各种区块的描述:
很多朋友喜欢听小甲鱼的PE详解,因为他们觉得课堂上老师讲解的都是略略带过,绕得大家云里雾里~刚好小甲鱼文采也没课堂上的教授讲的那么好,只能以比较通俗的话语来给大家描述~
通常,区块中的数据在逻辑上是关联的。PE 文件一般至少都会有两个区块:一个是代码块,另一个是数据块。每一个区块都需要有一个截然不同的名字,这个名字主要是用来表达区块的用途。例如有一个区块叫.rdata,表明他是一个只读区块。注意:区块在映像中是按起始地址(RVA)来排列的,而不是按字母表顺序。
另外,使用区块名字只是人们为了认识和编程的方便,而对操作系统来说这些是无关紧要的。微软给这些区块取了个有特色的名字,但这不是必须的。当编程从PE 文件中读取需要的内容时,如输入表、输出表,不能以区块名字作为参考,正确的方法是按照数据目录表中的字段来进行定位。
下表中的区块名称以及意义:



当然我们在Visual C++ 中也可以自己命名我们的区块,用#pragma 来声明,告诉编译器插入数据到一个区块内,格式如下:
#pragma data_msg( "FC_data" )
大家还记得吧,#为宏处理符号,啥是宏?简单的说就是编译器的时候由编译器直接先进行翻译。或许说按照指定的格式机械替换。嘻嘻,学破解要懂编程呐~
以上语句告诉编译器将数据都放进一个叫“FC_data” 的区块内,而不是默认的.data 区块。区块一般是从OBJ 文件开始,被编译器放置的。链接器的工作就是合并左右OBJ 和库中需要的块,使其成为一个最终合适的区块。链接器会遵循一套相当完整的规则,它会判断哪些区块将被合并以及如何被合并。
合并区块:
链接器的一个有趣特征就是能够合并区块。如果两个区块有相似、一致性的属性,那么它们在链接的时候能被合并成一个单一的区块。这取决于是否开启编译器的 /merge 开关。事实上合并区块有一个好处就是可以节省磁盘的内存空间……注意:我们不应该将.rsrc、.reloc、.pdata 合并到**的区块里。
区块的对齐值:
之前我们简单了解过区块是要对齐的,无论是在内存中存放还是在磁盘中存放~但他们一般的对齐值是不同的。
PE 文件头里边的FileAligment 定义了磁盘区块的对齐值。每一个区块从对齐值的倍数的偏移位置开始存放。而区块的实际代码或数据的大小不一定刚好是这么多,所以在多余的地方一般以00h 来填充,这就是区块间的间隙。
例如,在PE文件中,一个典型的对齐值是200h ,这样,每个区块都将从200h 的倍数的文件偏移位置开始,假设第一个区块在400h 处,长度为90h,那么从文件400h 到490h 为这一区块的内容,而由于文件的对齐值是200h,所以为了使这一区块的长度为FileAlignment 的整数倍,490h 到 600h 这一个区间都会被00h 填充,这段空间称为区块间隙,下一个区块的开始地址为600h 。
PE 文件头里边的SectionAligment 定义了内存中区块的对齐值。PE 文件被映射到内存中时,区块总是至少从一个页边界开始。
一般在X86 系列的CPU 中,页是按4KB(1000h)来排列的;在IA-64 上,是按8KB(2000h)来排列的。所以在X86 系统中,PE文件区块的内存对齐值一般等于 1000h,每个区块按1000h 的倍数在内存中存放。
RVA 和文件偏移的转换
在前边我们探讨过RVA 这个词,但对于初次接触PE 文件的朋友来说,显得尤其陌生和无奈。中国人不喜欢老外的缩写,但总要**着接受……不过,在有了前边知识的铺垫之后,现在来谈这个概念大家伙应该能够得心应手了。起码不用显得那么的费解和无奈~
RVA 是相对虚拟地址(Relative Virtual Address)的缩写,顾名思义,它是一个“相对地址”。PE 文件中的各种数据结构中涉及地址的字段大部分都是以 RVA 表示的,有木有??
