OA项目中有极大可能性使用到JBPM框架解决流程控制问题,比如请假流程、报销流程等等。
JBPM:JBoss Business Process Management,翻译过来就是业务流程管理。实际上就是一个java 框架。
学习JBPM最重要的就是学习数据库中的18张表,只要熟练掌握了这18张表,学习JBPM就大功告成了。
一、JBPM框架搭建
1.到JBPM官方网站上下载需要的jar包、源代码、文档等等
比较流行的JBPM版本是JBPM4.4,本次使用该版本的JBPM为例。
下载地址:http://sourceforge.net/projects/jbpm/files/jBPM%204/jbpm-4.4/
2.暂时不整合SSH框架,但是实际上JBPM底层使用的是Hibernate,这点是需要特别注意的(不想注意也不行,学习JBPM必须能够熟练操作Hibernate)。
3.下载jbpm4.4之后,解压文件,将/lib文件夹中的所有jar包和根目录下的jbpm.jar核心包都拷贝到/WEB-INF/lib文件夹中。
4.使用到的三种配置文件
(1)jbpm.cfg.xml,配置文件样例:


<?xml version="1.0" encoding="UTF-8"?> <jbpm-configuration> <import resource="jbpm.default.cfg.xml" /> <import resource="jbpm.businesscalendar.cfg.xml" /> <import resource="jbpm.tx.hibernate.cfg.xml" /> <import resource="jbpm.jpdl.cfg.xml" /> <import resource="jbpm.bpmn.cfg.xml" /> <import resource="jbpm.identity.cfg.xml" /> <!-- Job executor is excluded for running the example test cases. --> <!-- To enable timers and messages in production use, this should be included. --> <!-- <import resource="jbpm.jobexecutor.cfg.xml" /> --> </jbpm-configuration>
(2)jbpm.hibernate.cfg.xml,该文件实际上就是hibernate.cfg.xml配置文件,可以将hibernate.cfg.xml配置文件中的内容和该文件整合到一起。配置文件样例:
1 <?xml version="1.0" encoding="utf-8"?> 2 3 <!DOCTYPE hibernate-configuration PUBLIC 4 "-//Hibernate/Hibernate Configuration DTD 3.0//EN" 5 "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> 6 7 <hibernate-configuration> 8 <session-factory> 9 <!-- 10 MySQLInnoDBDialect方式不能自动建表(忽略外键约束?) 11 MySQLDialect方式能够自动建表,但是在手动结束流程实例的时候会报错(外键约束不能删除) 12 使用MySQL5InnoDBDialect解决两方面的难题。 13 --> 14 <property name="dialect"> 15 <!-- org.hibernate.dialect.MySQLDialect --> 16 org.hibernate.dialect.MySQL5InnoDBDialect 17 </property> 18 <property name="connection.url"> 19 jdbc:mysql://localhost:3306/jbpm 20 </property> 21 <property name="connection.username">root</property> 22 <property name="connection.password">5a6f38</property> 23 <property name="connection.driver_class"> 24 com.mysql.jdbc.Driver 25 </property> 26 <property name="myeclipse.connection.profile">mysql</property> 27 <property name="show_sql">true</property> 28 <property name="hbm2ddl.auto">update</property> 29 30 <mapping resource="jbpm.repository.hbm.xml" /> 31 <mapping resource="jbpm.execution.hbm.xml" /> 32 <mapping resource="jbpm.history.hbm.xml" /> 33 <mapping resource="jbpm.task.hbm.xml" /> 34 <mapping resource="jbpm.identity.hbm.xml" /> 35 36 </session-factory> 37 </hibernate-configuration>
我使用的MySQL版本是5.5,不支持使用MySQLInnoDBDialect方言自动建表(5.1以及以下版本可以),使用MySQLDialect方言能够实现自动建表,但是在结束流程实例的时候会报错。
解决这个问题的关键就是使用MySQL5InnoDBDialect,使用该方言就能够实现既能够自动建表,也能够正常结束流程实例了。
(3)logging.properties配置文件,该配置文件是针对log4j的配置文件,使用该配置文件能够精确控制输出日志信息,以方便查看详细的工作流程。
