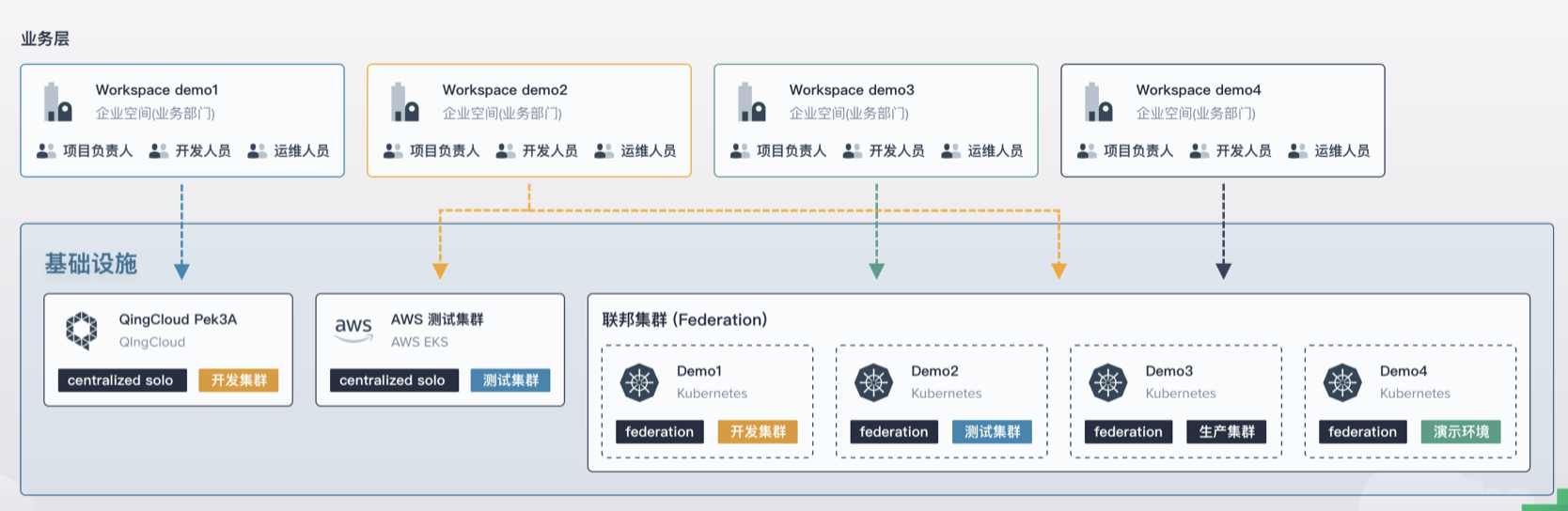
整体架构
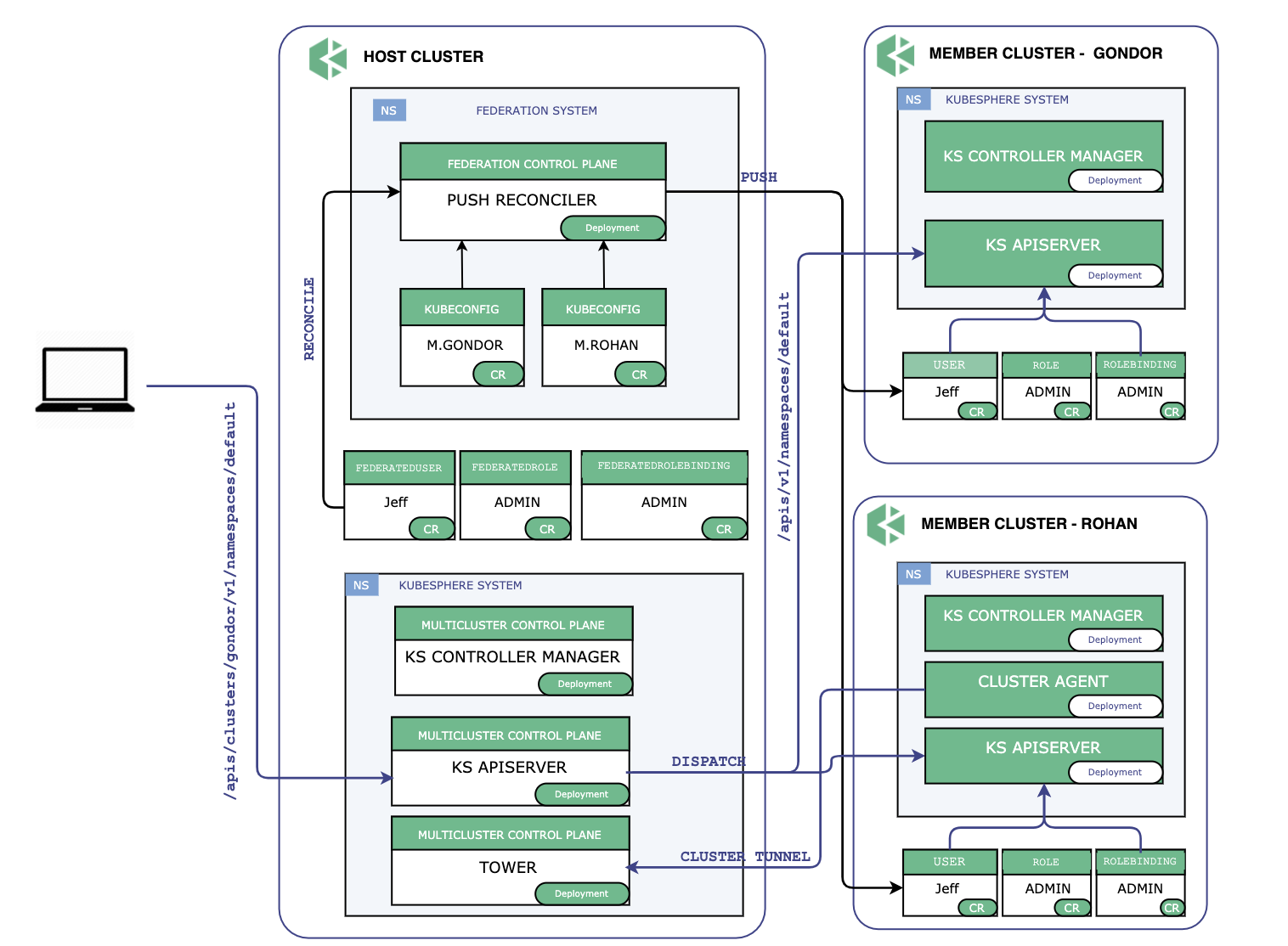
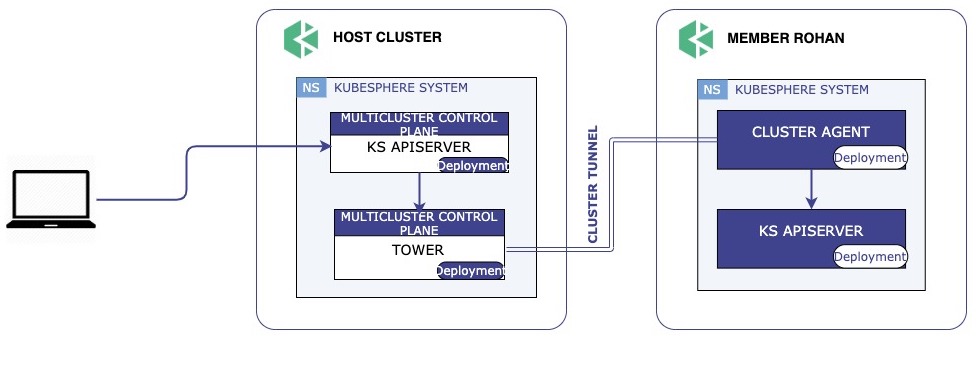
KubeSphere 多集群的整体架构图如图所示,多集群控制平面所在的集群称之为 Host 集群,其管理的集群称为 Member 集群,本质上是一个安装了 KubeSphere 的 Kubernetes 集群,Host 集群需要能够访问 Member 集群的 kube-apiserver,Member 集群之间的网络连通性没有要求。管理集群 Host Cluster 独立于其所管理的成员集群,Member Cluster 并不知道 Host Cluster 存在,这样做的好处是当控制平面发生故障时不会影响到成员集群,已经部署的负载仍然可以正常运行,不会受到影响。
Host 集群同时承担着 API 入口的作用,由 Host Cluster 将对 Member 集群的资源请求转发到 Member 集群,这样做的目的是方便聚合,而且也利于做统一的权限认证。
认证鉴权
从架构图上可以看出,Host 集群负责同步集群间的身份和权限信息,这是通过 Kubefed 的联邦资源实现的,Host 集群上创建 FederatedUser/FederatedRole/FederatedRoleBinding ,Kubefed 会将 User/Role/Rolebinding 推送到 Member 集群。