更为准确的说,RVA 是当PE 文件被装载到内存中后,某个数据位置相对于文件头的偏移量。举个例子,如果 Windows 装载器将一个PE 文件装入到 00400000h 处的内存中,而某个区块中的某个数据被装入 0040**xh 处,那么这个数据的 RVA 就是(0040**xh - 00400000h )= **xh,反过来说,将 RVA 的值加上文件被装载的基地址,就可以找到数据在内存中的实际地址。
看图说话:
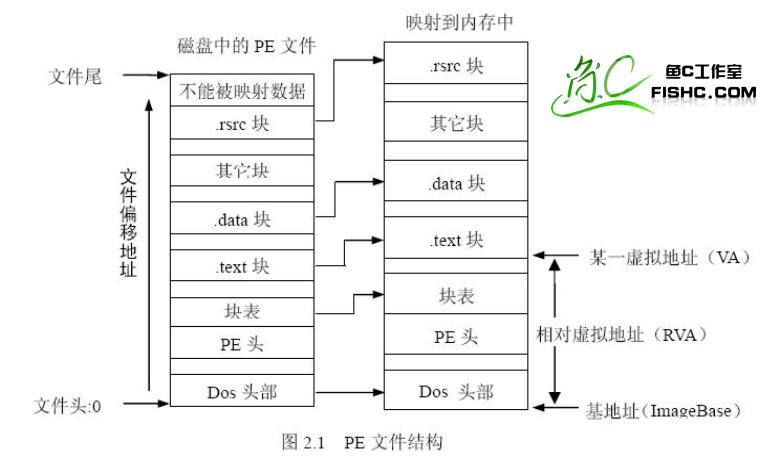
很明显,我们发现,DOS 文件头、PE 文件头和区块表的偏移位置与大小均没有变化。而各个区块映射到内存后,其偏移位置就发生了变化。
RVA 使得文件装入内存后的数据定位变得方便,然而却给我们要定位位于磁盘上的静态PE 文件带来了麻烦。举个例子说话:……由于例子在视频中,这里争取时间我就不写啦,大伙看参考视频演示吧。
如何换算 RVA 和文件偏移呢?
当处理PE 文件时候,任何的 RVA 必须经过到文件偏移的换算,才能用来定位并访问文件中的数据,但换算却无法用一个简单的公式来完成,事实上,唯一可用的方法就是最土最笨的方法:
步骤一:循环扫描区块表得出每个区块在内存中的起始 RVA(根据IMAGE_SECTION_HEADER 中的VirtualAddress 字段),并根据区块的大小(根据IMAGE_SECTION_HEADER 中的SizeOfRawData 字段)算出区块的结束 RVA(两者相加即可),最后判断目标 RVA 是否落在该区块内。
步骤二:通过步骤一定位了目标 RVA 处于具体的某个区块中后,那么用目标 RVA 减去该区块的起始 RVA ,这样就能得到目标 RVA 相对于起始地址的偏移量 RVA2.
步骤三:在区块表中获取该区块在文件中所处的偏移地址(根据IMAGE_SECTION_HEADER 中的PointerToRawData 字段), 将这个偏移值加上步骤二得到的 RVA2 值,就得到了真正的文件偏移地址。
为节省笔墨和时间,以上步骤将在视频中具体演示……
通过上述三个步骤,我们可以写得出程序……
很多朋友喜欢听小甲鱼的PE详解,因为他们觉得课堂上老师讲解的都是略略带过,绕得大家云里雾里~刚好小甲鱼文采也没课堂上的教授讲的那么好,只能以比较通俗的话语来给大家描述~
通常,区块中的数据在逻辑上是关联的。PE 文件一般至少都会有两个区块:一个是代码块,另一个是数据块。每一个区块都需要有一个截然不同的名字,这个名字主要是用来表达区块的用途。例如有一个区块叫.rdata,表明他是一个只读区块。注意:区块在映像中是按起始地址(RVA)来排列的,而不是按字母表顺序。
另外,使用区块名字只是人们为了认识和编程的方便,而对操作系统来说这些是无关紧要的。微软给这些区块取了个有特色的名字,但这不是必须的。当编程从PE 文件中读取需要的内容时,如输入表、输出表,不能以区块名字作为参考,正确的方法是按照数据目录表中的字段来进行定位。
下表中的区块名称以及意义:
当然我们在Visual C++ 中也可以自己命名我们的区块,用#pragma 来声明,告诉编译器插入数据到一个区块内,格式如下:
#pragma data_msg( "FC_data" )
大家还记得吧,#为宏处理符号,啥是宏?简单的说就是编译器的时候由编译器直接先进行翻译。或许说按照指定的格式机械替换。嘻嘻,学破解要懂编程呐~
以上语句告诉编译器将数据都放进一个叫“FC_data” 的区块内,而不是默认的.data 区块。区块一般是从OBJ 文件开始,被编译器放置的。链接器的工作就是合并左右OBJ 和库中需要的块,使其成为一个最终合适的区块。链接器会遵循一套相当完整的规则,它会判断哪些区块将被合并以及如何被合并。
合并区块:
链接器的一个有趣特征就是能够合并区块。如果两个区块有相似、一致性的属性,那么它们在链接的时候能被合并成一个单一的区块。这取决于是否开启编译器的 /merge 开关。事实上合并区块有一个好处就是可以节省磁盘的内存空间……注意:我们不应该将.rsrc、.reloc、.pdata 合并到**的区块里。