1 handlers= java.util.logging.ConsoleHandler 2 redirect.commons.logging = enabled 3 4 java.util.logging.ConsoleHandler.level = FINEST 5 java.util.logging.ConsoleHandler.formatter = org.jbpm.internal.log.LogFormatter 6 7 org.jbpm.level=FINE 8 # org.jbpm.pvm.internal.tx.level=FINE 9 # org.jbpm.pvm.internal.wire.level=FINE 10 # org.jbpm.pvm.internal.util.level=FINE 11 12 org.hibernate.level=INFO 13 org.hibernate.cfg.SettingsFactory.level=SEVERE 14 org.hibernate.cfg.HbmBinder.level=SEVERE 15 org.hibernate.SQL.level=FINEST 16 org.hibernate.type.level=FINEST 17 # org.hibernate.tool.hbm2ddl.SchemaExport.level=FINEST 18 # org.hibernate.transaction.level=FINEST
这三种配置文件最好都放置到classpath路径下,这样方便程序处理。
5.至此,程序框架已经搭建完毕,下一步就是学习JBPM API了。
二、JBPM插件安装
1.学习JBPM必须首先安装好JBPM插件,这样才能制作流程图以及部署流程。
2.首先到下载好的jbpm4.4项目工程路径下的/install/src/gpd文件夹下找到jbpm-gpd-site.zip文件,然后使用该文件安装好插件
3.安装插件的时候可能会出现的问题:
我使用的版本是MyEclipse10,使用该版本的MyEclipse我没有找到Help0->install software菜单项,解决办法:
http://kuangdaoyizhimei.blog.163.com/blog/static/220557211201510138346395/
4.安装好插件之后在文件夹下右键new->JBPM 4 Process Definition即可,下面一张请假流程示例图
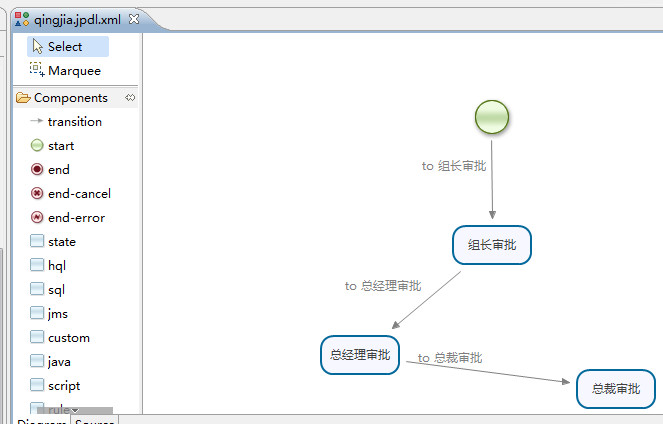
三、流程部署
1.画最简单的一张请假流程图如上图所示(没有申请环节?不要在意这些细节)。
首先,在空白处单击一下,然后在properties视图中修改流程名称,但是Key、Version、Description字段就不要填写了。特别是Description,写上之后就会报错,部署也不会成功,如果想要写Description的话,需要切换到XML视图,在Process根节点下添加<description></description>节点。没有properties视图的解决方法:百度。
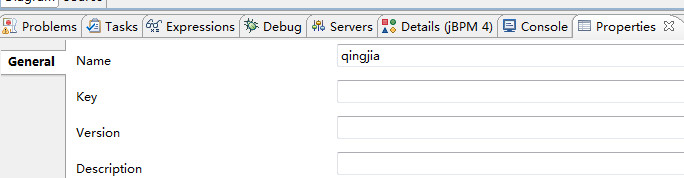
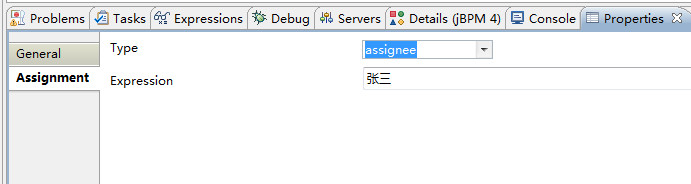
给每个任务节点添加执行人的方法:单击任务节点,在properties视图中修改
2.添加完成之后一旦ctrl+s保存,就会生成一张.png图片,在查看流程图的时候一定会使用到该图片。
3.三种流程部署的方法
(1)classpath的方式部署
ProcessEngine processEngine=Configuration.getProcessEngine(); RepositoryService repositoryService=processEngine.getRepositoryService(); NewDeployment newDeployment = repositoryService.createDeployment(); newDeployment = newDeployment.addResourceFromClasspath("qingjia.jpdl.xml"); newDeployment = newDeployment.addResourceFromClasspath("qingjia.png"); String deploymentId=newDeployment.deploy(); System.out.println(deploymentId);
(2)InputStream的方式部署(比(1)方式还麻烦)
InputStream xml=this.getClass().getClassLoader().getResourceAsStream("qingjia.jpdl.xml"); InputStream png=this.getClass().getClassLoader().getResourceAsStream("qingjia.png"); Configuration.getProcessEngine() .getRepositoryService() .createDeployment() .addResourceFromInputStream("qingjia.jpdl.xml", xml) .addResourceFromInputStream("qingjia.png", png) .deploy();
(3)ZipInputStream的方式部署(最简单的方式,使用该种凡是需要将name.jpdl.xml和name.png打包成zip文件)
InputStream is=this.getClass().getClassLoader().getResourceAsStream("qingjia.zip"); ZipInputStream zipInputStream = new ZipInputStream(is); Configuration.getProcessEngine() .getRepositoryService() .createDeployment() .addResourcesFromZipInputStream(zipInputStream) .deploy();