涉及到权限的改动只会应用到 Host 集群,然后再同步到 Member 集群。这样做的目的是为了保持每个 Member 集群的本身的完整性,Member 集群上保存身份和权限数据使得集群本身可以独立的进行鉴权和授权,不依赖 Host 集群。在 KubeSphere 多集群架构中,Host 集群的角色是一个资源的协调者,而不是一个独裁者,尽可能地将权力下放给 Member 集群。
集群连通性
KubeSphere 多集群中只要求 Host 集群能够访问 Member 集群的 Kubernetes APIServer,对于集群层面的网络连通性没有要求。KubeSphere中对于 Host 和 Member 集群的连接提供了两种方式:
直接连接:如果 Member 集群的 kube-apiserver 地址可以在 Host 集群上的任一节点都能连通,那么即可以使用这种直接连接的方式,Member 集群只需提供集群的 kubeconfig 即可。这种方式适用于大多数的公有云 Kubernetes 服务,或者 Host 集群和 Member 集群在同一网络的情形。
代理连接:如果 Member 集群在私有网络中,无法暴露 kube-apiserver 地址, KubeSphere 提供了一种代理的方式,即 Tower。具体来说 Host 集群上会运行一个代理服务,当有新集群需要加入时,Host 集群会生成加入所有的凭证信息,Member 集群上运行 Agent 会去连接 Host 集群的代理服务,连接成功后建立一个反向代理隧道。