区块的对齐值:
之前我们简单了解过区块是要对齐的,无论是在内存中存放还是在磁盘中存放~但他们一般的对齐值是不同的。
PE 文件头里边的FileAligment 定义了磁盘区块的对齐值。每一个区块从对齐值的倍数的偏移位置开始存放。而区块的实际代码或数据的大小不一定刚好是这么多,所以在多余的地方一般以00h 来填充,这就是区块间的间隙。
例如,在PE文件中,一个典型的对齐值是200h ,这样,每个区块都将从200h 的倍数的文件偏移位置开始,假设第一个区块在400h 处,长度为90h,那么从文件400h 到490h 为这一区块的内容,而由于文件的对齐值是200h,所以为了使这一区块的长度为FileAlignment 的整数倍,490h 到 600h 这一个区间都会被00h 填充,这段空间称为区块间隙,下一个区块的开始地址为600h 。
PE 文件头里边的SectionAligment 定义了内存中区块的对齐值。PE 文件被映射到内存中时,区块总是至少从一个页边界开始。
一般在X86 系列的CPU 中,页是按4KB(1000h)来排列的;在IA-64 上,是按8KB(2000h)来排列的。所以在X86 系统中,PE文件区块的内存对齐值一般等于 1000h,每个区块按1000h 的倍数在内存中存放。
RVA 和文件偏移的转换
在前边我们探讨过RVA 这个词,但对于初次接触PE 文件的朋友来说,显得尤其陌生和无奈。中国人不喜欢老外的缩写,但总要**着接受……不过,在有了前边知识的铺垫之后,现在来谈这个概念大家伙应该能够得心应手了。起码不用显得那么的费解和无奈~
RVA 是相对虚拟地址(Relative Virtual Address)的缩写,顾名思义,它是一个“相对地址”。PE 文件中的各种数据结构中涉及地址的字段大部分都是以 RVA 表示的,有木有??
更为准确的说,RVA 是当PE 文件被装载到内存中后,某个数据位置相对于文件头的偏移量。举个例子,如果 Windows 装载器将一个PE 文件装入到 00400000h 处的内存中,而某个区块中的某个数据被装入 0040**xh 处,那么这个数据的 RVA 就是(0040**xh - 00400000h )= **xh,反过来说,将 RVA 的值加上文件被装载的基地址,就可以找到数据在内存中的实际地址。
看图说话:
很明显,我们发现,DOS 文件头、PE 文件头和区块表的偏移位置与大小均没有变化。而各个区块映射到内存后,其偏移位置就发生了变化。
RVA 使得文件装入内存后的数据定位变得方便,然而却给我们要定位位于磁盘上的静态PE 文件带来了麻烦。举个例子说话:……由于例子在视频中,这里争取时间我就不写啦,大伙看参考视频演示吧。
如何换算 RVA 和文件偏移呢?
当处理PE 文件时候,任何的 RVA 必须经过到文件偏移的换算,才能用来定位并访问文件中的数据,但换算却无法用一个简单的公式来完成,事实上,唯一可用的方法就是最土最笨的方法:
步骤一:循环扫描区块表得出每个区块在内存中的起始 RVA(根据IMAGE_SECTION_HEADER 中的VirtualAddress 字段),并根据区块的大小(根据IMAGE_SECTION_HEADER 中的SizeOfRawData 字段)算出区块的结束 RVA(两者相加即可),最后判断目标 RVA 是否落在该区块内。
步骤二:通过步骤一定位了目标 RVA 处于具体的某个区块中后,那么用目标 RVA 减去该区块的起始 RVA ,这样就能得到目标 RVA 相对于起始地址的偏移量 RVA2.
步骤三:在区块表中获取该区块在文件中所处的偏移地址(根据IMAGE_SECTION_HEADER 中的PointerToRawData 字段), 将这个偏移值加上步骤二得到的 RVA2 值,就得到了真正的文件偏移地址。
为节省笔墨和时间,以上步骤将在视频中具体演示……
通过上述三个步骤,我们可以写得出程序……