4.流程部署之后,会自动生成18张表

流程部署影响到的表有:jbpm4_deployment、jbpm4_deployprop、jbpm4_lob、jbpm4_property四张表
(1)jbpm4_deployment,每部署一个流程,该表都会添加一行数据,类似于流程定义一样,但实际上是不同流程定义的不同版本。

DBID_代表主键,没有什么特别的含义,起到唯一标识的作用。需要注意的只有这一个字段,标志了流程定义的ID。
注意,同一种流程可能会有不通过的版本,每一个版本都会在这张表中有相对应的一行记录。
(2)jbpm4_deployprop,流程部署表,每部署一次,都会在这张表中添加四行新数据
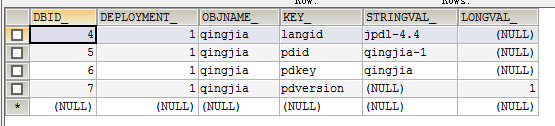
同样的DBID_也是主键,没有特别的含义,只是起到标识作用。
DEPLOYMENT_是引用了jbpm4_deployment表DBID_的外键,这里都是1,表示是1这种类型的流程部署
OBJNAME_是流程部署的名字,一般和KEY_字段的pdkey字段相同,除非特别的做了定义。
KEY_,该字段是最重要的一个字段,四行数据的区分正是由该字段决定的。
* langid:流程定义语言字段,这里是jpdl-4.4表示使用的是jpdl-4.4版本的流程定义语言。
* pdid:流程部署标识ID,标识着本次部署,这是非常重要的字段。
* pdkey:流程定义标识ID,这里是qingjia,表示该字符串唯一标识了该种流程,实际上就是流程定义的名字。每一次新的部署中该值都会不同。
* pdversion:流程部署版本。
(3)容易混淆的事项说明
这张表是18张表中最核心的表之一。KEY_字段中的各个属性值之间的关系:
每一次新的部署都会生成一个唯一的pdkey,version的值初始化成1,同时pdid的值就变成了pdkey-version,如果下一次不是新的部署,而是有着相同pdkey的部署,则本次部署的version值就会增加,同时pdid的值就会相应的变成pdkey-version形式的值。
综上所述,每一次新的部署都会生成新的pdkey,如果是有相同的pdkey,则视为不同版本的流程定义,则版本号就会相应的增加,pdkey标志着唯一的流程定义,pdid唯一标志了相同流程定义下的不同版本。
(4)jbpm4_lob,该表是存放数据的表,如果部署的时候使用了同时使用了xml配置文件和png图片文件,则这里就会相应的增加两行数据,分别代表着部署的xml配置文件和对应的png图片。
该表每一次部署中都会增加一行或者两行新的数据。必不可少的是XML的配置文件所对应的行。
字段DEPLOYMENT_是引用了jbpm4_deployment表的DBID_字段的外键。
5.流程一旦部署完毕,就意味着至少已经有了一种流程定义极其下的至少一种流程定义版本。
四、流程定义(流程部署)管理
无论是流程部署还是流程查询,有一个核心的接口:ProcessEngine,一切的一切都从该接口出发肯定没错。
1.查询流程部署
(1)查询所有流程部署
List<Deployment> deploymentList=processEngine.getRepositoryService().createDeploymentQuery().list();
查询的表是jbpm4_deployment,通过该查询能够实现查找所有流程定义(不同类型流程定义的不同版本),使用Deployment接口的getId可以得到该流程定义的标识ID。注意getRepositoryService()方法。
(2)根据部署id查询部署,该id是jbpm4_deployment的PDID_字段的值
Deployment deployment=processEngine .getRepositoryService() .createDeploymentQuery() .deploymentId("1") .uniqueResult();
2.查询流程定义
(1)查询所有流程定义
List<ProcessDefinition> processDefinitionlist=
processEngine.getRepositoryService()
.createProcessDefinitionQuery()
.list();
(2)根据部署id查询流程定义
ProcessDefinition processDefinition=processEngine.getRepositoryService() .createProcessDefinitionQuery() .deploymentId("1") .uniqueResult();
3.查询流程定义和查询流程部署之间的区别
一个流程定义可以有多个流程部署,但是一个流程部署只能属于一个流程定义,流程定义和流程部署之间是一对多的关系。
在jbpm4_deployprop表中的KEY_字段的pdkey值唯一的标识了一种流程定义,查询流程定义查询的就是jbpm4_deployprop表。
4.根据pdkey查询流程定义
List<ProcessDefinition> processDefinitions=processEngine.getRepositoryService() .createProcessDefinitionQuery() .processDefinitionKey("qingjia") .list();
能够想象的出,如果一种流程定义部署了多次,那么通过pdkey查询出来的流程定义一定是多种流程定义。
5.流程定义和流程部署之间的关系
流程定义实际上就是流程类型+版本号,每一种流程定义都对应着一次流程部署。部署的过程也就是定义的过程。
6.删除流程部署
processEngine.getRepositoryService().deleteDeploymentCascade("20001");
删除流程部署的时候需要提供一个部署id,该id实际上就是jbpm4_deployment表中的DBID_字段的值。
* 疑问:有没有删除流程定义的方法?实际上删除流程部署的同时,也就是删除了流程定义了,所以只需要提供一种方法就行了。这是个人理解。
7.获取流程图的方法,每一种流程定义(流程部署)都会有相应的流程图,怎么获取该流程图呢?