由于 Member 集群的 kube-apiserver 地址在代理连接下会发生变化,需要 Host 集群为 Member 集群生成一个新的 Kubeconfig 。这样的好处是可以屏蔽底层细节,对于控制平面来说无论是直接连接还是代理方式连接,呈现给控制平面的都是一个可以直接使用的 Kubeconfig。
API 转发
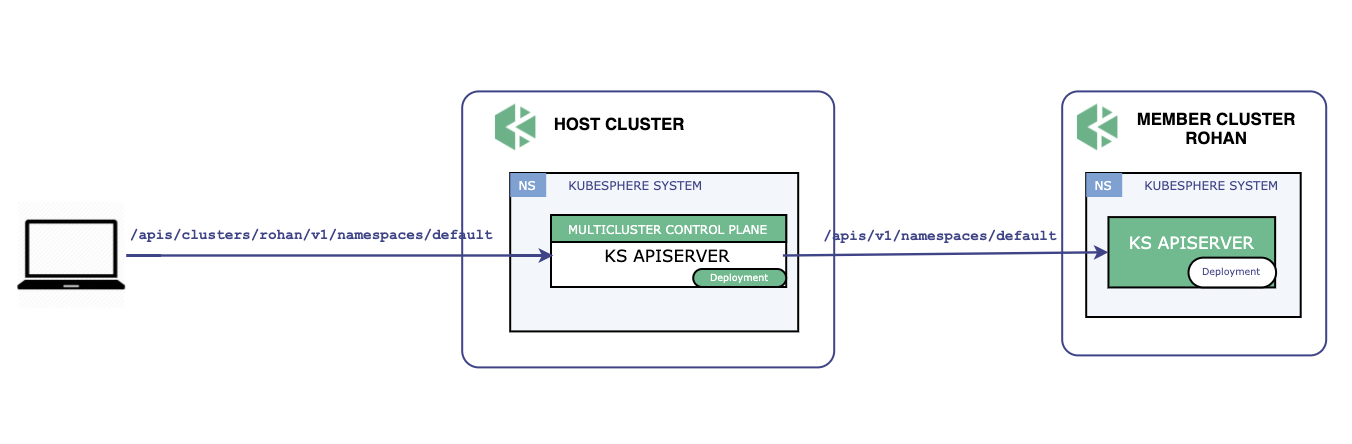
KubeSphere 多集群架构中,Host 集群承担着集群入口的职责,所有的用户请求 API 是直接发往 Host 集群,再由 Host 集群决定请求发往何处。为了尽可能兼容之前的 API,在多集群环境下,API 请求路径中以 /apis/clusters/{cluster} 开头的请求会被转发到 {cluster} 集群,并且去除 /clusters/{cluster},这样的好处对应的集群收到请求和其他的请求并无任何区别,无需做额外的工作。举个例子:

会被转发到名称为 rohan 的集群,并且请求会被处理为:

总结
多集群问题远比想象的要复杂,从社区 Federation 方案就能看出,经历了前后两个版本但是时至今日还未发布正式版。软件领域有句经典的话,No Silver Bullet,Kubefed、KubeSphere 等多集群工具并不能也不可能解决多集群的所有问题,还是需要根据具体业务场景选择合适自己的。相信随着时间的推移,这些工具也会变得更加成熟,届时可以覆盖到更多的使用场景。
Q&A
Q:多集群方案是偏向高可用还是容灾方向?如果是高可用(涉及到跨集群调用),应该如何对微服务进行改造,比如 Spring Cloud?