processEngine.getRepositoryService().getResourceAsStream(deploymentId, resourceName);
五、流程实例-任务
任务节点是流程图中最重要的一种节点类型,它代表了一种需要处理的任务。它有节点名称、处理人的属性。
实际上对任务的执行动作是推动流程前进的动力。
1.启动流程实例
(1)根据pdid启动流程实例:根据pdid启动流程实例实际上就是指定了一种类型(具体到版本)的流程定义,如qingjia-1,指的是qingjia流程定义的第一种版本的定义。
ProcessInstance pi=processEngine.getExecutionService()
.startProcessInstanceById("qingjia-1");
(2)根据pdkey启动流程实例:根据pdkey启动流程实例并不会具体到版本,所以默认采用了最高版本的流程定义,如存在qingjia-1、qingjia-2两种流程定义,那么使用qingjia的pdkey启动流程的时候,就会采用qingjia-2的流程定义。
ProcessInstance pi=processEngine.getExecutionService()
.startProcessInstanceByKey("qingjia");
2.完成任务:完成任务需要提供任务的编号,即id属性值
processEngine.getTaskService().completeTask("30002");
3.查询所有的流程实例
List<ProcessInstance> processInstanceList=processEngine.getExecutionService() .createProcessInstanceQuery()//后面可以接上多个过滤条件,如piid,pdid,pdkey .list();
注意,一种流程定义可以有多个流程实例。如一个请假流程可以同时又多个流程实例在运行,如张三在请假对应一个流程实例,李四请假也对应一个流程实例,两个流程实例可以对应一个流程定义。
4.查询当前正在执行的所有任务
List<Task> taskList=processEngine
.getTaskService()
.createTaskQuery()
.list();
5.多条件查询任务
List<Task> taskList=processEngine .getTaskService() .createTaskQuery() // .assignee("张三") //根据执行人查询任务 // .processDefinitionId("qingjia-3") //根据pdid查询任务,可以有一个或者多个 // .processInstanceId("qingjia.40001") //根据piid查询任务,有唯一的一个或者多个(多个的情况是fork/join的情况) .list();
6.根据任务id查询任务
Task task=processEngine.getTaskService().getTask("50001");
可能会对此产生疑问,为什么不能在5中的代码中直接类似于
List<Task> taskList=processEngine .getTaskService() .createTaskQuery() .taskId("50001") .unique();
的方式查询。这是jbpm4.4版本的一个小瑕疵,但是并没有错,知道就好。
7.查询已经完成的所有任务
List<HistoryTask> historyTaskList=
processEngine
.getHistoryService()
.createHistoryTaskQuery()
.state(HistoryTask.STATE_COMPLETED)
.list();
8.直接结束流程实例,表示拒绝请求
processEngine.getExecutionService()
.endProcessInstance("qingjia.30001", "拒绝请假");
注意,这里数据库方言的设置会影响执行的结果,如果数据库方言设置成为MySQLDialect,则会抛出异常;必须使用MySQLInnoDBDialect数据库方言,mysql5.5极其之上的版本强烈推荐使用MySQL5InnoDBDialect,这样既能够自动建表而且在完成任务或者拒绝任务请求的时候不会报错。
9.怎么判断一个流程实例是否已经结束:根据piid查询流程实例,如果查询到的结果是NULL,则表示流程实例已经结束。
processEngine.getExecutionService().createProcessInstanceQuery().processInstanceId("qingjia.30001").uniqueResult()
六、流程变量
什么是流程变量:流程变量是随着随着流程当中任务的执行和结束而产生的数据。比如领导批准或者不批准的理由等等。
1.流程变量的生命周期
从流程实例开始到流程实例结束,流程变量依附于流程实例。
2.流程变量的保存位置:jbpm4_variable表。表中有几个重要字段
* EXECUTION_:是应用了`jbpm4_execution`表id的外键。
* `TASK_`:是引用了`jbpm4_task`表id的外键
* KEY_:由于保存流程变量的时候必须使用Map,所以该KEY是对应着该Map对象的KEY值。
* 由于可以保存的对象可以任意,所以对象的值的类型也是多种多样。该表的多个字段提供了多种数据类型的保存。
如LONG_VALUE_、STRING_VALUE_等。
3.流程变量放入到流程实例中的时机
(1)启动实例的时候
(2)完成任务的时候
(3)流程实开始之后,结束之前
4.启动流程实例的时候放入流程变量
Person p=new Person(); p.setId(1L); p.setName("person-zhangsan"); Map<String,Person> variables=new HashMap<String,Person>(); variables.put("person", p); processEngine.getExecutionService() .startProcessInstanceById("qingjia-1", variables);
运行完成该段代码之后,查看表中的数据

特别一个字段CONVERTER_,该字段中的值是ser-bytes,为什么是该值呢,实际上该值是seriable-bytes,在上面的程序中,保存的值是Person对象,在保存到数据库的时候,会将该对象序列化成二进制数据(瞧,这名字起得多好~)。
5.完成任务的时候放入流程变量
Map<String,Object> variables=new HashMap<String,Object>(); variables.put("请假人", "小张"); variables.put("请假天数", 4); processEngine.getTaskService() .setVariables("30001", variables); processEngine.getTaskService() // .completeTask("30001",variables);//提供了该API,但是并不能使用,结结实实的一个bug .completeTask("30001");
这里,很明显的和启动流程实例的时候放入流程变量的方法不同,是先放入流程变量,后完成任务,为什么不完成任务的同时放入流程变量呢(使用completeTask方法同时完成任务和将流程变量放入流程实例),实际上completeTask方法有一个重载方法,completeTask(taskId,variables),本来根据官方提供的API解释可以使用该方法类完成任务的同时将流程变量放入到流程实例中,然而实际上调用该方法的时候就会报错。必须在完成方法之前先将流程变量放入到流程实例中。这实际上是JBPM4.4中的一个BUG。
6.直接放入到流程实例中,不管是什么阶段(只要流程实例没有结束)
processEngine.getExecutionService()
.setVariable("qingjia.10001","请假理由","踢足球");
7.获取流程变量的方法
(1)根据taskId获取流程变量,使用该方法获取到的流程变量是所有的流程变量;另外需要注意,在使用该种方法获取流程变量的时候必须保证该任务在任务表中
Set<String> variableNames=processEngine.getTaskService() .getVariableNames("40003"); for(String variableName:variableNames){ Object obj=processEngine.getTaskService().getVariable("40003", variableName); if(obj instanceof Person){ Person person=(Person) obj; System.out.println(variableName+":"+person.getName()); }else{ System.out.println(variableName+":"+obj); } }
(2)根据流程实例获取流程变量,个人比较偏向使用这种方法,只要流程实例不结束,都可以根据该方法获取流程实例。