A:多集群可以用来做高可用,也可以用来做容灾,社区的 Federation 方案是比较通用的方案,比较偏向容灾。高可用一般需要结合具体的业务来看,Federation 更偏向一个多集群部署,至于底层数据如何同步来支持 HA 需要业务本身来做了。
Q:多集群的管理操作界面是自研的吗?如果是,能分享下大致的研发步骤和界面操作图给大家吗?
A:Yes,是自研的。操作界面可以通过下面几个视频了解下:
- https://www.bilibili.com/video/BV1Np4y1S7Lu/
- https://www.bilibili.com/video/BV1SC4y187m9/
- https://www.bilibili.com/video/BV1WT4y177LV/
Q:大佬,你们的业务在Kubernetes中运行期间有碰到一些网络通信问题吗?能分享下问题和大致排查步骤吗,谢谢。
A:网络问题太多了,可以看看这个,能覆盖大部分网络问题场景了。至于太难的,不容易碰到。
Q:联邦层面的 HPA 你们是怎么处理的呢?
A:目前 KubeSphere 多集群中还没有涉及到多集群的 HPA,这需要对底层的监控设施进行一定的改造,在 roadmap 里。
Q:我们之前也有尝试使用联邦来解决多集群下的服务发现问题,但是后面还是放弃了,不敢用,能否分享下多集群服务发现这块的解决方案呢?
A:是的,Kubefed 服务发现相比较单个集群不是那么好用,这块我们也在和社区一起积极推进,遇到问题还是要向社区提 issue 的,帮助社区了解用户场景,也是为开源做贡献 : )
Q:KubeSphere 在多云管理的时候,如何打通公有云和私有云?另外是否会动态调整不同集群里的 Pod 副本数?依据是什么?
A:KubeSphere 管理的集群是一个 KubeSphere 集群,实际是用 Kubernetes 来消除了公有云和私有云底层的异构性,需要解决的仅是网络问题。今天分享提到了 KubeSphere 多集群如何实现和 Member Cluster 的连通性,有一种方式就是适合私有云的,可以了解下。
Q:多集群下的 http 的解决方案是什么,我们在用的单集群是 ingress-nginx -》service,多集群该如何处理?
A:多集群下如果你使用的是 kubefed ,那么可以了解下 multiclusterdns,里面有做多集群 Ingress 的。如果不是的话,只是多个独立的 Kubernetes 集群,那就需要人肉去配置下了。
本文来自 KubeSphere 团队在 DockOne 社区的分享,您可以查看原文。
相关链接:
- http://jsonpatch.com/
- https://github.com/kubernetes-sigs/kubefed/issues/636
- https://github.com/kubernetes-sigs/kubefed/blob/master/pkg/controller/federatedtypeconfig/controller.go
- https://github.com/kubernetes-sigs/kubefed/pull/1237
- https://github.com/kubesphere
- https://github.com/kubesphere/tower
- https://kubesphere.io/
关于 KubeSphere
KubeSphere 是在 Kubernetes 之上构建的容器混合云,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere 已被 Aqara 智能家居、本来生活、新浪、中国人保寿险、华夏银行、浦发硅谷银行、四川航空、国药集团、微众银行、紫金保险、Radore、ZaloPay 等海内外数千家企业采用。KubeSphere 提供了运维友好的向导式操作界面和丰富的企业级功能,包括多云与多集群管理、Kubernetes 资源管理、DevOps (CI/CD)、应用生命周期管理、微服务治理 (Service Mesh)、多租户管理、监控日志、告警通知、存储与网络管理、GPU support 等功能,帮助企业快速构建一个强大和功能丰富的容器云平台。
KubeSphere 官网:https://kubesphere.io/
KubeSphere GitHub:https://github.com/kubesphere/kubesphere

本文由博客一文多发平台 OpenWrite 发布!