Set<String> variableNames=processEngine.getExecutionService() .getVariableNames("qingjia.10001"); for(String variableName:variableNames){ Object obj=processEngine.getTaskService().getVariable("40003", variableName); if(obj instanceof Person){ Person person=(Person) obj; System.out.println(variableName+":"+person.getName()); }else{ System.out.println(variableName+":"+obj); } }
七、任务动态赋值执行人
之前的示例中,无论是申请人还是执行审批的人,都是固定的,这是不符合实际的。比如申请人,申请人如果固定了,则表示只能一个人发起申请。必须有一种方法能够动态赋值申请人和审批人。
1.使用标签指定给执行人赋值的动态方法
这时候,不需要给任务执行人赋值。
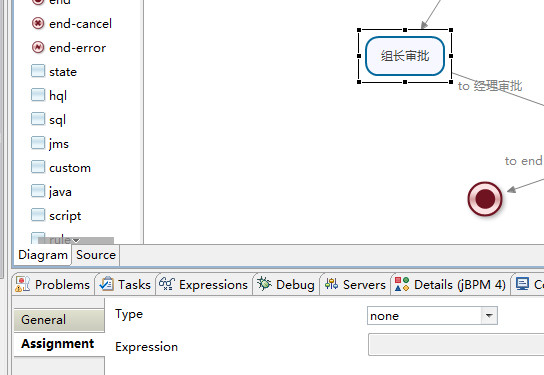
切换到XML模式,在相应的任务中添加下面的数据,如图所示:

根据标签中的内容,需要在指定的位置新建类,该类必须实现AssignmentHandler接口。
1 import org.jbpm.api.model.OpenExecution; 2 import org.jbpm.api.task.Assignable; 3 import org.jbpm.api.task.AssignmentHandler; 4 5 public class MyAssignmentHandler implements AssignmentHandler{ 6 private static final long serialVersionUID = 4278893247283956881L; 7 8 @Override 9 public void assign(Assignable assignable, OpenExecution execution) 10 throws Exception { 11 String assignableId=execution.getVariable("组长").toString(); 12 assignable.setAssignee(assignableId); 13 } 14 15 }
其中,execution参数提供了获取流程变量的方法;assignable提供了设置执行人的方法。
比如在启动流程实例的时候:
Map<String,String> variables=new HashMap<String,String>(); variables.put("组长", "王二麻子"); //通过MyAssignmentHandler类获取到参数并赋值给组长执行人 processEngine.getExecutionService() .startProcessInstanceById("dynamictAssignment-3", variables);
很明显,使用这种方法和之前设置流程变量到流程实例中的方法是相同的。
2.使用使用EL表达式动态赋值任务执行人。
使用方法:#{name}

使用方法:
Map<String,String> variables=new HashMap<String,String>(); variables.put("jingli", "王二麻子他哥"); processEngine.getTaskService().setVariables("100003", variables); processEngine.getTaskService() .completeTask("100003");
这个方法和上面的方法有什么不同之处呢?
这里使用的是TaskService(任务Service),而上面使用的是ExecutionService(流程实例Service),应用场景完全不相同;
另外,这个方法本来可以在完成任务的时候同时加入流程变量,但是会出错,这是bug不提。
八、流程图中的其它概念
1.组任务
一个任务可能有多个候选人,但是完成任务的人只有一个,这样的任务就是组任务。以电脑维修为例。
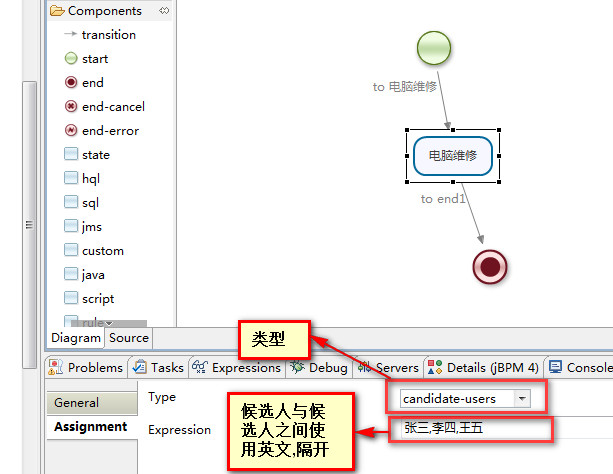
上图所示,完成上图之后,就在流程图上实现了组任务所需要做的事情。
部署完成流程图之后:
(1)根据任务ID查询候选人
List<Participation> participations=processEngine.getTaskService() .getTaskParticipations("10002"); System.out.println(participations.size()); for(Participation participation:participations){ System.out.println(participation.getUserId()); }
(2)根据候选人查询任务
List<Task> tasks=processEngine.getTaskService() .findGroupTasks("张三"); for(Task task:tasks){ System.out.println(task.getName()); }
(3)使用takeTask方法接收任务
processEngine.getTaskService()
.takeTask("10002", "张三");
takeTask方法的第一个参数是taskId,第二个参数是候选人,这里值得一提的是,候选人参数不一定真的是候选人,就算不是候选人列表中的也可以赋值到执行人。
这也算的上是JBPM4.4的一个BUG了吧。
2.transition
transition是XML配置文件中的一个标签名称,该标签名称对应着流程图中的一个箭头指向。下面举一个比较复杂的流程图的例子。
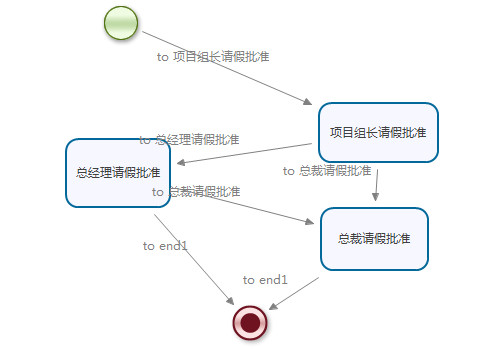
在上图中,在任务节点项目组长请假审批中,下一个走向的节点并不确定,但是可以通过程序控制指定下一个走向的节点。
部署流程之后:
加入想要下一个流向总经理请假批准任务节点,则使用重载方法completeTask(taskId,outcome)指定走向的节点
String outcome="to 总经理请假批准";
processEngine.getTaskService().completeTask("10003", outcome);
outcome的值就是transition标签的name值。
执行完成上面的代码之后,流程的任务节点就流向了总经理请假批准节点。其它以此类推。
3.state节点
state节点和task节点的形状完全相同,但是其作用却不相同。state节点没有执行人。如果流程有分支,则必须手动指定下一个走向的节点,使用的方法并不是之前的completeTask方法了,因为这不是Task节点,而是State节点。
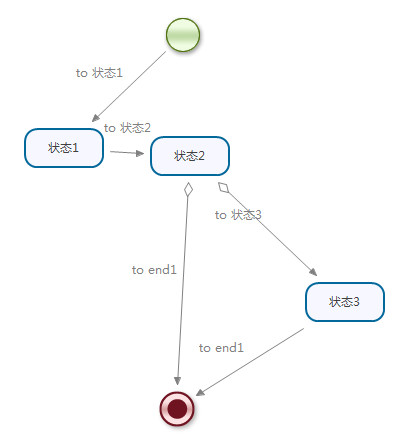
相应的,状态节点并不会保存到Task表中(因为不是任务节点),但是可以在jbpm4_hist_actinst表中找到相关信息。
(1)单分支情况完成节点“任务”
processEngine.getExecutionService()
.signalExecutionById("state.50001");
这里使用signalExecutionById来完成,id在jbpm4_hist_actinst表中查找。
(2)多分支的情况完成节点“任务”
这里使用的套路和之前相同。使用signalExecutionById的重载方法即可。
processEngine.getExecutionService()
.signalExecutionById("state.50001","to 状态3");
4.decision节点
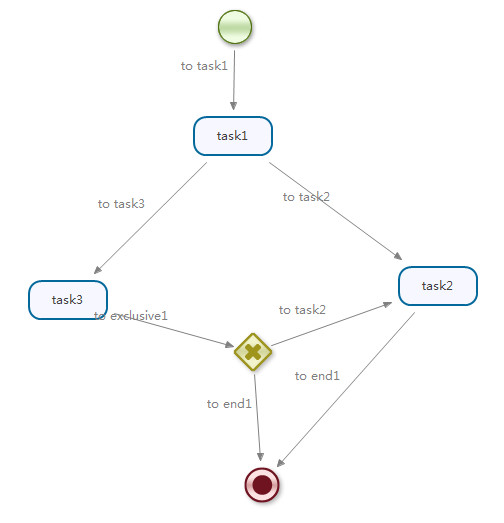
如图所示的X号就是decision节点;它的作用就是根据条件选择将流程走向那一个节点。切换到XML视图
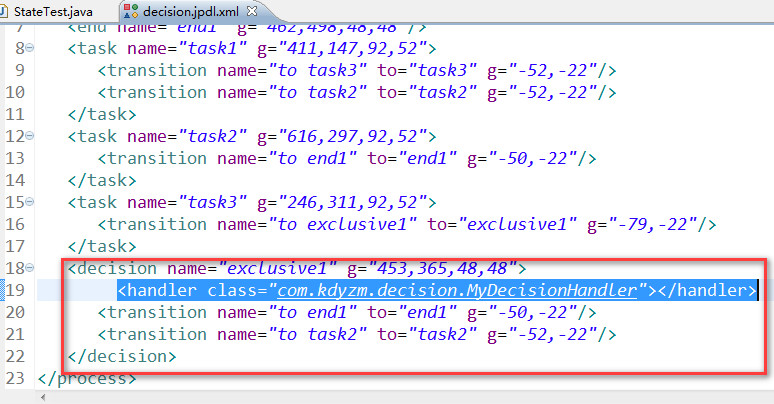
高亮显示的对应的就是decision节点,判断走向那一个节点的逻辑处理就放在了对应的类中。
import org.jbpm.api.jpdl.DecisionHandler; import org.jbpm.api.model.OpenExecution; public class MyDecisionHandler implements DecisionHandler{ private static final long serialVersionUID = 1521490219386641184L; @Override public String decide(OpenExecution execution) { int days=(Integer) execution.getVariable("days"); if(days<=3){ return "to end1"; }else{ return "to task2"; } } }
上面的方法中的逻辑就是:如果请假天数小于等于3天,直接结束流程实例;如果请假天数大于3天,则还需要task2节点批准。
在完成task3的时候使用的代码:
Map<String,Object> variables=new HashMap<String,Object>(); variables.put("days", 4); processEngine.getTaskService() .setVariables("20001", variables); processEngine.getTaskService() .completeTask("20001");
总结:实际上不使用decision节点也能完成任务,但是为了让业务逻辑处理和流程跳转分离,使用该节点是最好的方法。
5.fork/join节点
fork、join结点是两个节点。但是这两个节点是必须相互搭配使用的两个节点。
这两个节点的使用场合是同一个申请同时需要给多个人审批,最后只有多个人都同意之后流程才能走向下一个节点的这种场合,如下图所示:
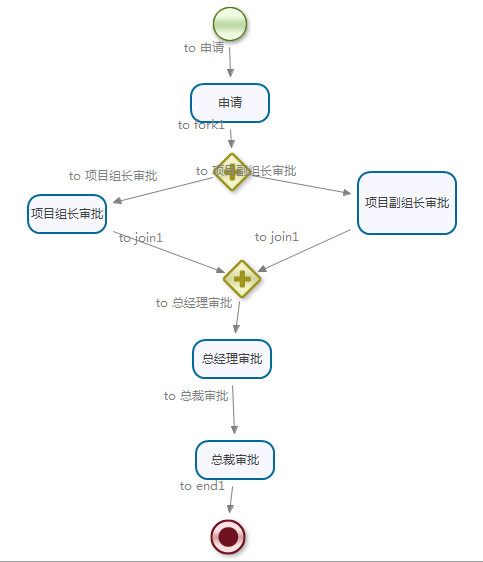
再上图中,在发起申请之后,申请的问价必须同时由项目组长和项目副组长同时同意之后流程实例才能走向总经理审批的流程环节。
使用该方式完全不需要考虑流程的走向问题,流程的走向和处理方式完全和之前的一模一样,不需要考虑fork节点或者join节点的存在,一切都在jbpm的掌控之中。
之后有一个比较完整的项目练习描述了这种情况。
九、Event(事件)
JBPM提供了多种多样的事件,比如流程开始的时候会触发事件、流程结束的时候也会触发时间,进入一个任务节点的时候会触发一个事件,离开一个任务节点的时候也会触发事件等等。
事件的定义方式如下图所示:
1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <process name="event" xmlns="http://jbpm.org/4.4/jpdl"> 4 <!-- 流程级别的开始事件 --> 5 <on event="start"> 6 <event-listener class="com.kdyzm.event.PIStartLisener"></event-listener> 7 </on> 8 <!-- 流程级别的结束事件 --> 9 <on event="end"> 10 <event-listener class="com.kdyzm.event.PIEndListener"></event-listener> 11 </on> 12 <start name="start1" g="533,57,48,48"> 13 <!-- 开始节点的结束事件 --> 14 <on event="end"> 15 <event-listener class="com.kdyzm.event.StartNodEndListener"></event-listener> 16 </on> 17 <transition name="to task1" to="task1" g="-52,-22"/> 18 </start> 19 <end name="end1" g="534,381,48,48"> 20 <!-- 结束节点的开始事件 --> 21 <on event="start"> 22 <event-listener class="com.kdyzm.event.EndNodeStartListener"></event-listener> 23 </on> 24 </end> 25 <task name="task1" g="499,224,92,52"> 26 <!-- 任务节点的开始事件 --> 27 <on event="start"> 28 <event-listener class="com.kdyzm.event.TaskNodeStartListener"></event-listener> 29 </on> 30 <!-- 任务节点的结束事件 --> 31 <on event="end"> 32 <event-listener class="com.kdyzm.event.TaskNodeEndListener"></event-listener> 33 </on> 34 <transition name="to end1" to="end1" g="-50,-22"/> 35 </task> 36 </process>
需要注意的是每一个事件对象都需要实现一个接口:EventListener,以开始节点结束事件为例:
1 import org.jbpm.api.listener.EventListener; 2 import org.jbpm.api.listener.EventListenerExecution; 3 4 /** 5 * start节点结束的时候触发 6 * @author kdyzm 7 * 8 */ 9 public class StartNodEndListener implements EventListener{ 10 private static final long serialVersionUID = -4132312517428245180L; 11 12 @Override 13 public void notify(EventListenerExecution execution) throws Exception { 14 System.out.println("Start 节点结束!"); 15 } 16 17 }
可以在重写的方法中实现想要处理的功能,这里只是打印了一句话表示表示而已。
JBPM基础只有这些,下一篇是JBPM的项目小练习。